本文提出了 Action Draft-and-Verify (ADV),一种为视觉-语言-动作 (VLA) 模型设计的自验证推理框架。该方法利用扩散动作专家并行生成多个候选动作块(Draft),再通过 VLM 的 perplexity 指数进行单次前向推理评分并择优(Verify),在维持高精度控制的同时显著增强了模型在分布外场景下的鲁棒性。
TL;DR
传统的 Vision-Language-Action (VLA) 模型在面对陌生环境(OOD)时往往像无头苍蝇:扩散模型生成的动作虽精细但缺乏逻辑,自回归模型逻辑在线但精度堪忧。本文提出 Action Draft-and-Verify (ADV) 框架,让扩散专家“打草稿”,VLM 负责“审核”。相比纯扩散基线,该方法在真实世界任务中成功率飙升 19.7%,且推理开销极低。
核心速览:谁说大模型只能做决策?
文章开篇指出,当前的 VLA 领域存在一个有趣的矛盾:
- Diffusion Expert(如 π0):擅长生成平滑、高精度的连续动作,但在面对训练集没见过的场景时,容易产生无意义的抖动。
- Auto-Regressive VLM(如 RT-2):具备强大的语义先验,知道“拿不稳就要重试”,但生成长序列动作太慢。
ADV 框架 的核心直觉是:不需要让 VLM 去费力生成每一个动作,只需要让它在扩散模型给出的数十个备选方案中,选出那个“看起来最顺眼”的即可。
痛点深挖:扩散模型的“迷茫”
作者在 RoboTwin2.0 实验中观察到,在分布外(OOD)环境下,扩散模型由于缺乏结构化的泛化能力,其“恢复尝试(Recovery Attempts)”次数从 4.5 骤降至 0.4。这意味着一旦第一次抓取失败,机器人就彻底“摆烂”了。而自回归模型依然能保持纠错逻辑。
方法论详解:Textual FAST 与 Perplexity 验证
ADV 的工作流分为两步:
- Draft(草拟):扩散专家根据 VLM 提供的特征,通过不同的噪声注入生成 个候选轨迹。
- Verify(验证):这是本文的神来之笔。作者提出 Textual FAST 动作编码方法。
- 首先用 FAST 算法压缩动作。
- 然后将编码翻译成纯文本。
- 最后利用训练好的 VLM 在一个 Forward Pass 内计算这些文本序列的 Perplexity(困惑度分数)。
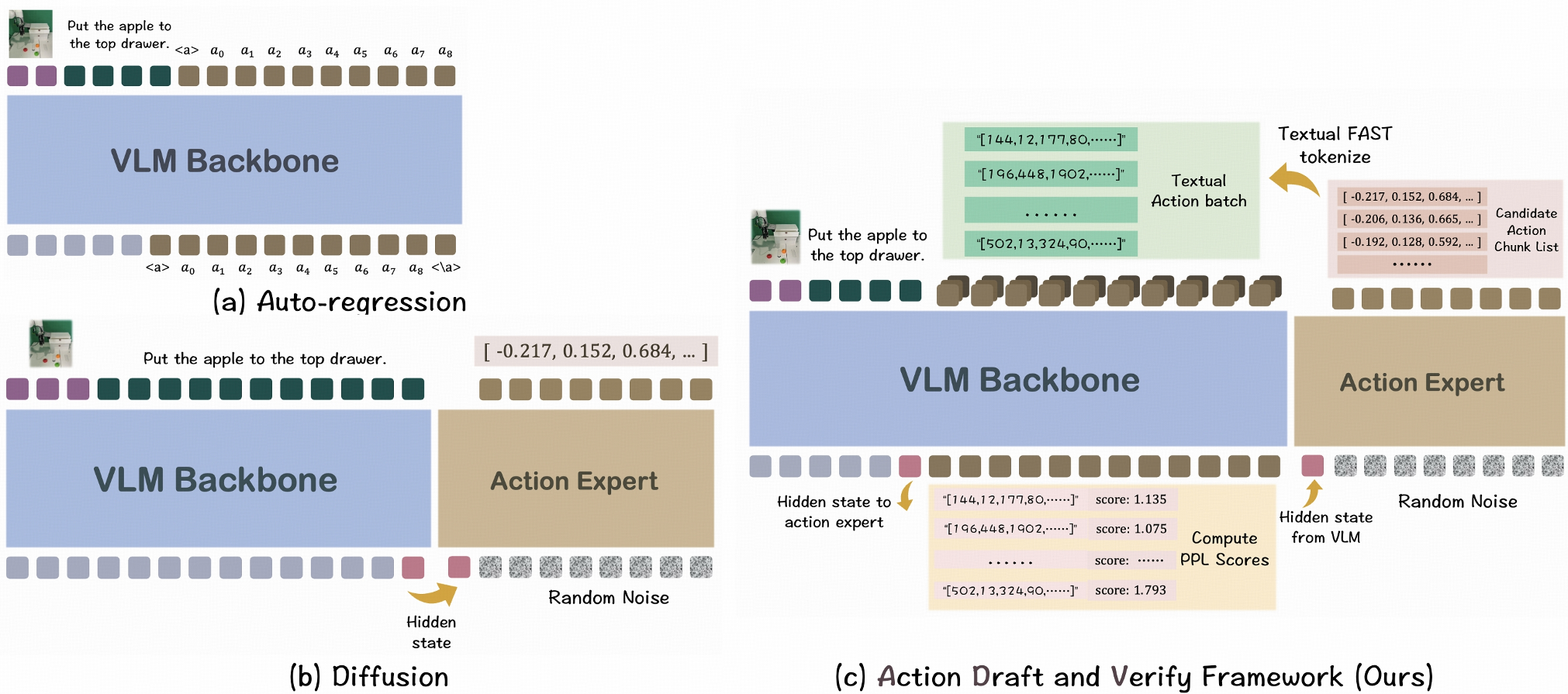
为何有效? 因为 Textual FAST 将动作表示为了“类语言”形式,这与 VLM 在海量互联网文本上训练出的分布高度重合,使得 VLM 能够利用其内在的“物理常识”来剔除那些不符合逻辑的动作块(如穿模、空抓)。
实验与结果:真实的救火队员
在 LIBERO 和 RoboTwin 仿真中,ADV 表现优异。但最令人印象深刻的是在 Real-World 实验中:
- 通用性:该方法适用于 Qwen2.5-VL, InternVL3.5 等多种主流模型。
- 稳定性:在机器人抓取任务中,ADV 将碰撞率从 29.7% 压制到了极低水平。

消融实验进一步证明,ADV 并不要求 VLM 选出“全球第一”的动作,只要能剔除掉那些最离谱的“败笔轨迹”,整系统的鲁棒性就会出现质的飞跃。
深度洞察与总结
Takeaway: ADV 证明了“解码即选择(Decoding-as-selection)”在具身智能中的有效性。它不改变扩散模型底层的生产能力,而是通过引入一个“裁判”来兜底。
局限性:
- 受限库:如果扩散专家提出的所有草案(Drafts)都是错的,VLM 也无能为力。
- 时延:虽然单次前向评分很快,但生成多个候选块并评分仍会增加一定的推理毫秒数。
未来展望:这种“草稿+审核”的模式极大降低了对 VLA 数据量的依赖,未来或许可以作为通用 VLM 适配各种专项动作机器人的统一中间件。