本文提出了 Chameleon,一种受生物启发的机器人长时程操纵(Long-horizon Manipulation)记忆架构。它通过几何感知的多模态 Token 写入和可微存储栈,在面对视觉混淆(Perceptual Aliasing)时实现了 SOTA 性能,确保了决策的一致性。
TL;DR
在机器人操作中,如果两个场景看起来一模一样,但你必须根据“刚才发生了什么”做出不同选择,机器人往往会“宕机”。这就是感知歧义(Perceptual Aliasing)难题。本文提出的 Chameleon 架构,借鉴人类情景记忆机制,通过几何锚定的感知和可微的存储栈,让机器人在“猜杯子”和“顺序烹饪”等复杂长时程任务中表现出了惊人的决策鲁棒性。
背景定位:跳出“语义压缩”的陷阱
目前的具身智能模型(如 VLA)在处理记忆时,通常走两条路:要么把历史压缩成一句话(如 RAG 风格),要么把所有图片堆进 Buffer。前者丢掉了空间细节,后者在面对相似场景时会发生检索干扰。
作者认为,真正的长时程智能应该是 Non-Markovian(非马尔可夫) 的。这意味着当前观察(Observation)不足以支撑决策,必须依靠内部状态。Chameleon 的出现,是具身智能存储机制从“简单缓存”向“逻辑神经科学”演进的重要一步。
痛点深挖:为什么你的机器人记不住?
想象一下“三仙归洞”(Shell Game)游戏:三个杯子完全相同。当你抓取时,当前的视觉信号无法告诉你球在哪。你需要记住的是杯子的移动路线。
- Prior Work 的局限:传统的相似度检索(Similarity-based Retrieval)会因为三个杯子长得太像而返回错误的记忆片段。
