本文提出了 AI Scientist 框架,通过合成任务缩放(Synthetic Task Scaling)来训练能够自主进行机器学习研究的 AI 代理。该系统自动生成 500 个与 SWE-agent 兼容的 ML 任务并利用 GPT-5 生成 3 万余条专家轨迹,在 MLGym 基准测试中显著提升了 Qwen3 模型的科研实操能力。
TL;DR
未来的 AI 科学家可能不是从图书馆(静态语料)中产生的,而是在实验室(可执行环境)里“练”出来的。普林斯顿与微软研究院提出的这篇论文,通过自动化合成 500 个机器学习任务和 3.4 万条科研轨迹,成功让中轻量级模型 Qwen3 在 MLGym 复杂科研任务中性能突破了 12%。
1. 科研 AI 的瓶颈:只会说,不会做
目前的 LLM 已经阅读了几乎所有的机器学习文献,但在面对真实的科研挑战时,它们往往表现得像个“赵括”:
- 想法虚浮:提出的算法思路在数学上看似合理,但实操时由于环境配置或维度匹配等低级错误无法运行。
- 缺乏迭代直觉:科研的本质是迭代(Debug -> Re-run -> Analyze)。现有的模型训练由于缺乏这种轨迹数据,导致 Agent 在第一次运行失败后往往束手无策。
为了解决这一痛点,作者提出了 Synthetic Task Scaling:如果现实中没有足够的科研过程数据,我们就用 AI 自动合成一个科研“练兵场”。
2. 核心方法:高度仿真的合成科研流水线
该研究的核心在于如何自动生成既具有挑战性又切实可用的 ML 任务。流程分为三个关键阶段:
Phase 1: 环境合成 (Environment Synthesis)
