本文提出了“梯度汇聚”(Gradient Sink, GS)概念,揭示了 Transformer 模型中注意力汇聚(Attention Sink, AS)与巨量激活(Massive Activation, MA)之间的因果链条。研究表明,在 Pre-norm 架构下,AS 会导致梯度在反向传播时高度集中于特定 Token,而 MA 则是模型为了通过 RMSNorm 抑制这种局部梯度压力而产生的自适应训练产物。
TL;DR
大语言模型中常见的“首 Token 注意力黑洞”(Attention Sinks)和“数值离群值”(Massive Activations)并非孤立存在。本文通过清华大学的研究发现:注意力汇聚在反向传播时诱发了恐怖的“梯度汇聚”(Gradient Sink),而模型为了不被巨大的梯度冲垮,被迫通过 RMSNorm “膨胀”激活值来压缩梯度。 作者提出的 V-scale 插件证明了:只要在反向传播时给梯度装个阀门,即使没有巨量激活,注意力汇聚依然能照常工作。
痛点深挖:为什么 LLMs 喜欢“大数值”?
在 Llama 等 Pre-norm 架构中,所有输入在进入 MLP 或 Attention 之前都会被 RMSNorm 标准化。理论上,模型只需关注向量的方向而非模值。然而,实验观测到首个 Token(Initial Token)往往拥有极高的激活模值(MA)。
前人认为 MA 是为了让 Softmax 产生 AS。但本文提出了反直觉的追问:如果 MA 只是为了实现 AS,那为什么要在标准化后的层里搞出这么大的离群值? 这种数值不稳定性给量化和推理带来了巨大挑战。
核心洞察:从“前向黑洞”到“反向巨浪”
作者认为,问题的根源在于反向传播的压力差。
- 梯度汇聚 (Gradient Sink):在因果掩码下,第 个 Token 会关注之前的 个 Token。这意味着在反向传播时,后面成千上万个 Token 的梯度都会通过注意力权重累积到前面的 Token(尤其是第一个 Token)上。
- 自适应防御机制:RMSNorm 有个特性——输入的模值越大,其反向传播时的梯度衰减越紧( 比例)。为了在深层网络中保持残差流的稳定,优化器“学会”了通过提升激活值模值来抵消梯度爆炸。
