本文针对大语言模型训练,研究了随机条件梯度方法(SCG,如 Scion)中 Batch Size 的作用,并提出了基于 -KL 条件的收敛分析。核心贡献是推导出了在固定 Token 预算(Token Budget)下的 BST Scaling Rule,实现了学习率、Batch Size 和序列长度的协同优化。
TL;DR
大模型训练中,Batch Size 是越大越好吗?本文通过严谨的数学推导给出了否定答案。作者提出了 BST (Batch-Sequence-Token) Scaling Rule,证明在固定 Token 预算下,Batch Size 存在一个最优的“甜点区”。研究表明, 是实现最优收敛的关键,且这种扩展法则能有效指导超参数从小型代演模型(Proxy Model)无缝迁移至万亿参数规模。
背景:超越局部稳定性的 P
近年来,P (Maximal Update Parameterization) 解决了跨模型宽度的超参数迁移问题,确保了训练初期的稳定性。然而,模型训练是一个长期动态过程,P 并没有告诉我们:当 Token 预算 增加时,Batch Size ()、序列长度 () 和步长 () 应该如何联动?
本文填补了这一空白,将视角从“单步更新”转向“长程轨迹”,探讨在受限预算下如何压榨每一枚 Token 的优化价值。
核心直觉:三个优化状态
作者在 -KL 条件下推导出的优化误差 与有效尺寸 的关系呈现出显著的阶段性特征(见下式):
- 噪声主导区 ( 较小):此时误差随 增加而减小,增加 Batch Size 能显著抑制随机梯度噪声。
- 最优饱和区:误差与 无关,仅取决于总预算 。这是硬件利用率与优化效率的平衡点。
- 迭代匮乏区 ( 过大):随着 继续增大,更新步数 急剧减少,导致模型还没收敛就耗尽了 Token。
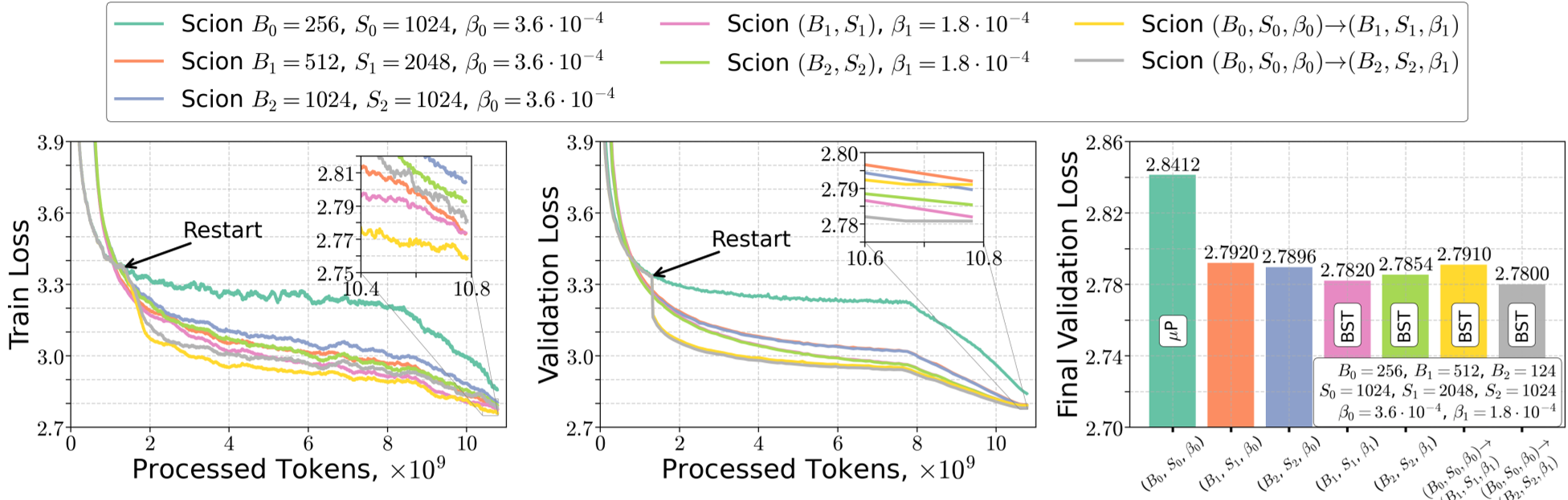 图:在 1B 模型上,遵循 BST 准则的重启策略(Restarted Scion)明显优于传统的固定 Batch Size 方法。
图:在 1B 模型上,遵循 BST 准则的重启策略(Restarted Scion)明显优于传统的固定 Batch Size 方法。
