本文提出了 D-Mem,一种 LLM Agent 的双过程记忆系统(Dual-Process Memory)。该系统结合了基于向量检索的快速“系统 1”(Mem0*)和基于原始对话逐块扫描的深度“系统 2”(Full Deliberation),在高难度推理任务(如 LoCoMo 榜单)上达到了接近全量分析的 SOTA 性能。
TL;DR
长期以来,LLM Agent 的记忆系统一直被“语义检索(RAG)”模式统治。然而,这种模式在面对复杂的时间逻辑对比或多跳推理时,经常因为记忆压缩时的“信息折损”而翻车。D-Mem 借鉴人类认知的双过程理论,构建了一个“快慢结合”的记忆架构:既能用向量检索秒回简单问题,又能在关键时刻启动“深度审议”模式扫描原始记录。在 LoCoMo 等长对话基准上,它仅用 1/3 的成本就跑出了接近全量扫描的顶级精度。
痛点深挖:语义检索的“毁灭性压缩”
目前的记忆框架(如 Mem0, MemoryBank)大多遵循一个逻辑:把对话摘要成片段,存入向量数据库,用时再搜。
这看起来很高效,但存在一个致命缺陷:Query-Agnostic Compression(查询无关的压缩)。
- 直觉陷阱:当你把“昨天我去了趟上海”存入数据库时,系统可能只记住了“地点:上海”。
- 后果:如果未来你问“我出发前一天在干嘛?”,系统因为丢弃了相对时间锚点(“昨天”与当前日期的计算关系),导致推理链条彻底断裂。这种“有损抽象”是目前 Agent 难以进行长程严密推理的根本原因。
Methodology:D-Mem 的双系统架构
D-Mem 巧妙地引入了认知心理学中的 System 1 & System 2 概念。
1. 系统 1 (Mem0*):强化版快思考
基于 Mem0 进行了改进,作为基础的向量检索模块,负责快速处理 70% 以上的日常查询。它不仅检索语义相似的记忆,还加入了启发式的过滤步骤以减少干扰信息。
2. 质量门控 (Quality Gating):元认知守门人
这是 D-Mem 最核心的创新。系统 1 生成初步答案后,Gate 会启动一个多维评估:
- 相关性 (Relevance):答案真的回答了问题吗?
- 忠实度 (Faithfulness):有没有产生幻觉?
- 完整性 (Completeness):对于多跳问题,证据链足吗?
如果 Gate 亮起红灯,则立即升级到系统 2。
3. 系统 2 (Full Deliberation):高保真慢思考
系统 2 不再信任被压缩过的数据库,而是直接“翻旧账”:
- 将原始对话历史切块(Chunking)。
