本文提出了 AKB-2000 评测基准,系统研究了纯文本预训练的大语言模型(LLM)中蕴含的听觉知识(Auditory Knowledge)。研究发现 LLM 的听觉储备与其被转化为大音视频语言模型(LALM)后的下游表现高度正相关,其中 Qwen 系列在听觉任务中显著优于 Llama。
TL;DR
在大型音视频语言模型(LALM)的研究中,大家习惯于把 Llama 或 Qwen 当成“黑盒”大脑。本文通过深入剖析 12 种主流 LLM 发现:LLM 对世界的听觉理解并非生而平等。通过作者提出的 AKB-2000 基准,我们发现 LLM 的文本表现与音频下游任务存在极强的正相关性,这为 LALM 的模型选型提供了科学依据。
1. 核心动机:LLM 懂多少“未曾听闻”的知识?
人类写下“小提琴的声音很温暖”或“警笛声由远及近变大”,LLM 在阅读海量文本时是否内化了这些物理世界的听觉直觉?
目前 LALM 的开发存在一个逻辑断层:大家在拼命优化音频编码器(Audio Encoder)和对齐层(Connector),却很少有人问——作为大脑的 LLM,本身是不是个“音痴”? 如果内核本身缺乏对音高、响度、甚至乐理的理解,即使对齐得再好,也无法完成高阶推理。
2. 三位一体的评测框架
作者构建了一个严密的实验矩阵,消除了架构和训练数据的干扰:
- AKB-2000 (Knowledge Probing):手动构建的 2000 个选择题,复盖 6 大类、48 个子类(从“猫和帽是不是押韵”到“复性噪声的频谱特性”)。
- Cascade Evaluation (Reasoning):音频 -> 文本描述符 -> LLM。测试 LLM 能否基于“听到的描述”进行逻辑处理。
- Audio-grounded Evaluation (Multimodal):统一将 8 种 LLM 用同一种配方(DeSTA 框架)练成 LALM,看谁的上限更高。
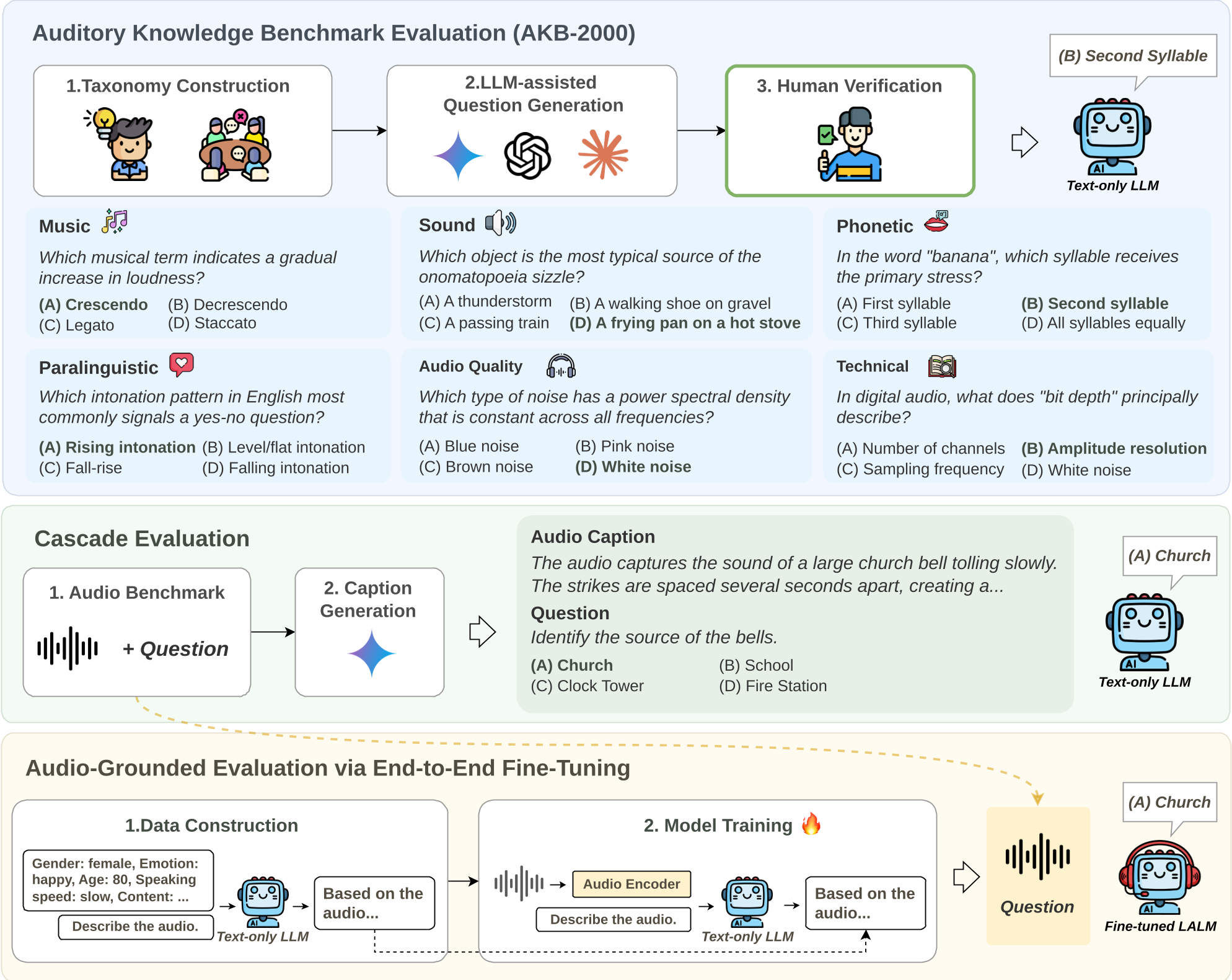 图 1:从纯文本知识到真实音频落地,全方位探测 LLM 的听觉灵魂。
图 1:从纯文本知识到真实音频落地,全方位探测 LLM 的听觉灵魂。
3. 关键洞察:Qwen 的胜出与 Llama 的落后