系统不再依赖人工设计,而是自动从 1000 个 ML 话题中采样,并调用 HuggingFace API 寻找真实的观察数据集。如果 AI 提议了一个不存在的数据集,系统会自动丢弃该任务,确保所有合成任务都“脚踏实地”。
Phase 2: 自调试验证 (Self-debugging Loop)
这是本文的 Insight 所在:生成的代码如果不能运行怎么办?系统引入了 Self-debugging 机制。GPT-5 会作为环境验证员先跑一遍,如果报错,会将错误反馈给生成模块进行修正,直到任务达到“可解状态”。
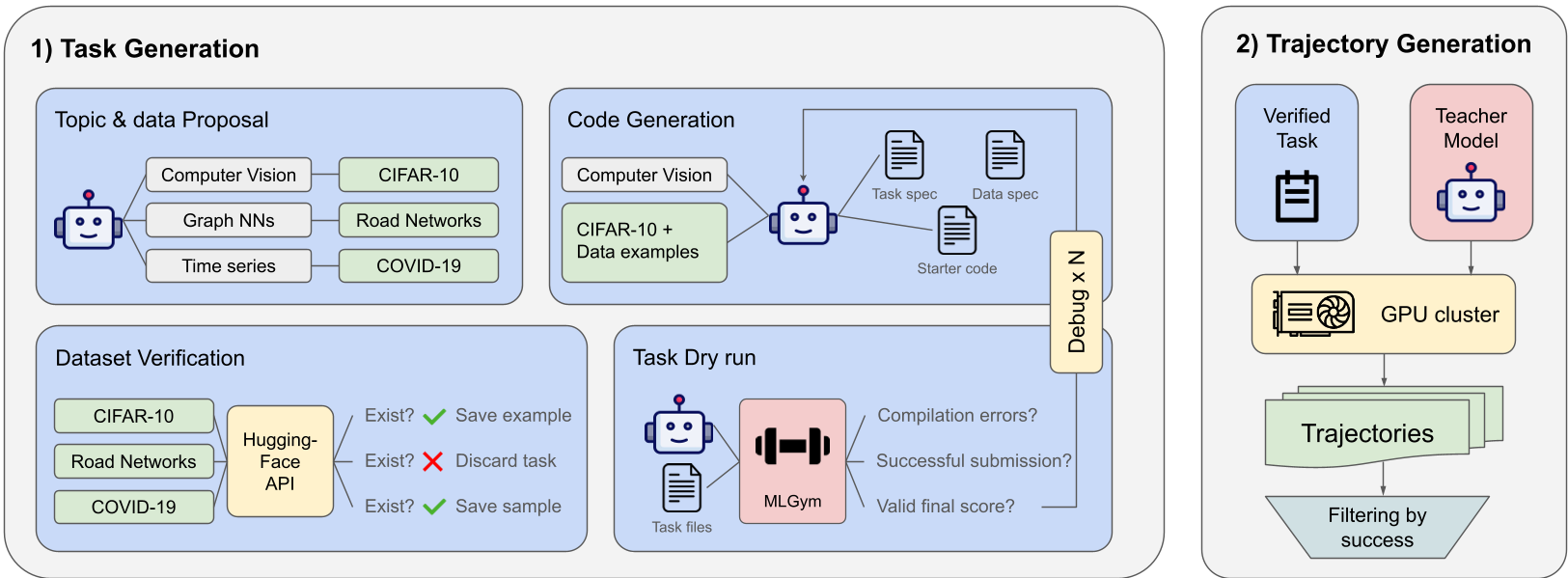 Figure 1: 自动化任务生成与轨迹采样工作流,核心是无需人工干预的闭环验证。
Figure 1: 自动化任务生成与轨迹采样工作流,核心是无需人工干预的闭环验证。
Phase 3: 教师轨迹采样
利用 GPT-5 作为“导师”,在生成的 500 个任务中进行探索。这些探索过程(包括修改代码、运行 Bash 命令、分析 Loss 曲线)被记录为 34,000 条轨迹。
3. 实验战果:小模型的大飞跃
研究者使用 Qwen3-4B 和 8B 作为学生模型,在这些合成的轨迹上进行 SFT (Supervised Fine-tuning)。
关键结果分析:
- 整体提升:Qwen3-8B 在 MLGym 上的 AUP 分数提升了 12%。
- 任务覆盖:在 13 选 9 的任务中,经过 SFT 的模型全面超越了原始基线,尤其是在需要多步逻辑推理的复杂 ML 任务中。
- 长文本处理:训练轨迹的平均长度达到 2.2 万 Token,这锻炼了 Agent 处理长程依赖科研任务的能力。
