本文推出了 ABot-PhysWorld,一个拥有 14B 参数的交互式机器人世界基础模型(World Foundation Model)。该模型基于 Diffusion Transformer (DiT) 架构,通过大规模具身数据治理、物理偏好对齐(DPO)及空间动作注入技术,实现了具备物理真实感、视觉高度写实且动作可控的机器人操纵视频生成,在 PBench 和新提出的 EZSbench 上均达到 SOTA。
TL;DR
阿里巴巴 AMAP CV Lab 近期发布了 ABot-PhysWorld,这是一个拥有 140 亿参数的扩散变换器(Diffusion Transformer)模型。它不仅能生成好莱坞级别的机器人操纵视频,更重要的是,它通过一种创新的物理对齐技术(Diffusion-DPO),解决了 AI 生成视频中长期存在的“物体穿模”和“反重力”等违背物理常识的问题。此外,它能在零预训练的情况下,通过空间动作注入,精准控制不同型号机器人的抓取与放置动作。
核心定位:从“视觉模拟”到“物理仿真”
当前的视频模型(如 Sora 或 Veo)更像是出色的“画家”,它们擅长模仿像素的流动,却不理解背后的物理因果。在具身智能(Embodied AI)领域,如果世界模型预测的未来是错误的(如夹爪直接穿过了杯子),那么基于此进行规划的机器人将永远无法在现实中成功。
