本文推出了 BizGenEval,一个专门针对商业视觉内容生成的系统性基准测试,涵盖网页、幻灯片、图表、海报和科学插图五个领域。该基准通过 20 个评估任务和 8,000 个由人类验证的检查清单问题,在 26 个主流模型上验证了当前生成模型在结构化商业设计中的表现,其中 Nano Banana Pro 取得了领先成绩。
TL;DR
传统的图像生成模型往往在“炫技”(产出精美的自然风光)上炉火纯青,但在“干活”(生成一份准确的 PPT 或科学图表)上漏洞百出。微软与多家高校联合发布的 BizGenEval 是首个针对真实商业设计场景的深度测评系统。它告诉我们:在商业世界里,准确性(Precision)永远比美感(Aesthetics)更重要。
痛点深挖:为什么 AI 画不出合格的商业图表?
在学术界,我们常用 GenEval、T2I-CompBench 或是简单的 CLIP Score 来评估模型。但这些指标在商业场景下几乎失效。
- 密集文本难题:商业海报需要精确到每个字符的文字渲染。
- 结构约束挑战:科学插图中的箭头指向、层级关系、坐标轴刻度容不得半点胡编乱造。
- 归纳偏差错觉:许多模型通过训练捕获了 PPT 的“风格”,能画出像模像样的背景和方块,但无法按照 Prompt 精确放置三个图标或计算饼图比例。
BizGenEval:20 维能力的“魔鬼训练营”
