本文提出了 RLCF(社区反馈强化学习)框架,旨在提升 AI 的“科学品味”(Scientific Taste),即判断和提出高潜力研究想法的能力。通过在 70 万对由引用量匹配的论文摘要上进行偏好建模,训练出了具备极强学术判断力的 Scientific Judge,并以此为奖励模型训练出能够自主生成高价值科研建议的 Scientific Thinker。
TL;DR
顶尖科学家之所以卓越,不仅在于他们卓越的执行力,更在于他们敏锐的科学品味 (Scientific Taste) —— 即一眼看穿哪个研究方向才是“大坑”,哪个方向具有改变世界的潜力。复旦大学、OpenMOSS 团队等联合发布的这篇论文,首次通过 RLCF (Reinforcement Learning from Community Feedback) 范式,证明了 AI 可以通过大规模社区反馈信号(如引用量)学习这种高阶审美,并在科研方案判别与自主立项(Ideation)上达到了超越 GPT-5.2 的水平。
核心速览:AI 的“审美觉醒”
在过去的一年里,我们见证了 AI 在文献阅读和自动化实验上的突飞猛进。然而,AI 始终像是一个高级“实验员”,而非“科学家”。本文提出的 Scientific Judge 和 Scientific Thinker 系统,标志着 AI 正在跨越从“搬砖”到“决策”的鸿沟。
痛点深挖:引用量背后的“群体直觉”
为什么 AI 很难拥有科学品味?
- 主观性难题:好想法的标准在不同人眼中千差万别。
- 数据稀缺性:顶尖科学家的决策过程极少被公开记录。
- RLHF 的局限:雇佣标注员给专业论文打分既昂贵又不专业,无法代表科学界的整体共识。
作者给出的 Insight 非常深刻:引用量不仅是数字,它是科学社区通过长期交互、验证后达成的“群体共识”(Sensus Communis)。 这种信号天然地包含了对“潜在影响力”的认可。
方法论详解:RLCF 训练全流程
1. 构建 SciJudgeBench
作者从 210 万篇 arXiv 论文中精选了 70 万对“论文双胞胎”。每一对论文必须满足:领域相同、发表时间接近,但引用量存在显著差异。这消除了领域热度和时间沉淀的偏差,逼迫模型学习标题和摘要背后的“干货”含量。
2. Scientific Judge:学术裁判的进化
通过 GRPO (Group Relative Policy Optimization) 算法,模型在对比两篇论文时,不仅要给出答案,还要输出 思维链(CoT) 进行推理阐述。