ABot-PhysWorld 的出现,标志着世界模型从像素对齐向物理定律对齐的范式转移。
痛点深挖:为什么世界模型总爱“穿模”?
- 数据分布的贫瘠:通用视频数据集(如 YouTube)中,机器人操纵物体的精细交互极少,模型无法学习到诸如摩擦力、碰撞反馈和质量分布等动力学特性。
- 训练目标的缺陷:传统的 SFT 训练中使用最大似然估计,它平等地对待每一个像素误差。对于模型来说,夹爪在杯子外 1 厘米和穿透杯子 1 厘米的“损失值”可能是相似的,但在物理逻辑上,前者是正确的,后者是灾难性的。
核心方法论:物理对齐与动作图谱
1. 物理偏好对齐 (Physics-Aware DPO)
为了纠正非物理行为,作者引入了 Diffusion-DPO。其核心逻辑在于:
- 解耦判别器:使用 Qwen3-VL 充当“出题人”,针对每个视频生成专门的物理清单(如:夹爪是否穿透了苹果?苹果是否像磁铁一样贴在手上?);由 Gemini 3 Pro 充当“评卷人”,根据清单生成的对比组(yw 为物理正确,yl 为物理违背)。
- 偏好对齐:在潜空间内,通过 DPO 损失函数,主动拉大模型对物理正确样本与错误样本的预测差异,从底层逻辑上让模型知道“穿模是不可接受的”。
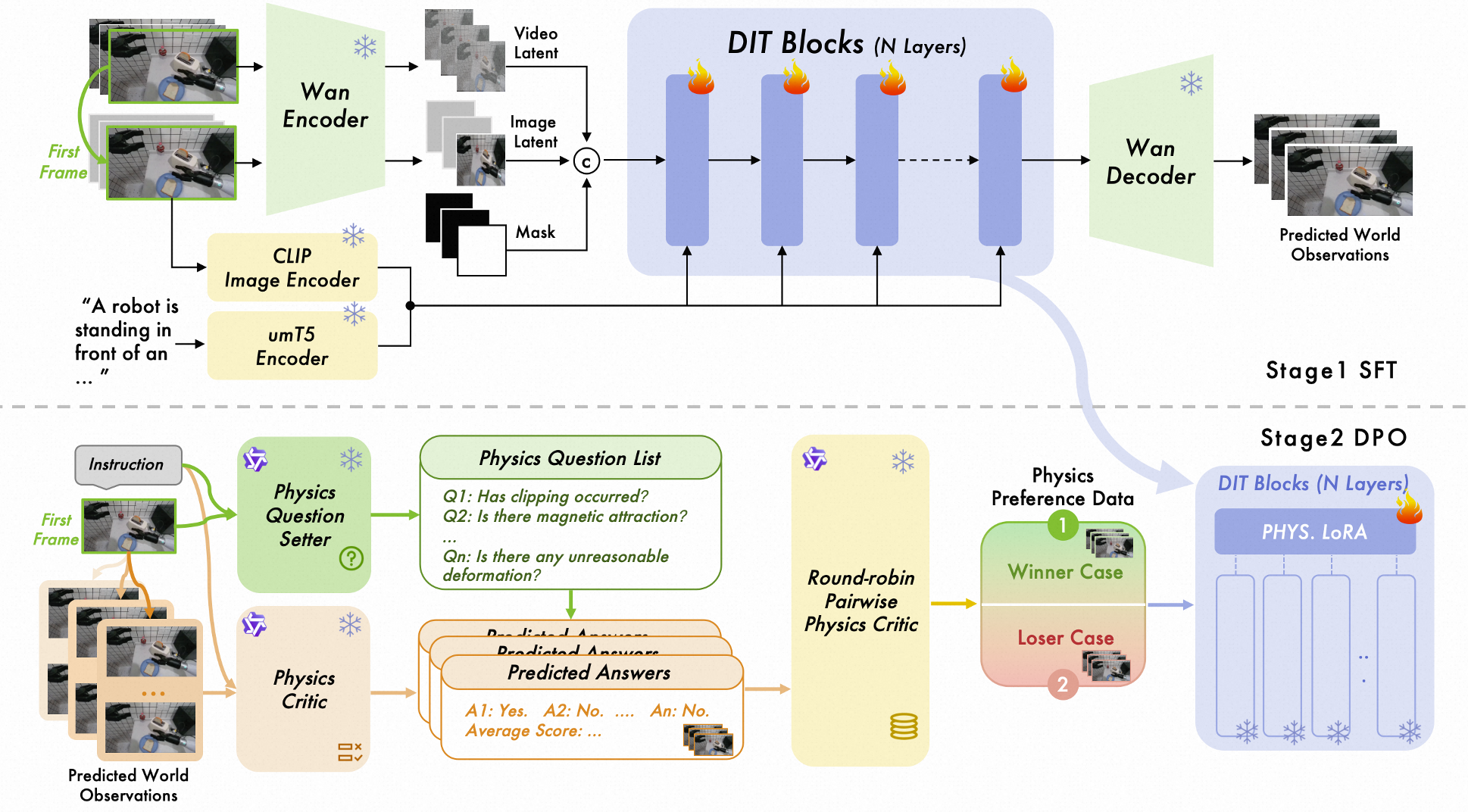 图 1:ABot-PhysWorld 的两阶段训练:SFT 建立视觉基础,DPO 实现物理对齐。
