本文提出了“数学即压缩”的理论框架,利用自由幺半群(Monoids)模型探讨了人类数学(HM)在形式数学(FM)空间中的定位,证明了人类数学是指数增长空间中极薄的、具有多项式增长特征的可压缩子集。
TL;DR
数学是什么?本文给出了一个硬核的回答:数学是逻辑演绎空间的压缩算法。作者通过幺半群模型证明,人类数学(Human Mathematics, HM)之所以特别,是因为它在指数级膨胀的形式数学(Formal Mathematics, FM)海洋中,占据了极薄的、具备高度层次化可压缩性的“软区域”。
背景定位:这是一篇跨学科的重量级论文,结合了代数拓扑直觉、计算复杂性与形式化证明(Lean 4)。它不是在刷某个榜单,而是在为“数学价值”建立底层力学模型。
痛点深挖:消失在指数海洋里的数学
在形式逻辑的框架下,任何有效的演绎都是“数学”。但对于人类而言,这种广义数学(FM)是极其廉价且琐碎的。为什么我们觉得《费马大定理》重要,而随机生成的数百万个逻辑命题是垃圾?
现有的 AI 证明器(Theorem Provers)往往陷入搜索空间爆炸的困境。作者指出,问题的本质在于我们没有理解数学定义的本质:定义、引理和定理不仅仅是名字,它们是宏(Macros)。好的“宏”能通过对数级的密度实现指数级的表达扩展。
核心方法:幺半群模型与 expansion 特性
作者对比了两种基础模型:
- 自由交换幺半群 ($A_n$):对应于“只关心符号数量,不关心顺序”的场景。
- 自由非交换幺半群 ($F_n$):对应于“严格符号序列”的证明场景。
核心发现:
- 在 $A_n$ 模型中,作者证明了对数稀疏的宏集(如 10 进制位值表示法)就能产生指数级的表达扩展。
- 在 $F_n$ 模型中,即便宏的数量随长度多项式增长,也只能得到线性扩展。要实现超线性扩展,必须拥有几乎指数级的宏密度。
这暗示了:人类数学在行为上更接近 $A_n$ 而非 $F_n$。 虽然证明本身是有序的字符串,但有效的数学概念(宏)之间存在着某种奇妙的“类交换性”或结构冗余,使得我们可以用极短的定义(Wrapped Length)涵盖天文数字级的逻辑步骤(Unwrapped Length)。
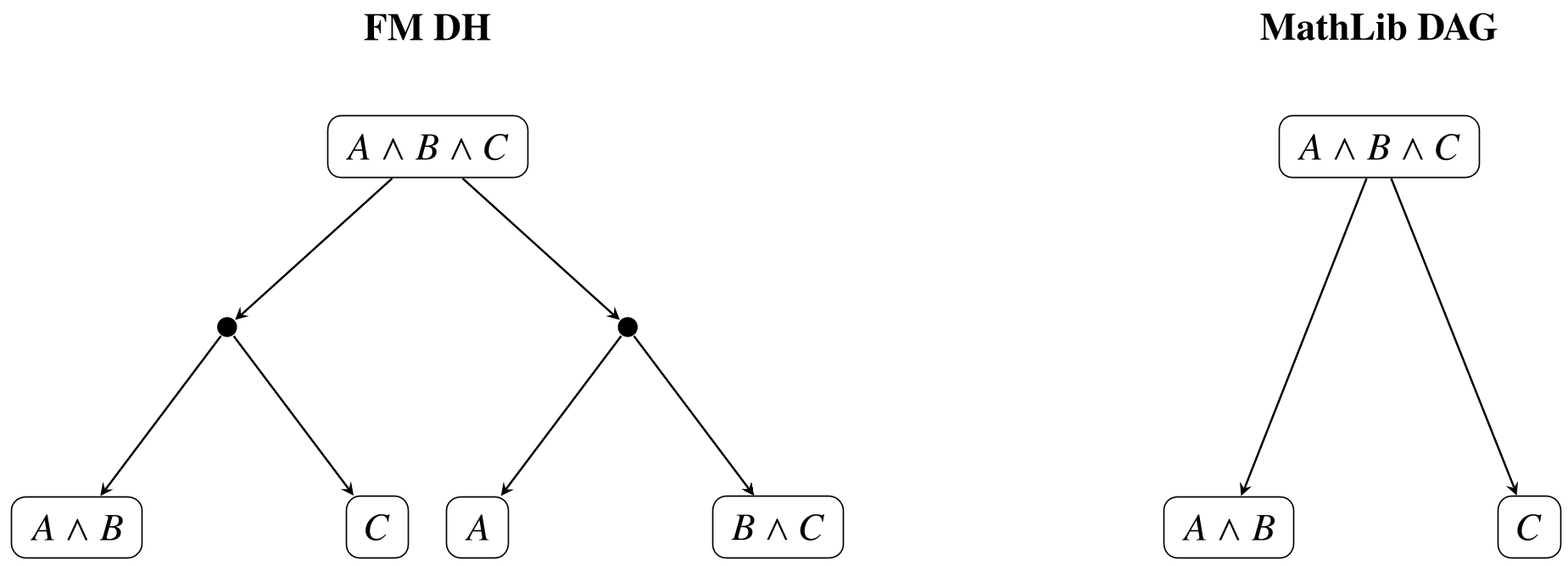 图 1:左侧为演绎超图,右侧为 MathLib 依赖图。数学可以看作是从复杂的证明路径中提取出简洁定义的 DAG。
图 1:左侧为演绎超图,右侧为 MathLib 依赖图。数学可以看作是从复杂的证明路径中提取出简洁定义的 DAG。