作者将测评维度细化为五个领域。最令人印象深刻的是其 Checklist-based Evaluation 协议。

每一个 Prompt 都会配套生成 20 个验证问题,涵盖了:
- Layout (布局):空间组织、层级流向。
- Attribute (属性):颜色、形状、数量、图标。
- Text (文本):长短段落、表格内容的字符级准确度。
- Knowledge (知识):跨越物理、化学、历史的常识对齐。
为了模拟真实人类设计师的指令,Prompt 通常长达数百甚至上千个 Token,这对模型的 Instruction Following 能力提出了极高要求。
核心发现:商业能力的“两极分化”
在对 26 个模型(包括 Nano Banana, GPT-Image, FLUX 等)进行大规模测评后,数据揭露了残酷的现实:
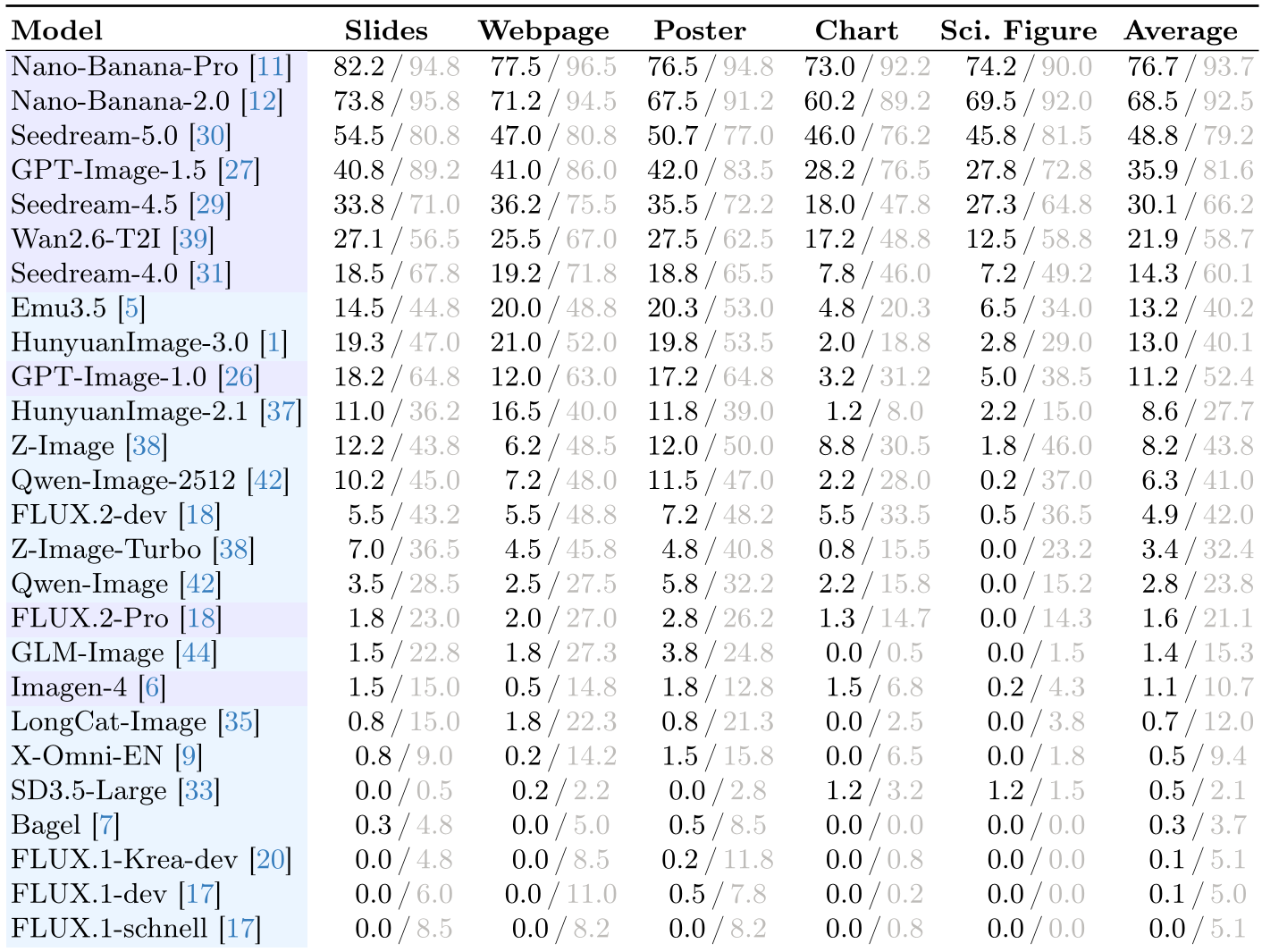
- 闭源 API 的统治地位:Nano-Banana-Pro 与 GPT-Image-1.5 稳居第一梯队。开源模型(如 SD3.5, FLUX 等)在处理商业文档时由于缺乏大规模多模态强化训练,平均分往往惨不忍睹。
- “样貌”不代表“灵魂”:很多模型能生成看起来很专业的 Charts,但如果你细看刻度线和数值标签(Attribute Binding),就会发现它们大多是随机分布的图形,毫无数学逻辑。