图 1:ABot-PhysWorld 的两阶段训练:SFT 建立视觉基础,DPO 实现物理对齐。
2. 空间动作注入 (Spatial Action Injection)
如何让模型听懂“向上移动 5 厘米”的指令?ABot-PhysWorld 将 7 维动作向量(位置、姿态、夹爪开合)映射为带有颜色和透明度编码的 2D 动作图 (Action Map)。
- 平行上下文块 (Parallel Context Blocks):模型并不是强行改变原来的 backbone 权重,而是克隆了一部分 DiT 块作为旁路,专门处理这些动作图。这种设计保证了模型在学习“控制”的同时,不会忘记原本学到的“物理常识”。
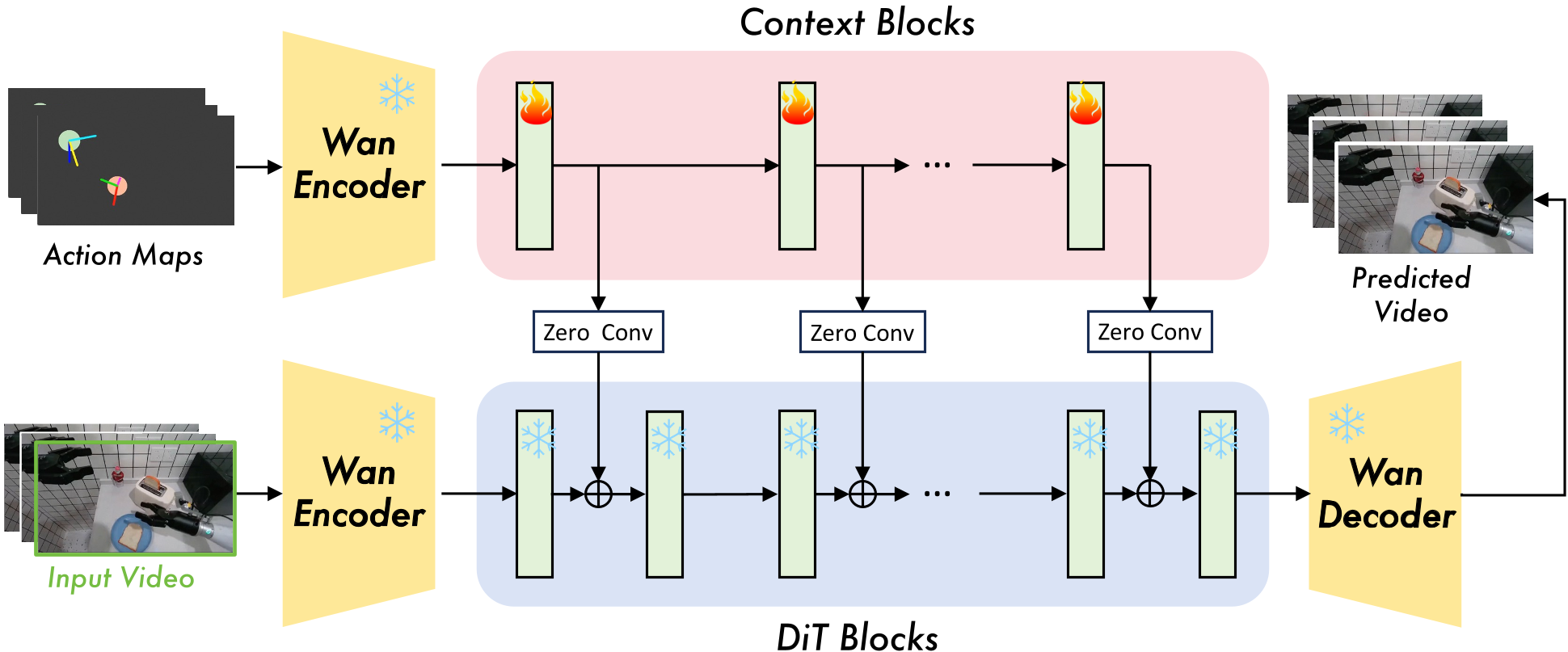 图 2:动作条件生成架构,通过平行分支实现精准的空间控制。
图 2:动作条件生成架构,通过平行分支实现精准的空间控制。
实验与结果:刷新物理一致性的天花板
在 PBench(一个专门针对物理 AI 的基准)上,ABot-PhysWorld 表现出了统治力:
- 物理域得分 (Domain Score):达到了惊人的 0.9306,作为对比,目前公认最强之一的 Sora v2 Pro 仅为 0.7626。
- 定性对比:在处理密集的接触交互时(如从杂乱的桌面抓取物品),其他模型经常出现夹爪变形或目标识别错误,而 ABot-PhysWorld 能够保持稳定的时空一致性。
