本文提出了 AXON,一种基于多阶段扩散模型(Diffusion Model)的框架,旨在从单平面或双平面 2D X射线图像中重建高保真 3D CT 体积。通过“粗到精”的策略结合超分辨率网络,AXON 在真实临床数据集上实现了 SOTA 性能。
TL;DR
传统的 CT 扫描成本高、辐射大,而普通 X射线虽然普及却缺乏 3D 信息。AXON (Advanced X-ray to CT-volume Network) 通过一种创新的多阶段扩散框架,能够直接从医生最常用的真实 X射线(非合成 DRR)中,“脑补”出高精度的 3D CT 影像,在 PSNR 指标上突破性地提升了 11.9%。
1. 痛点:为什么“纸上谈兵”的 2D-to-3D 模型在临床中会失效?
将 2D 投影还原为 3D 体积在数学上是极其困难的,这种“升维”过程面临严重的空间歧义性(Spatial Ambiguity)。
目前该领域的研究大多陷入了一个陷阱:模型在实验室生成的**合成 X射线(DRR)**上表现完美,但在面对医院里真实的 X射线图片时,由于后者存在的散射现象、梁硬化(Beam Hardening)伪影以及不同设备的噪声差异,现有模型(如 GAN 或简单的 UNet)往往会产生模糊、解剖学错误的结构。
2. 核心机制:三阶段递进式生成 (Methodology)
AXON 的成功在于其“分而治之”的直觉:它不强求一步到位,而是将重建过程拆解为三个逻辑严密的步骤:
2.1 CoarseDiff:跨越维度鸿沟
作者引入了 Brownian Bridge Diffusion Model (BBDM)。与普通的随机加噪扩散模型不同,该模型在 2D 图像特征与 3D 粗略体积之间架起了一座“随机桥”。它首先从 2D X射线中提取语义,并显式地将其投影到 3D 空间,生成一个包含全局解剖布局(如胸腔轮廓、心脏大体位置)的粗糙体积。
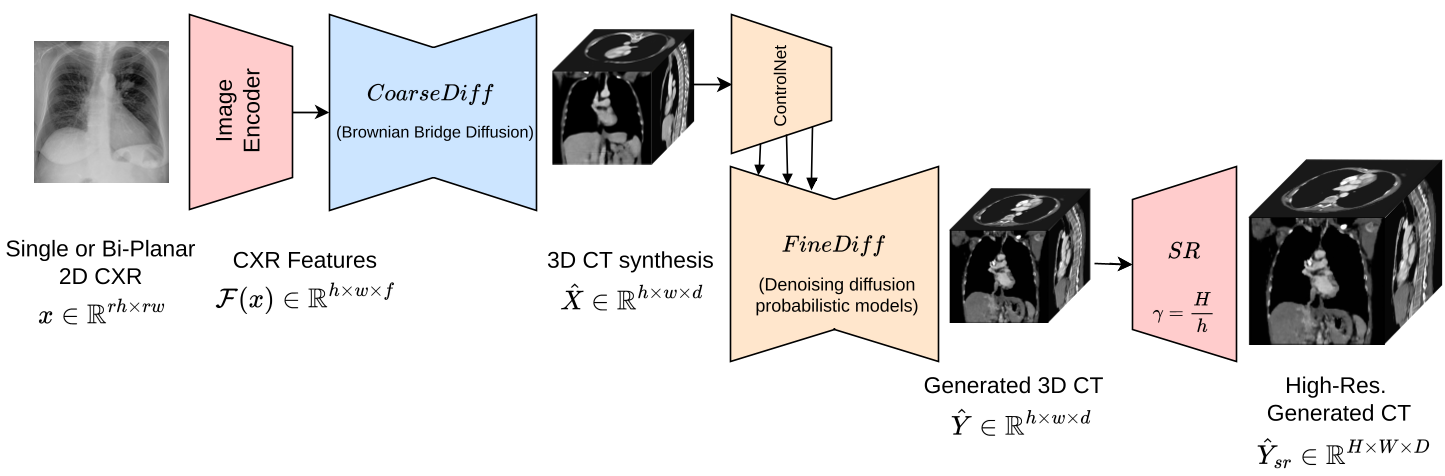
2.2 FineDiff:赋予解剖细节