- Chameleon 的直觉:如果不预先在“写入记忆”时就加入空间约束,“读取记忆”时必然会混淆。
核心方法论:解构 Chameleon
1. 背侧/腹侧双流感知 (Dorsal & Ventral Streams)
Chameleon 模仿大脑视觉系统。**腹侧流(Ventral)**利用 DINO 提取“是什么”(颜色、外形);**背侧流(Dorsal)**利用机械臂末端执行器(EE)作为坐标锚点。
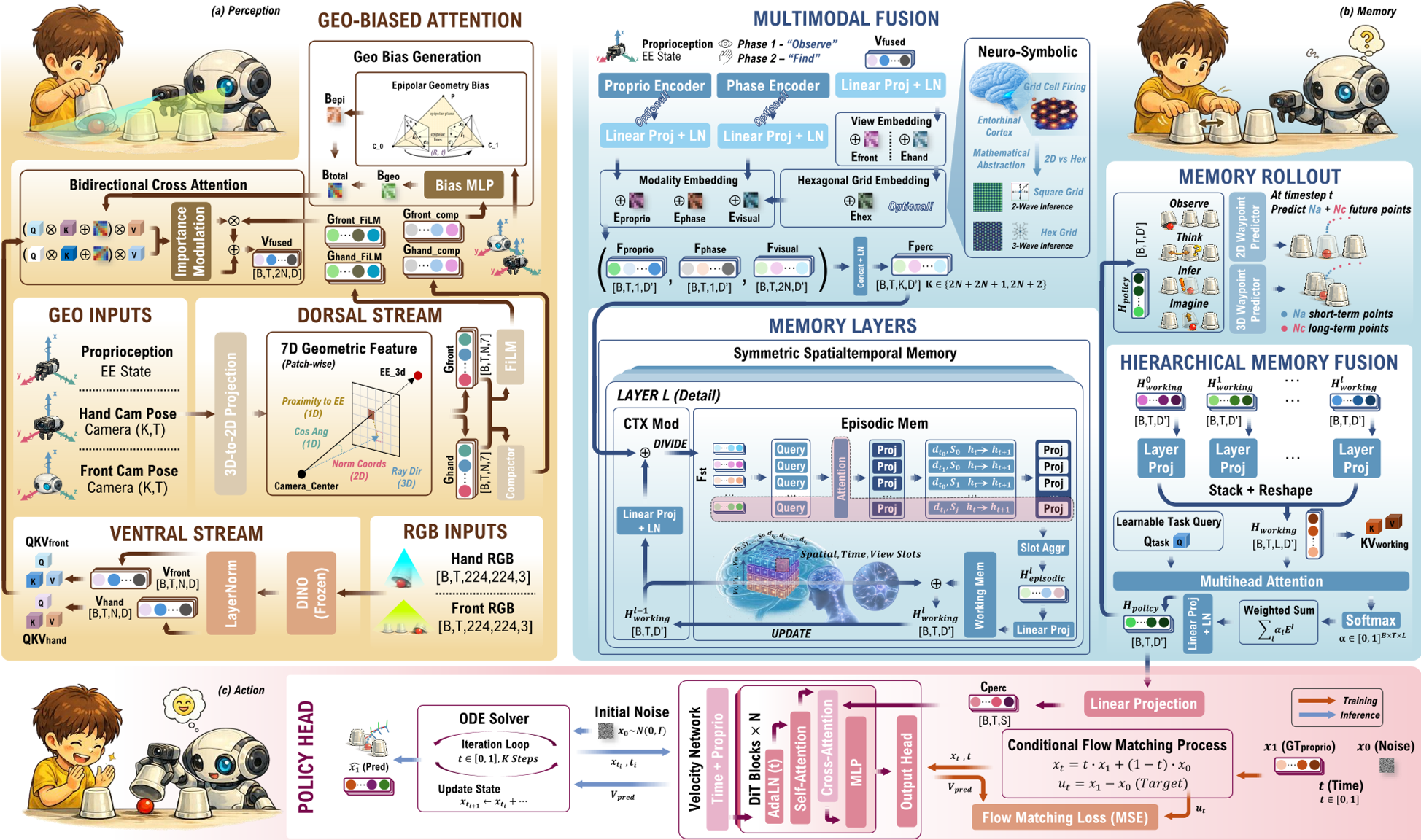
通过对极几何约束 (Epipolar Constraints),模型能强制前置摄像头和手部摄像头看到的 Token 在几何上保持一致,从而在感知阶段就减少了歧义。
2. 时空锚定存储栈 (Spatial-Temporal Memory Stack)
这是 Chameleon 的核心。它抛弃了显式的数据库检索,转而使用类似 Mamba 的 Selective SSM。
- 空间锚点(Spatial Anchors):对视觉 Token 进行稀疏化处理,只记录关键热点。
- 时间锚点(Temporal Anchors):为不同的存储槽位分配不同的“半衰期”,有的记短期波动,有的记长期目标。
3. HoloHead:用“想象力”补全记忆
为了防止记忆状态坍塌,作者引入了 HoloHead。它要求模型根据当前的记忆状态 ht,去预测未来的末端执行器轨迹。这在心理学上被称为模式补全(Pattern Completion):即使当前视觉被遮挡,模型也能在脑中“画出”球的移动轨迹。
实验与结果:统治混淆场景
