本文提出了 TraceR1,一个针对多模态智能体(Multimodal Agents)的两阶段强化学习(RL)框架。该方法通过“预测未来轨迹”而非仅仅“反应式决策”,在 GUI 操作和工具调用任务中实现了显著的规划稳定性和执行鲁棒性,达到了与闭源 SOTA 模型相当的水平。
TL;DR
在自动驾驶中,人类司机不会只盯着引擎盖前面的几米,而是会观察远方的路况。然而,目前大多数 GUI 智能体(Agent)仍处于“看一步走一步”的原始阶段。Adobe 等机构的研究者提出了 TraceR1,通过两阶段强化学习训练,让 Agent 学会在执行前先“脑补”未来的动作轨迹,使其在长航程 GUI 任务中具备了类似人类的先验规划(Anticipatory Planning)能力。
背景定位:从“反应式”到“规划式”
当前的视觉语言模型(VLM)虽然在理解屏幕截图上表现出色,但在处理需要几十步操作的任务(如:在 Android 手机上跨 App 订机票)时经常“翻车”。
原因在于:
- 反应式陷阱:模型仅依据当前帧做出决策(Reactive),忽略了动作之间的长程依赖关系。
- 误差累积:一步操作失误(如点击了错误的菜单)会导致后续所有规划崩盘。
- 世界模型构建难:在视觉交互环境中,让模型精准预测下一帧的像素级变化(World Model)成本极高。
核心动机:TraceR1 的“先知”直觉
TraceR1 的核心 Insight 是:既然预测像素很难,那我们就预测“动作轨迹”的 Skeleton(骨架)。
模型在每一步执行前,不仅仅生成当前要做的操作,还要预测未来 N 步的动作序列。这种“前瞻性”(Anticipatory)的设计可以强迫模型考虑每一步动作对实现长远目标的影响。
方法论详解:两阶段 RL 框架
TraceR1 的训练流程被精妙地解构为两个阶段,协同解决“想得远”和“做得准”的问题:
第一阶段:前瞻性轨迹优化 (Anticipatory Trajectory Optimization)
- 目标:解决“全局一致性”问题。
- 方法:模型预测一个短航程的未来轨迹 $\hat{ au}$。研究者使用了 GRPO(Group Relative Policy Optimization)算法,通过轨迹级的对齐奖励(Alignment Reward)来优化模型。
- 物理意义:这个阶段不关心点击的坐标是否精确到像素级,而是关心“逻辑对不对”。如果任务是发邮件,模型必须预测出“点击撰写 -> 输入地址 -> 点击发送”的整体逻辑流。
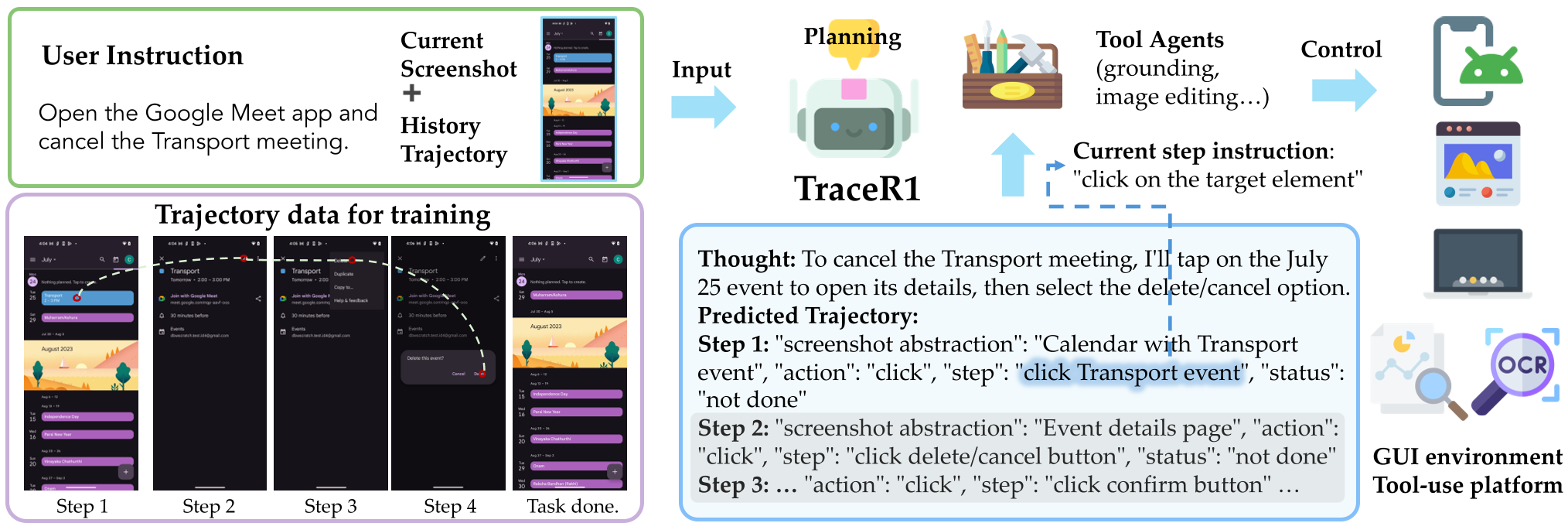
第二阶段:接地强化微调 (Grounded Reinforcement Fine-tuning)
- 目标:解决“执行精准度”问题。
- 方法:将预测的第一步动作放入实际环境或通过冻结的 Tool Agent(执行器)运行。根据执行反馈(例如:点击的坐标是否落在了正确的按钮上,或者调用计算器的结果是否正确)给予奖励 $r_G$。
- 物理意义:将第一阶段宏观的“战略规划”具象化为微观的“战术执行”。
实验结果:开源模型的逆袭
TraceR1 在多个 benchmark 上展示了惊人的跨越式提升:
- 桌面端 (OSWorld):在验证集上,它将 Qwen3-VL-32B 的成功率从 35.6% 提升到 41.2%,逼近了部分闭源专用 Agent 系统的水平。
- 移动端 (AndroidWorld):相比于仅仅做反应式训练的模型,TraceR1 在长路径任务上的稳定性有了质的飞跃。
- 复杂推理 (GAIA):TraceR1 甚至在 GAIA 榜单上取得了 40.2 的 AnsAcc,超越了强大的 GPT-4o,证明了当模型开始“提前思考”时,其逻辑推理的一致性显著增强。

深度洞察:为什么这种设计有效?
消融实验揭示了几个有趣的观点:
- Stage 2 的必要性:如果没有 Stage 2 的接地反馈,模型的规划会变得“过度乐观”——它会幻觉出一些不存在的按钮或者假设操作永远成功。
- 规划步长的平衡:预测步长 $T$ 不是越长越好。实验发现当 $T > 10$ 时,性能反而下降。这类似于人类:我们可以预判未来 3-5 步,但预判 20 步后的细节会导致由于不确定性增加而产生的逻辑噪音。
总结与局限
Takeaway:TraceR1 证明了训练模型去“想得远”本身就是一种强大的监督信号。这种两阶段 RL 策略为开源模型挑战闭源模型在 Agent 领域的统治地位提供了一条清晰的技术路径。
局限性:尽管 TraceR1 具备了前瞻能力,但它目前还不能实时根据环境的细微变化动态修正其“内部世界观”。未来的方向可能是将这种轨迹预测与显式的记忆模块(Memory)或层次化规划(Hierarchical Planning)相结合。
本文由资深学术技术主编重构。如需深入了解,请参考原论文《Anticipatory Planning for Multimodal AI Agents》。