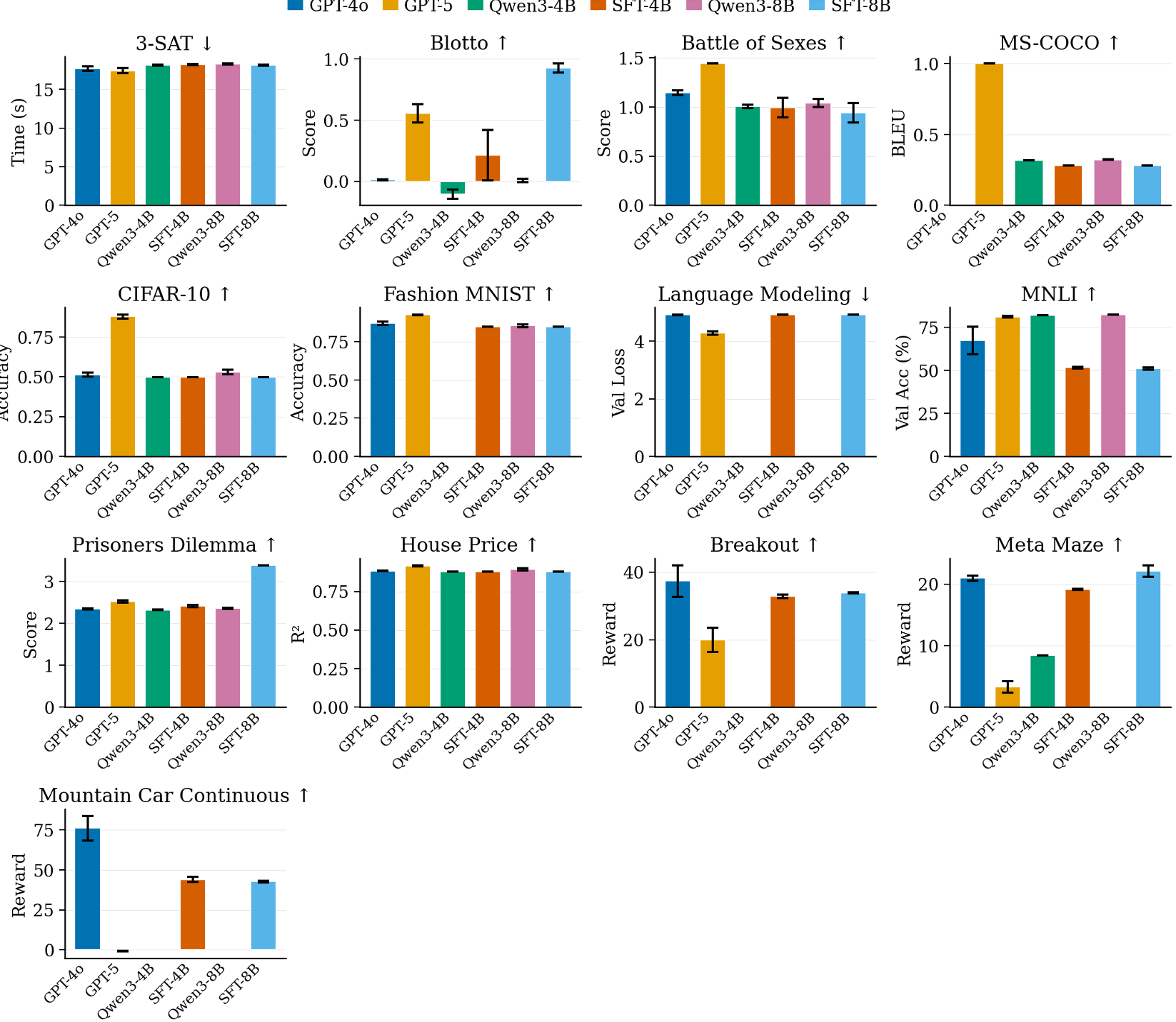 Figure 2: 经过 SFT 后的模型(紫色)在多数 MLGym 子任务上显著优于原始基线(蓝色)。
Figure 2: 经过 SFT 后的模型(紫色)在多数 MLGym 子任务上显著优于原始基线(蓝色)。
4. 深度洞察:为什么这种方法有效?
这篇论文体现了 经验缩放 (Experience Scaling) 的威力。
- Inductive Bias 的纠偏:通过直接在 SWE-agent 这种命令行交互环境里训练,Agent 学会了如何正确使用
sed修改代码,以及如何从traceback中定位 Bug。 - 多样性补偿:虽然只有 13 个测试任务,但训练集涵盖了从图像分类到强化学习的 500 个不同领域,这种广泛的分布增强了模型的 Zero-shot 迁移能力。
5. 局限性与未来展望
尽管取得了显著提升,但作者也坦诚了目前的局限:
- 复杂代码瓶颈:对于像 MS-COCO 这种涉及复杂底层架构的任务,模型的提升有限。
- SFT 的天花板:SFT 只能让学生模仿教师,无法超越教师。作者指出,未来的方向必然是引入基于奖励生成的 强化学习 (RL),让 AI 真正发现连人类都没见过的算法。
总结 (Takeaway)
《AI Scientist via Synthetic Task Scaling》向我们展示了通往自主科研 AI 的一条务实路径:构造大规模、可执行、带反馈的合成任务。 当 AI 能够在大规模的虚拟实验中复现、调试并优化数万次机器学习过程时,它离真正的科学发现也就不远了。