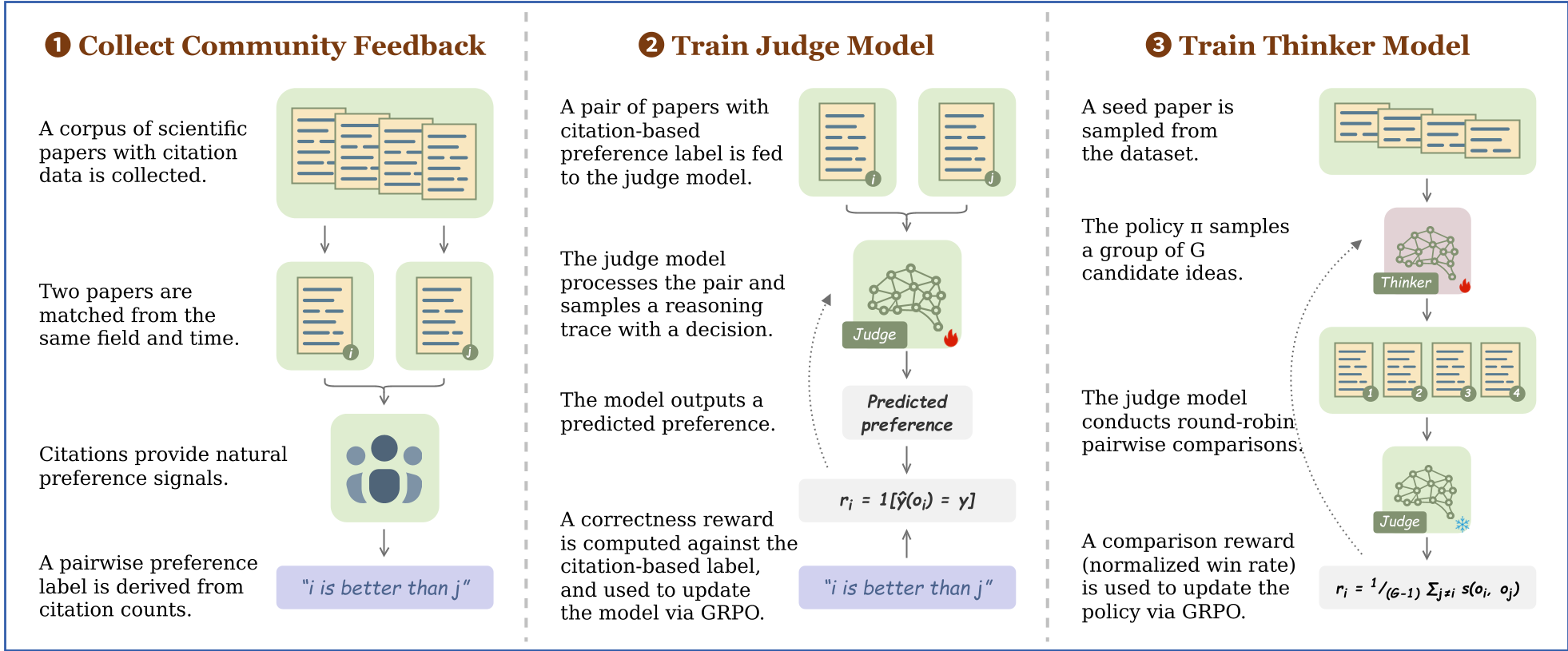
3. Scientific Thinker:在对弈中产生灵感
有了裁判后,如何训练“思考者”提出好想法?作者设计了 基于对比的 GRPO。
- 给定一个种子论文(Seed Paper),模型生成 8 个不同的后续研究思路。
- 裁判模型对这 8 个思路进行“循环赛”对比,计算每个思路的胜率。
- 胜率越高,奖励(Reward)越高,从而引导模型学会在复杂的科研空间中寻找“高胜率”的方向。
实验与结果:全方位的降维打击
判断力:超越人类顶级模型
在 SciJudgeBench 榜单上,Scientific Judge (30B 版本) 的准确率稳步超越了 GPT-5.2、Gemini 3 Pro 等一众商业巨头。更惊人的是其泛化性:即便是在模型从未见过的 2025 年新论文或物理/数学等交叉领域,它的判断准度依然在线。
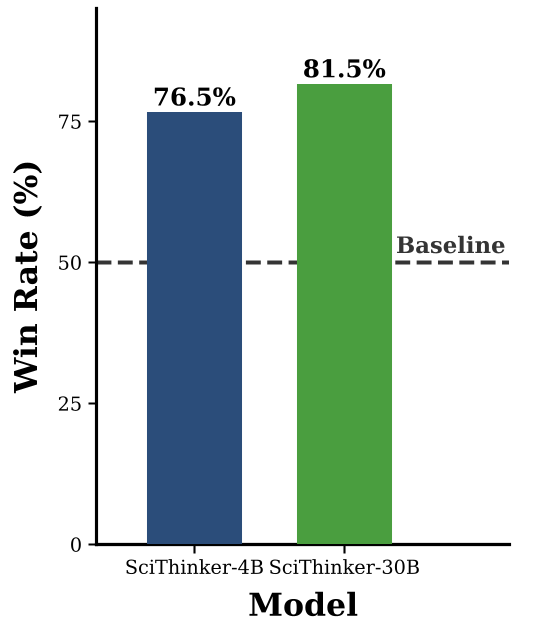
启发力:更具潜力的科研思路
在“立项”测试中,模型生成的思路被 GPT-5.2 等权威模型评价为更有学术前景。在 30B 规模下,Scientific Thinker 提出的建议在 54.2% 的情况下被认为优于商业 SOTA 模型,成功突破了 LLM 只能产生“平庸陈旧想法”的魔咒。
深度洞察:科研的未来演进
1. 科学品味是可以工程化的
这项研究最重大的意义在于,它将虚无缥缈的“科学眼光”转化为一个偏好对齐问题。这意味着随着学术文献数据的持续积累,AI 的“科研审美”将不断自我迭代。
2. 局限性与挑战
作者坦诚指出,引用量并非完美指标(存在马太效应或引用操纵),且目前的 ideation 尚未经过实验验证。未来如果能将实验可行性(Feasibility)也纳入 RLCF 框架,AI 处理科研任务的完整度将不可限量。
3. 启示
对于研究者而言,这篇论文提供了一个全新的工具:在开题之前,或许可以让 Scientific Judge 帮你“审一审”,看看你的 Idea 是否具备成为未来 Top-cited 论文的潜质。
总结 (Takeaway):本文通过 RLCF 范式,成功让 AI 获取了稀缺的“科学品味”,这不仅是 AI 助力科学发现(AI4Science)的一大步,更是通往人类水平 AI 科学家的关键里程碑。