本文提出了一个名为 War-Forecast-Arena 的时间对齐案例研究,旨在评估大语言模型(LLM)在“战争迷雾”下的实时地缘政治推理能力。通过模拟 2026 年中东冲突的 11 个关键时间节点,研究验证了 SOTA 模型在处理未见过的、高度不确定的冲突演变时的战略直觉与叙事演化。
TL;DR
如果 AI 面对一场尚未被载入史册、正在实时发生的战争,它能否像资深分析师一样拨开迷雾?本文通过 2026 年爆发的(假设性)中东冲突,在严格杜绝“后见之明”的前提下,对 GPT-5.4、Claude 4.6 等顶级模型进行了实战演习。研究发现,AI 已经摆脱了简单的辞令复述,展现出对军事沉没成本和供应链联动的深刻理解。
背景定位
在地缘政治风险分析中,我们常遇到的问题是模型在“马后炮”。因为历史事件早已存在于训练数据中,AI 实际上是在进行“记忆检索”而非“推演推理”。这篇论文是一个严谨的探测性研究,它建立了一个完全避开了所有 SOTA 模型 Cut-off Date(训练截止日期)的动态实验场。
核心动机:挑战“战争迷雾”
克劳塞维茨在《战争论》中提到,战争中四分之三的因素都包裹在某种不确定性的迷雾中。作者认为,评估 LLM 能力的终极考验,不是看它能多准确地复述二战,而是看它在面对突发危机时,如何处理以下痛点:
- 局部观察:只能看到 T 时刻之前的碎片化新闻。
- 信息噪声:充满了各种外交烟雾弹和恐吓性修辞。
- 多主体博弈:多国参与、利益碰撞、代理人战争的复杂结构。
方法论详解:时间接地的动态推演
作者不仅是给模型扔一段文字,而是设计了一套交互式协议:
- 11 个时间节点 (T0-T10):从最初的军事行动爆发,到石油设施受袭,再到领导层更迭。
- 原始资讯流 (Context Corpus):模型每次都会吃到约 12 万 token 的原始报道(来自路透社、半岛电视台等 12 家媒体),其中不乏冗余和相互矛盾的信息。
- 概率预测与叙事记录:不仅要求模型给出“会/不会”的概率,更要求其写出背后的推理路径。
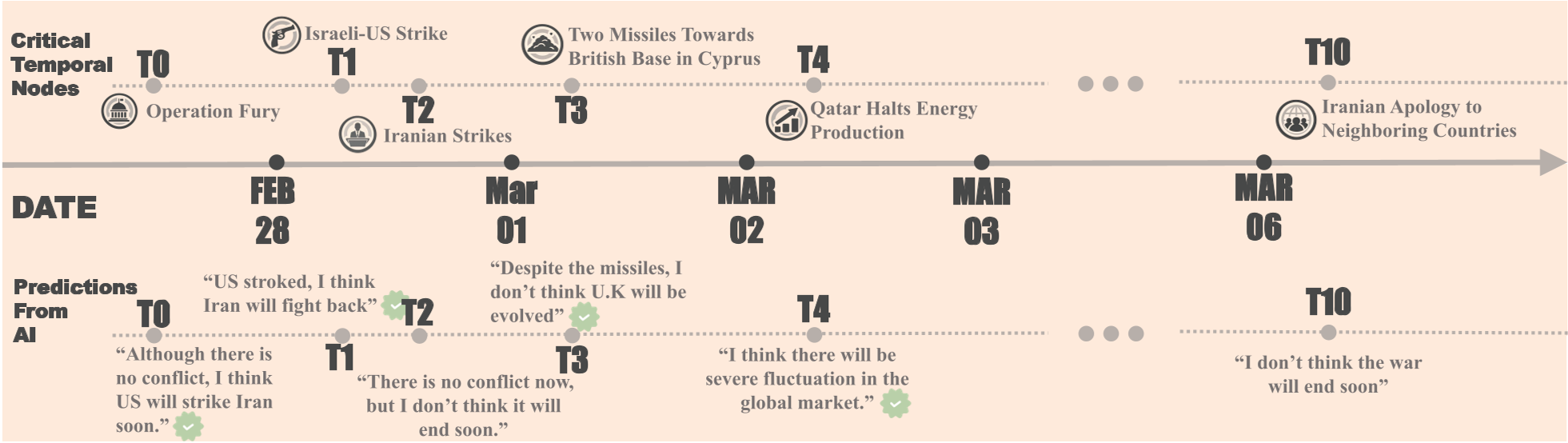 (图 1:2026 年冲突的关键时间节点及模型的分析演进示例)
(图 1:2026 年冲突的关键时间节点及模型的分析演进示例)
深度洞察:AI 真的懂地缘政治吗?
1. 识破“信誉陷阱”与军事惯性
在 T0 节点(美军大规模部署但尚未开火时),GPT-5.4 和 Claude 4.6 敏锐地指出:这种规模的部署已经造成了战略沉没成本。AI 意识到,如果美国此时撤军而不获得重大让步,将面临毁灭性的信誉损失。这种“身不由己”的博弈逻辑,反映了模型对地缘政治 Inductive Bias(归纳偏置)的掌握。
2. 不同领域的差异化表现
数据揭露了一个有趣的现象:模型在“算账”时比“猜心”更准。
- 经济联动(Theme III,Avg 0.79):模型能清晰推导出霍尔木兹海峡封锁如何导致保险费暴涨,进而引发全球航运的“事实性封锁”。
- 政治信号(Theme IV,Avg 0.67):面对领导层突然更迭或外交道歉,模型的一致性大幅下降。它们往往在判断“新领导人是会采取强硬姿态立威,还是会寻求妥协”这一人性不确定性上感到困惑。
 (表 8:模型在不同主题下的预测对齐得分对比)
(表 8:模型在不同主题下的预测对齐得分对比)
3. 叙事的演化趋势
研究记录了模型“心态”的转变:
- 初期:倾向于认为冲突会快速遏制。
- 中期:开始关注“全球化地域战争(Globalized Regional War)”的概念——即便没有三战,全球供应链的断裂也具有等同的破坏力。
- 末期:在领导层被“斩首”后,模型警告这种行动未必带来和平,反而可能因“马赛克教条(Mosaic Doctrine)”导致基层军队失控。
实验总结与未来展望
这项工作最大的贡献在于存档了 AI 推理的快照。在冲突结束前,没有所谓的“标准答案”,只有推演的逻辑。
局限性:
- 实验基于模拟的或正在发生的事件,真实性受限于 Context 内容的偏见。
- 模型对极端非理性行为(如独裁者的个人孤注一掷)的预测仍不如经验丰富的人类分析师。
价值: 它证明了 LLM 在处理Real-time Uncertainty方面的巨大跃迁。未来的地缘政治预警系统,或许不再由单一的规则库组成,而是一群能够 24/7 读取全球情报流、随时更正自己“战争叙事”的 AI 特约分析师。
本文基于 arXiv 2026 同名论文解读,旨在探讨 AI 推理边界。