方法论:Scion 与 -KL 的结合
本文的研究对象是 SCG (Stochastic Conditional Gradient) 方法,即最近在工业界大火的 Muon 优化器的同族算法。其核心在于利用线性最小化算子(LMO)替代复杂的投影操作。
关键技术点:
- -KL 条件验证:作者通过实验证明,LLM 的训练损失(Loss)与其梯度的对偶范数之间存在强线性相关性,这为在非凸环境下使用该理论工具提供了坚实基础。
- BST 联动方程:推导出最优配置满足 且 。
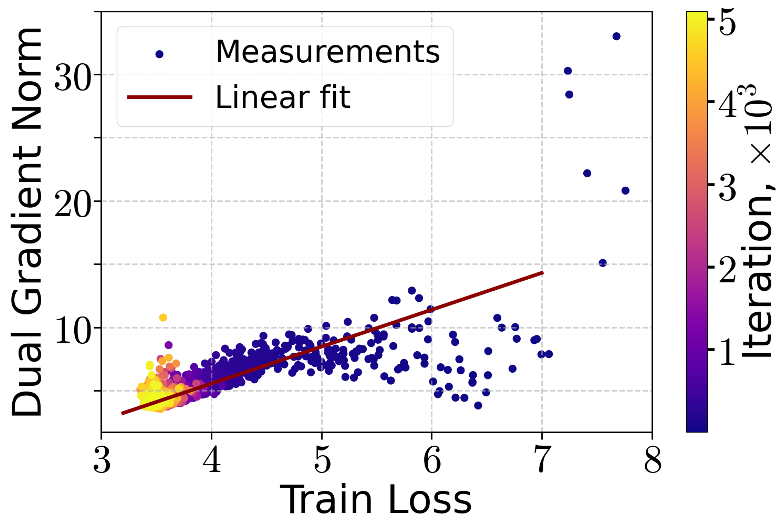 图:对 -KL 条件的实证检验,展示了 Loss 与梯度范数在训练中后期的线性关系。
图:对 -KL 条件的实证检验,展示了 Loss 与梯度范数在训练中后期的线性关系。
实验战绩:从 124M 到 1B 的无痛迁移
研究人员在 NanoGPT 架构上进行了大规模消融实验:
- 打破 P 局限:实验显示,完全遵循 P(即保持各项参数不变)在 增加时表现低效。而采用本文的“重启策略”——在训练中途增加 并调整步长,能获得更低的验证损失。
- 精度预测:理论预言的步长 和动量参数 的最优值与实际扫参结果惊人一致。
深度洞察
- 大 Batch Size 并非原罪:过去认为大 Batch Size 导致泛化变差,本文指出如果步长和 Token 预算能对应匹配,大 Batch Size 依然是高效的。
- 序列长度的权衡: 和 在公式中是对称的。增加上下文长度 本质上也在通过增加单步计算量来减少总更新次数,因此必须通过调整步长来补偿。
- 实践指南:当数据阶段性更新(Delayed-data regime)时,应根据最终可预知的总 Token 规模来动态调增 Batch Size,而非从头到尾死守固定值。
总结
这篇论文将复杂的优化理论转化为可以直接落地的“调参说明书”。它告诉我们:随着 LLM 训练规模的指数级增长,我们需要的不只是更强的算力,更是像 BST Scaling Rule 这样精确的导航算法。
局限性:目前分析主要基于 -Smoothness,对于更加激烈的非平稳优化场景(如极其深层的 Transformer),其曲率常数的演变可能更为复杂。