实验与结果:MathLib 中的“暴力真相”
作者在 Lean 4 的核心库 MathLib 上进行了实证。他们测量了三组关键数据:
- Wrapped Length:代码在 Lean 里的 Token 数量(定义的表观长度)。
- Unwrapped Length:将所有定义彻底展开到原始公理后的长度。
- Depth:定义嵌套的深度。
惊人战绩:
- 指数爆炸的深度:Unwrapped 长度随 Depth 指数增长。在代数几何的某些条目中,展开后的长度达到了 $10^{104}$ —— 这是一个比宇宙原子数还大的数字,却被压缩在了几百层的层级结构中。
- 恒定的表观长度:无论深度多少,人类数学定义的“表观长度”基本恒定(50-120 Tokens)。这证明了人类认知的内存限制:我们通过不断抽象(模块化)来对抗复杂性。
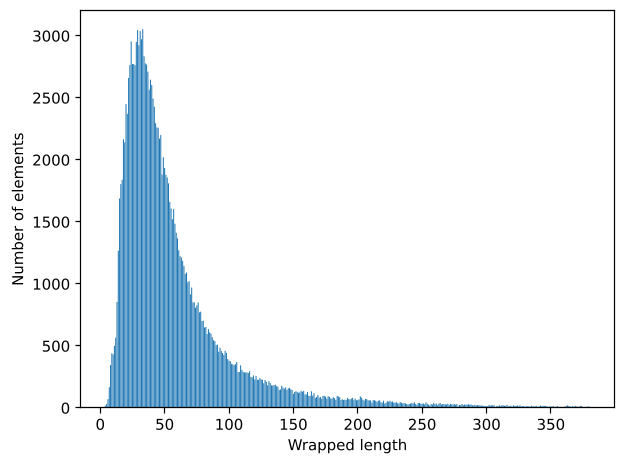 图 2:展现了 MathLib 中 log(Unwrapped Length) 与 Depth 和 Wrapped Length 的线性/指数关系。
图 2:展现了 MathLib 中 log(Unwrapped Length) 与 Depth 和 Wrapped Length 的线性/指数关系。
深度洞察:PageRank 识别“数学品味”
论文最后提出了一个极富启发性的应用:如何自动衡量一个定理的“利益(Interest)”?
- Reductive Compression ($T_0$):解包/打包比率。比值越高,说明该概念的抽象杠杆力越强。
- Deductive Compression ($I_0$):证明长度/陈述长度。这就是我们直觉上的“深刻性”。
通过一种偏置 PageRank 算法(利用压缩比作为跳转权重),作者构建了一个评价体系。那些深居简出、却被无数高压缩比定理引用的“load-bearing”引理,将被自动识别为核心数学。
总结与局限 (Takeaway)
本文深刻揭露了数学演化中的“懒惰原则”:人类只在能够被大幅压缩的逻辑领域停留。
局限性:
- 目前的模型将数学视为单向展开的字串,忽略了数学证明中的非确定性和多解性。
- “定义生成”本身是一个极其困难的优化问题(寻找最优宏集),目前尚未给出高效的自动化算法。
未来启示: 对于大模型(LLM)而言,与其训练它去生成更长的代码,不如训练它去发现更具有“压缩力”的中间定义。数学的真谛,不在于无休止的计算,而在于找到那个能崩塌整个证明树的简洁称谓。