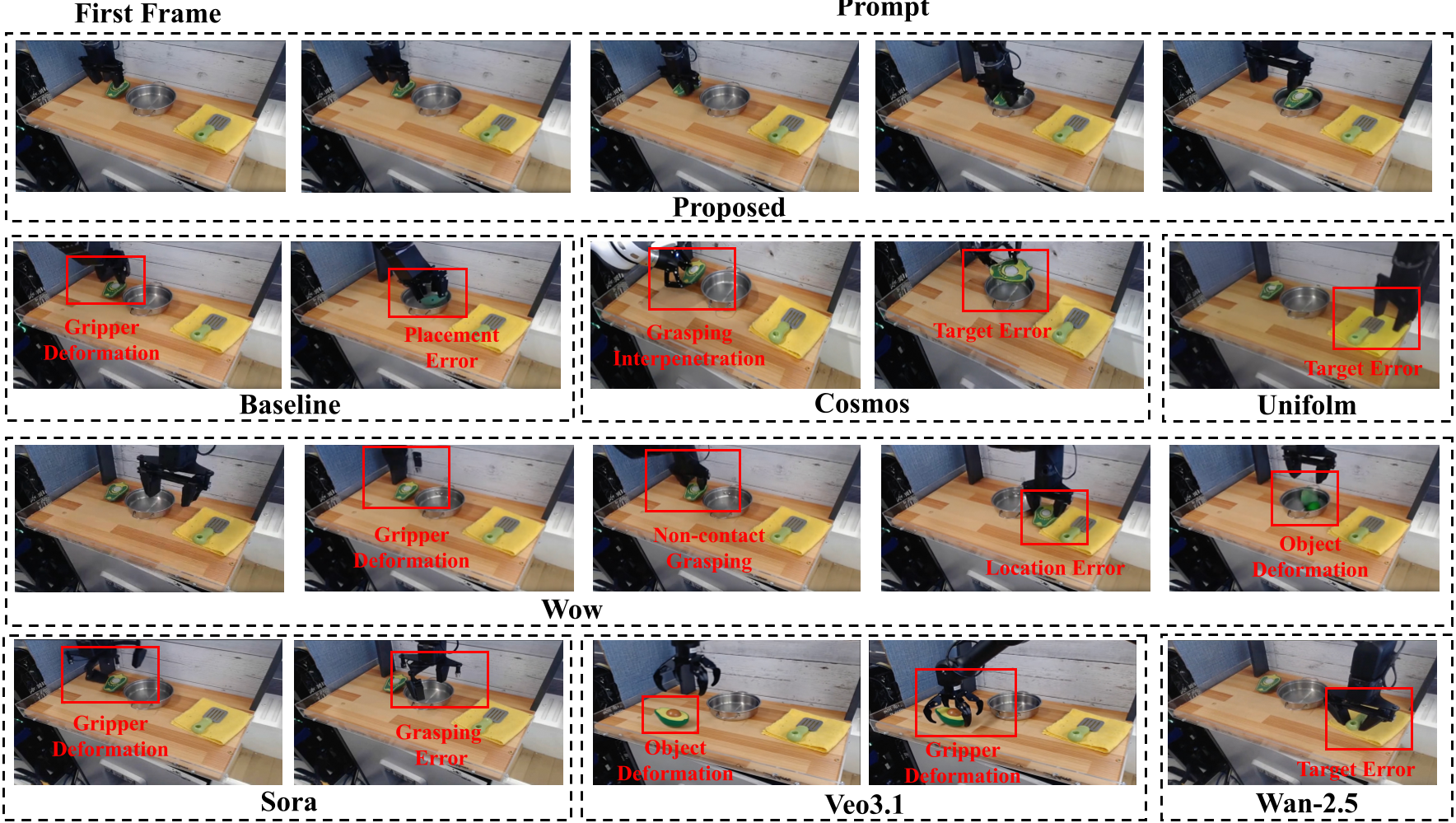 图 3:PAI-Bench 定性对比,展示了模型在处理接触、几何保持和目标识别上的优势。
图 3:PAI-Bench 定性对比,展示了模型在处理接触、几何保持和目标识别上的优势。
此外,作者推出的 EZSbench 是首个针对具身智能的零样本基准。在从未见过的机器人形态和陌生场景下,ABot-PhysWorld 依然展现了 SOTA 的生成质量,这对于未来开发通用型机器人(General-Purpose Robots)具有巨大的价值。
深度洞察:未来已来
ABot-PhysWorld 不仅仅是一个视频生成器,它是一个可交互的仿真平台。通过动作图注入,研究者可以像“拨动钢琴键”一样输入动作序列,观察模型预测的物理反馈。这种“生成即仿真”的范式,极大地降低了机器人策略训练时对昂贵物理引擎和真实数据采集的依赖。
总结 (Takeaway):该研究最深刻的贡献在于,它提供了一套完整的“物理对齐”工业流:从差异化的数据平衡、到基于 VLM 的自动化物理评审、再到 Diffusion-DPO 优化。这为构建更高阶、更真实的具身模拟器指明了方向。
注:文中公式(1)定义的 $\mathcal{L}_{DPO}$ 是模型成功的数学核心,它通过控制 $\beta$ 参数调节了生成分布向物理正确分布的迁移。