- 自然图像能力无法迁移:在 GenEval 表现强劲的模型,在 BizGenEval 上可能直接垫底。这说明简单的物体组合能力(如“一只穿草裙的猫”)不等同于复杂的结构化输出能力。
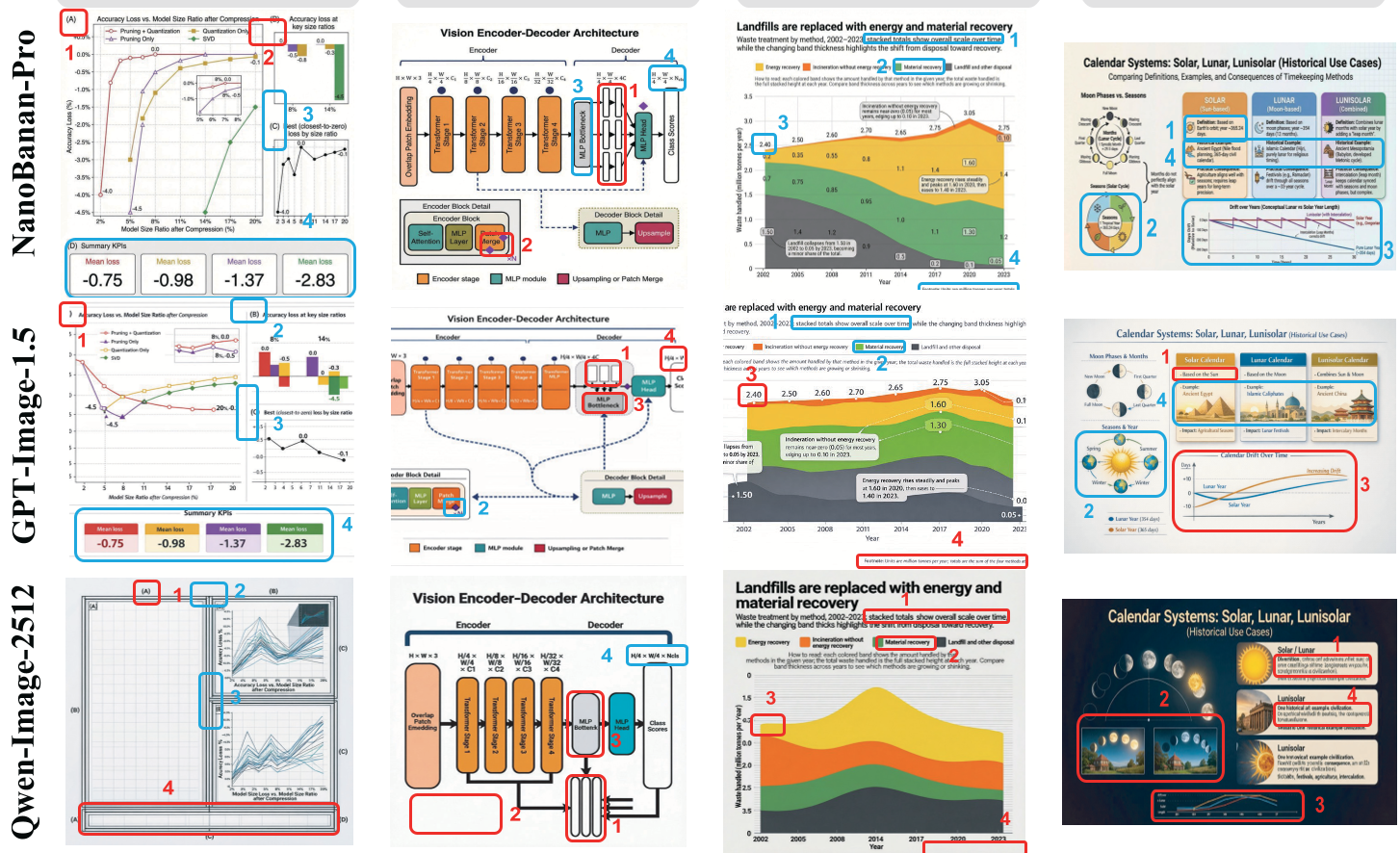 在上述图表生成中,GPT 系列在处理精准 marker 数值时出现了严重的“同质化”错误。
在上述图表生成中,GPT 系列在处理精准 marker 数值时出现了严重的“同质化”错误。
深度洞察与总结
BizGenEval 的出现标志着 AI 视觉生成从“玩具阶段”向“工具阶段”的考场迁移。
关键结论:
- 多模态底层能力是关键:Nano-Banana-Pro 之所以强大,是因为它底层接入了 Gemini 3 Pro 级别的多模态推理能力,能理解“为什么这个图层要放在这里”。
- 确定性是未来的战场:当前的 Diffusion 架构天生具有随机性,如何引入类似 Layout-to-Image 的强引导逻辑,是商业生成下一步的突破口。
局限性:目前的自动裁判(Gemini-3-Flash)虽然已经达到 90.88% 的人类一致性,但在处理极细微的文字重叠或复杂的 3D 透视关系时,仍可能存在判断偏置。
展望未来,我们期待看到专门为专业设计人员优化的模型,而 BizGenEval 无疑是这块进阶之路上的试金石。