实验结果给出了几个令人惊讶的结论:
- Backbone 决定论:在参数量相近的情况下,Qwen 家族表现出了统治级的听觉常识。Qwen2.5-7B 在多项指标上大幅领先 Llama-3.1-8B。即便 Llama 的训练数据更多,在听觉维度的特征分布上似乎并无优势。
- 文本是音频的先驱:图 2 显示了极高的相关性(r=0.94)。这意味着,如果你在 AKB-2000 上测出一个模型很烂,别浪费卡去练它的音频版了,它大概率跑不赢。
- 音韵学瓶颈:几乎所有 LLM 在“押韵”、“同音词”和“重音预测”上都表现拉胯。这是纯文本预训练的天然缺陷——它们知道词义,但不知道词的“读音”在物理空间如何叠加。
 图 2:在 MMAU 和 MMAR 榜单上,不同 Backbone 带来的性能代差。
图 2:在 MMAU 和 MMAR 榜单上,不同 Backbone 带来的性能代差。
4. 深度分析:端到端 LALM 真的赢了吗?
论文提出了一个非常有挑战性的观点:当前的端到端 LALM 甚至跑不赢“串联模式”(即 Gemini 描述音频 + LLM 回答)。
这意味着什么?
- 音频特征流失:当前的音频编码器(如 Whisper-large-v3)在将波形压成分词向量时,丢失了太多细节。
- 对齐瓶颈:与其说是 LLM 不行,不如说是我们还没找到让 LLM “听懂”编码器信号的最佳翻译官。
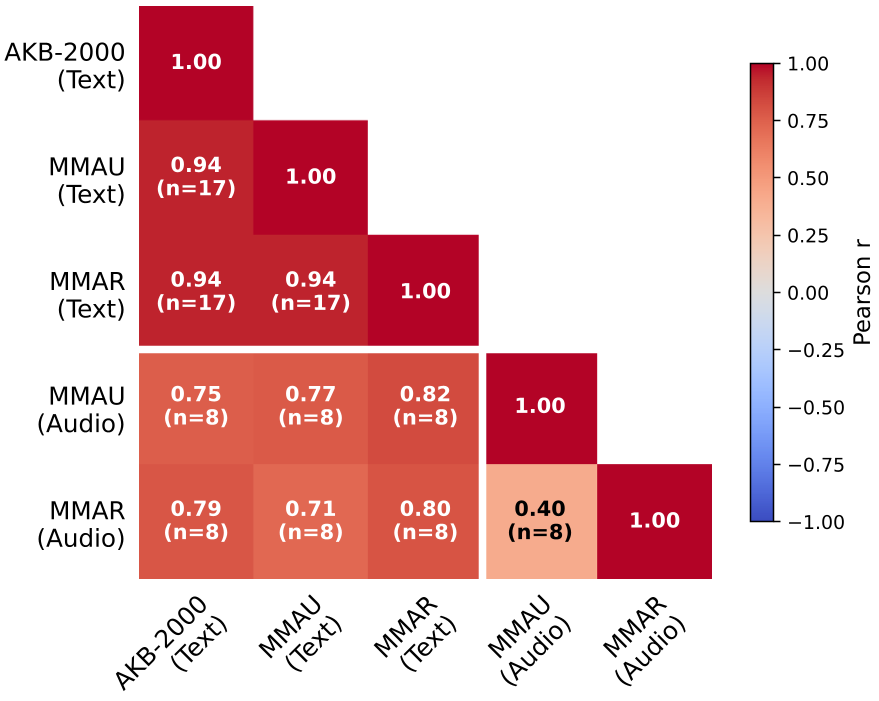 图 3:文本指标与音频指标的高度一致性,证明了听觉知识是一种相干的属性。
图 3:文本指标与音频指标的高度一致性,证明了听觉知识是一种相干的属性。
5. 总结与未来展望
这项工作为沉迷于刷榜的音频社区敲响了警钟:
- 选对 Backbone 比堆数据更重要:在尝试复杂的架构前,先通过 AKB-2000 挑个聪明的大脑。
- 补齐音韵短板:LLM 需要额外的词典或音位信息来理解“发音”。
- 优化音频表征:目前的 LALM 中,LLM 的推理潜力远远没有被音频输入喂饱。
作者通过 AKB-2000 证明了:LLM 不是在音频训练阶段才突然变聪明的,它的潜力早在阅读那几万亿个 Token 的文本时,就已经写在了参数里。