方法论详解:V-scale 梯度阀门
为了验证“梯度是真凶”这一猜想,作者设计了 V-scale。

策略:针对 Value 路径进行径向变换。
- 逻辑:由于 Sink Token 通常具有极小的初始 Value 模值,作者引入了一个变换 。
- 效果:对于模值大的 Token 几乎不改变(Identity);对于模值小的 Sink Token,在前向传播中它们本身贡献就小,但在反向传播中,这个变换会充当“梯度阀门”,极大地衰减回传给 Sink Token 的梯度。
关键公式(梯度路径分析): 通过 Theorem 1,作者证明了 受到注意力列权重 的显著缩放。这从数学上坐实了注意力权重越高,梯度压力越大的物理直觉。
实验与结果:完美的解耦
通过在 0.1B 和 0.3B 模型上的实验,作者观察到了惊人的现象:
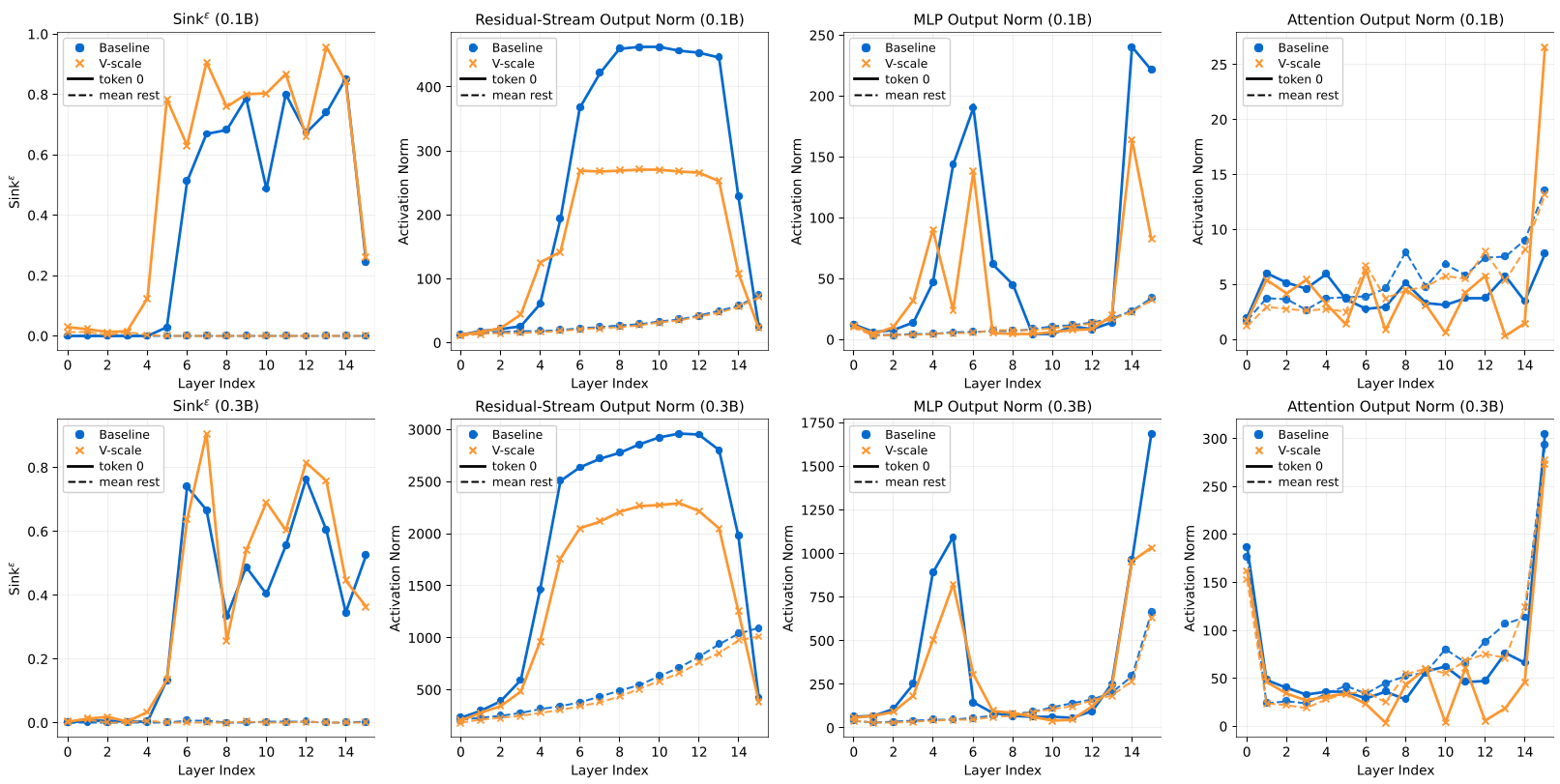
- AS 依然健在:V-scale 模型在首 Token 上的 Sink Rate 依然维持在高位,甚至有所加强。
- MA 消失了:相比 Baseline 明显的激活值尖峰,V-scale 模型的 MLP 输出和残差模值显著平滑。
- 性能不减:验证集 Loss 稳定,说明模型不再需要通过离群值来寻找优化平衡点。
深度洞察与总结
Takeaway:
- 因果倒置:巨量激活(MA)不是注意力汇聚(AS)的成因,而是伴随梯度汇聚(GS)产生的副作用。
- 架构启示:未来的 Transformer 改进不应只盯着前向传播的变体(如各种 Attention 变体),优化反向传播的梯度流(Gradient Regulation)可能是通向更稳定、易量化模型的捷径。
局限性: 目前实验主要集中在小规模 Llama 架构上,在大规模模型(如 70B+)以及 MoE 架构中,这种梯度平衡是否依然是 MA 产生的主导因素,仍需进一步验证。此外,V-scale 虽解决了数值离群值,但对长文本推理的 KV Cache 压缩效果还需下游任务的实测。