- 针对当前 Query 进行逐块的事实提取和量化评分。
- 通过多级过滤,精准提取出支撑推理的核心事实。
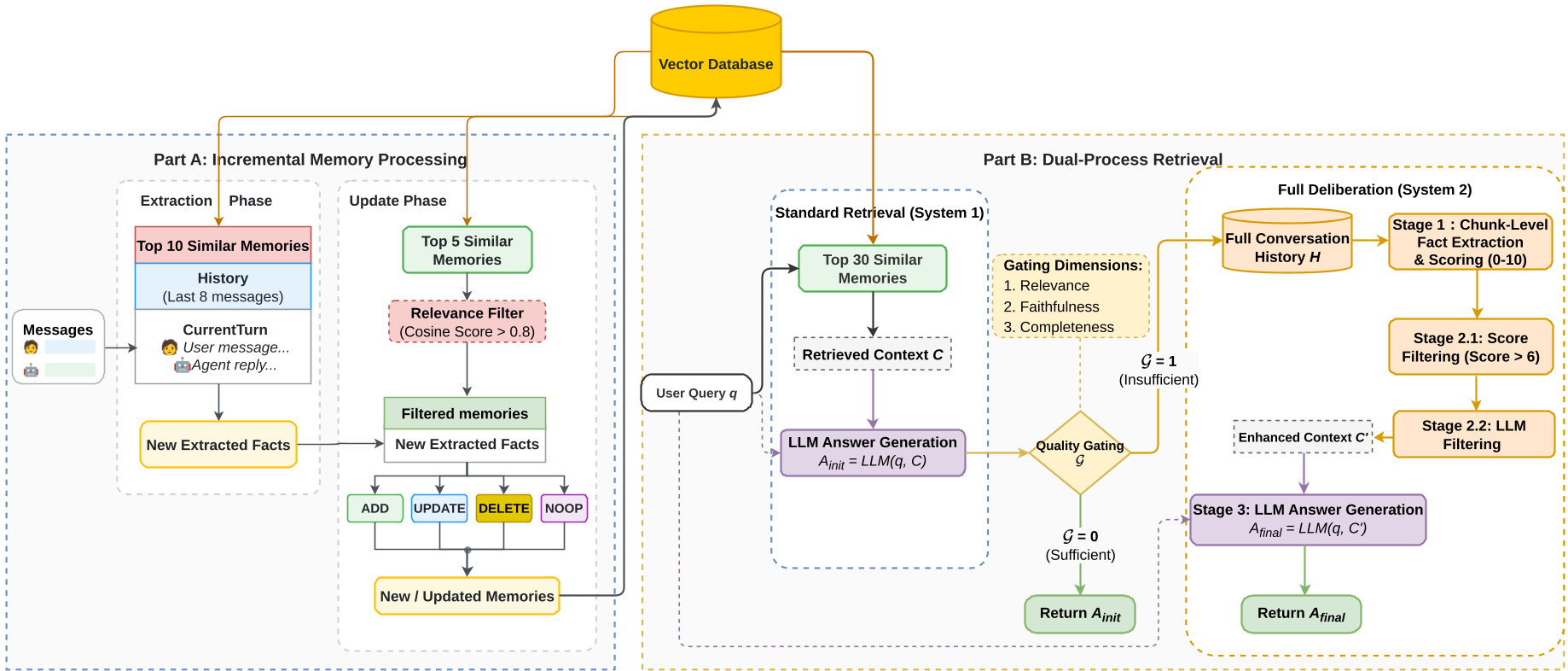 图1:D-Mem 架构概览。Part A 展示了改进的 Mem0 记忆维护,Part B 则是动态质量门控与系统 2 切换逻辑。*
图1:D-Mem 架构概览。Part A 展示了改进的 Mem0 记忆维护,Part B 则是动态质量门控与系统 2 切换逻辑。*
实验与结果:用更少的钱,办更硬的事
研究团队在 LoCoMo(长程对话推理)和 RealTalk(真实对话)两大基准上进行了测试。
核心表现
- 性能上限:在 LoCoMo 任务中,D-Mem (Quality Gating) 的 F1 分数相比原始 Mem0 提升了 12 个百分点(53.5 vs 41.5)。
- 经济效率:系统 2 虽然强,但 Token 消耗是惊人的。D-Mem 通过智能门控,仅在 24.1% 的疑难案例中触发系统 2,从而以全量扫描 35% 的 Token 成本,换回了 96.7% 的性能指标。
 表1:综合性能对比。可以看到 D-Mem 在精度、Token 消耗和响应时间之间取得了最优平衡。
表1:综合性能对比。可以看到 D-Mem 在精度、Token 消耗和响应时间之间取得了最优平衡。
为什么有效?
如图 2 所示,D-Mem 的提升幅度随题目难度(单跳 < 多跳 < 时间推理 < 开放域)线性增加。这充分说明了门控机制的有效性:简单题走低成本通路,高难度题走高保真通路。
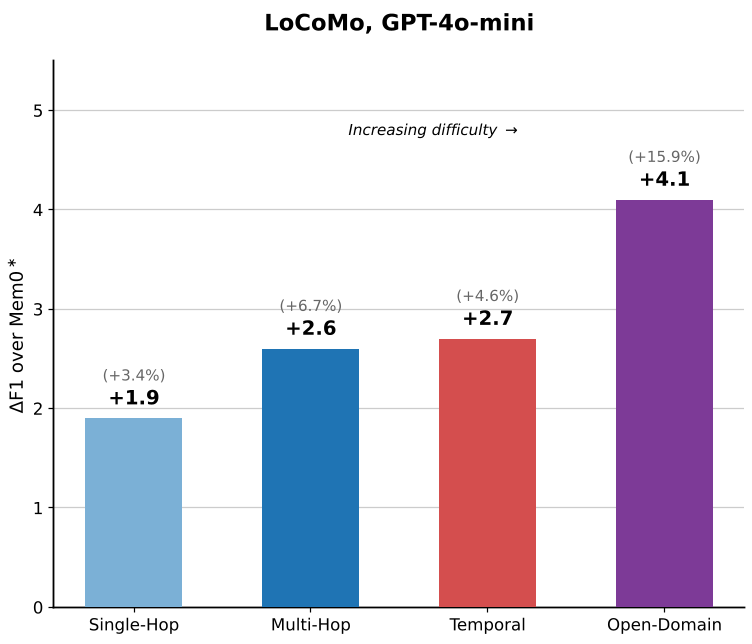 图2:随着问题复杂度的提升(如时间推理),D-Mem 的优势越发显著。
图2:随着问题复杂度的提升(如时间推理),D-Mem 的优势越发显著。
深度洞察与总结
局限性与挑战
作者坦诚地指出,即使有门控机制,系统 2 面对“无限上下文(Infinite Context)”时依然存在扩展性瓶颈。此外,目前的逐块提取仍然缺乏显式的逻辑链追踪,对于跨度极大的全局逻辑依赖仍有优化空间。
资深主编评论
D-Mem 的意义并不在于它刷高了多少分,而在于它对“记忆检索”范式的修正。它告诉我们:记忆不只是静态的存储桶,而是一个动态的重构过程。在 Agent 迈向长程自主化的道路上,这种具备“自知之明(元认知评估)”的记忆架构,将是解决 LLM 健忘和幻觉的必经之路。
Takeaway:未来的 LLM 应用开发者应考虑,与其不断追求极致的压缩算法,不如建立一套高效的“回溯与重读”机制。