在有了粗糙的 3D 骨架后,第二阶段利用预训练的 3D 扩散生成先验。通过 ControlNet 分支,模型以第一阶段的输出为约束,在 3D 空间内进行局部的强度优化和细节填充。这一步是解决“模糊感”的关键,它能还原出微小血管的走向和肺部纹理。
2.3 3D 超分辨率:迈向诊断级清晰度
为了平衡计算开销,扩散过程在 128³ 分辨率下完成。最后,通过一个专门针对 3D 体积优化的 SR-Net(基于 ESRGAN 改进),将体积上采样至 256³ 或更高,确保满足临床读片的需求。
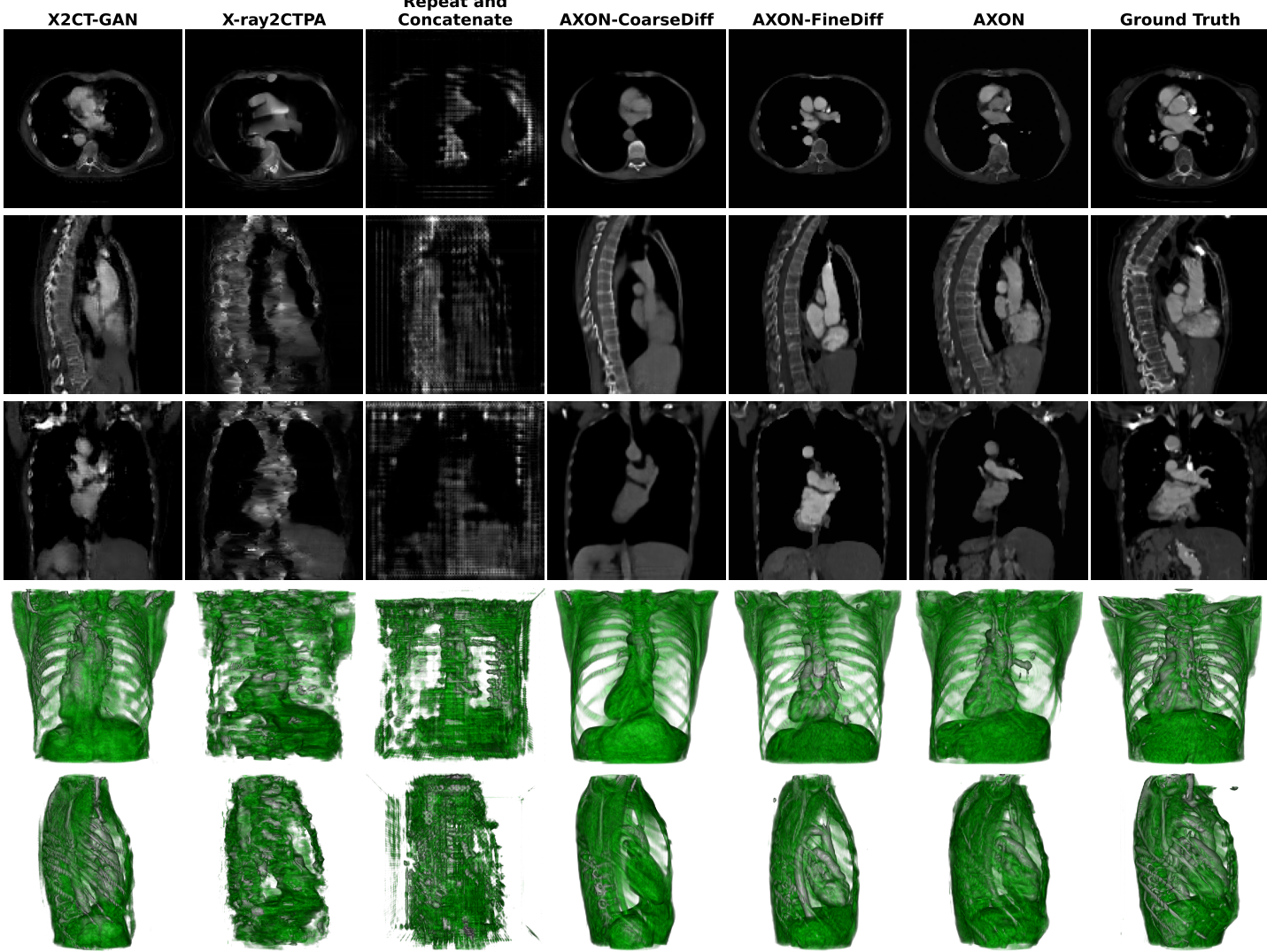
3. 实验战绩对比
研究人员在 LIDC-IDRI 公开数据集和完全独立的外部临床数据集上进行了双重验证。
3.1 量化指标
对比 GAN 基线(X2CT-GAN)和早期的扩散模型方法(X-ray2CTPA),AXON 在真实数据上的优势是压倒性的:
- PSNR: 21.21 dB (提升 ~9.5%~11.9%)
- SSIM: 0.540 (提升 24.9% 相对值)
- 泛化性: 在从未见过的外部医院数据上,表现依然稳健,这证明了其对不同设备拍摄的 X射线的适应能力。
3.2 双平面输入的威力
论文还探讨了如果有“正位+侧位”两张 X射线时的效果。结果显示,双平面输入能极大缓解深度方向的歧义,AXON 的 PSNR 进一步冲破了 22 dB。
4. 深度洞察与总结
AXON 的核心贡献不仅在于刷榜 SOTA,更在于它指明了医学影像翻译中的先验使用方式:
- 解耦维度转化与细节生成:2D 升 3D 是转换问题,清晰度是生成问题。
- 拥抱真实数据:仅仅在 DRR 上训练模型已经过时,利用扩散模型的鲁棒性来适配真实临床 X射线才是未来的方向。
局限性:尽管效果显著,但 3D 扩散模型的推理速度仍然较慢(相比 GAN),未来的研究可能会集中在加速采样算法或知识蒸馏上。
关键词:Diffusion Models, 3D Reconstruction, X-ray to CT, Medical AI