作者推出了 Camo-Dataset 挑战模型,包含情景回忆(洗盘子)、空间追踪(变相怪杰杯子戏)和顺序操作(加调料)。
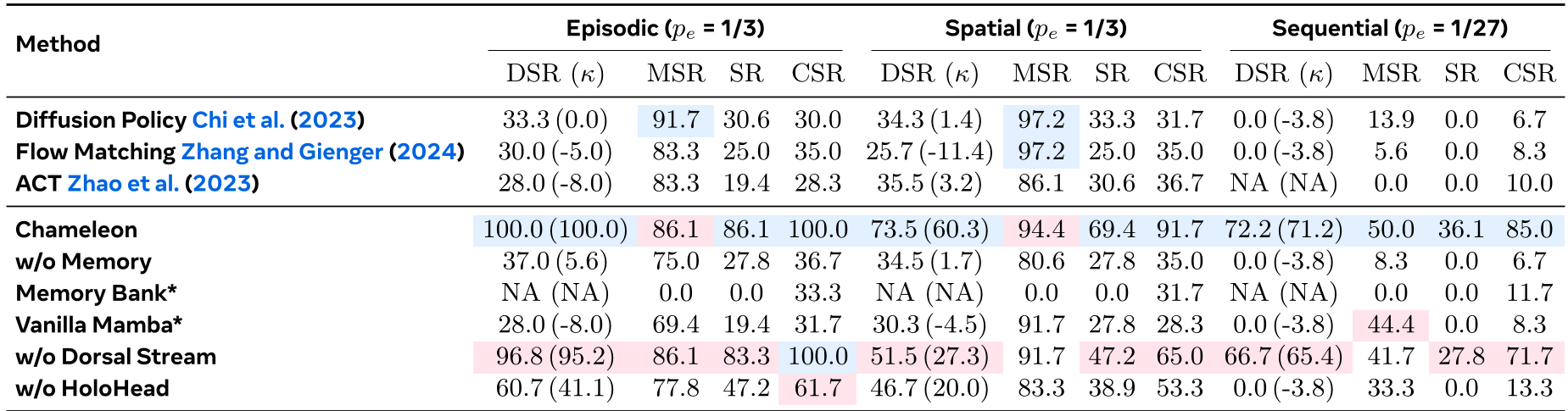
- 核心战绩:在最难的调味任务(需要记住前两步加了什么)中,传统 Diffusion Policy 的 Decision Success Rate (DSR) 几乎跌至 0,而 Chameleon 依然保持在 72.2%。
- 消融实验:移除 HoloHead 后,决策成功率大幅下降,证明了“预测未来”对于维持稳定记忆至关重要。
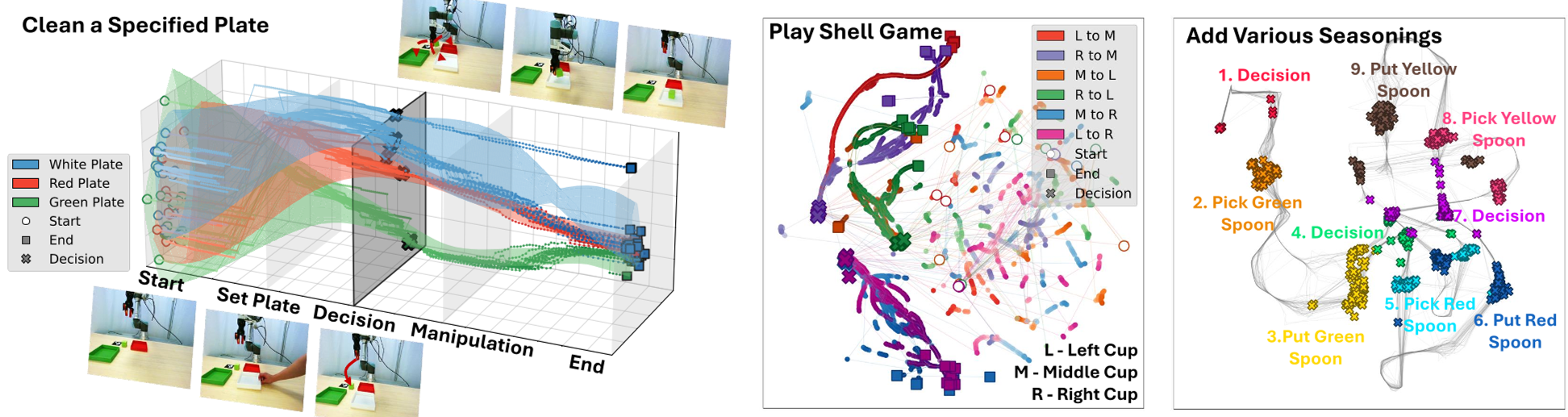
深度洞察:模式分离的可视化
通过 UMAP 可视化发现,Chameleon 的决策状态 ht 能够将视觉极度相似但历史背景不同的状态清晰地拆分开(见下图)。这证明了模型确实实现了模式分离(Pattern Separation)。
总结与局限
Chameleon 成功地将生物学启发的存储回路与现代 SSM 架构结合,解决了具身智能中的感知歧义痛点。
- 优点:极高的决策可靠性,且具有实时部署的低延迟(82ms)。
- 局限:目前尚未集成 VLA 的大模型语义先验,对于更通用的、需要自然语言逻辑推理的任务,仍需进一步扩展。
未来展望:将这种“海马体”模块插拔式地集成到开源基础模型(如 LLaVA-Embodied)中,或许是实现通用机器人长期自治的最优解。
Senior Editor's Note: 这篇工作的精妙之处在于它不仅是工程上的堆叠,而是对机器人操纵中“隐状态”缺失这一本质问题的数学回应。它告诉我们,处理长时程任务,靠“堆 Buffer”是不够的,得靠“几何约束下的想象”。