本文提出了 SITH (Semantic Inspection of Transformer Heads),一种针对 CLIP 视觉 Transformer 的全无监督、无需训练且无需数据的解释性框架。通过对注意力头的 Value-Output (VO) 权重矩阵进行奇异值分解 (SVD),并结合创新的 COMP 稀疏分解算法,将模型权重直接映射为人类可理解的语义概念。
TL;DR
传统的模型解释性研究往往需要数千张图片来观察模型的“反应”(激活值),但 SITH (Semantic Inspection of Transformer Heads) 另辟蹊径:它不需要任何输入数据,直接对 CLIP 的权重矩阵动手术。通过奇异值分解 (SVD) 和一种新的稀疏编码算法 COMP,SITH 能精准指出每一个注意力头里哪些向量负责“颜色”、哪些负责“地理位置”。更酷的是,你可以直接通过修改这些奇异值来消除模型的偏见或封锁违规内容。
核心痛点:被数据“绑架”的解释性
在机制解释性(Mechanistic Interpretability)领域,我们习惯于通过输入大量图片来查看哪些神经元被激活。然而,这种 Activation-based 方法存在三个致命伤:
- 数据偏见:如果你的测试集里“鸟”总是在“水边”,你会误以为某个神经元识别的是鸟,其实它识别的是水。
- 粒度过粗:通常只能告诉你整个注意力头(Head)在做什么,但一个头往往是多义的。
- 计算成本:需要大规模前向推理才能得到统计特征。
SITH 的物理直觉:权重空间即语义空间
作者提出了一个深刻的见解:在 CLIP 这样训练良好的 Vision-Language 模型中,注意力头的 Value-Output (VO) 权重矩阵 实际上定义了信息如何在残差流(Residual Stream)中被读取和写入。
1. 奇异值分解 (SVD) 的妙用
对于任意一个注意头的 VO 矩阵,SITH 将其分解为左/右奇异向量。每一个奇异向量代表了模型内部的一个“计算轴”:
- 左奇异向量 ($u_i$):模型“读”到了什么特征。
- 右奇异向量 ($v_i$):模型打算向残差流“写”回什么语义。
2. COMP 算法:让数学公式开口说话
得到奇异向量后,如何知道它是啥意思?作者发明了 COMP (Coherent Orthogonal Matching Pursuit)。相比传统的匹配追踪算法,COMP 不仅要求重建出来的特征要像原向量(Fidelity),还加上了一个 语义相干性(Coherence Term) 的约束。
- 例子:如果一个向量代表“红色”,COMP 会倾向于选出“深红”、“朱红”、“绯红”这一组相关的概念,而不是选出一个“红色”再搭一个完全无关的“抽纸缸”。
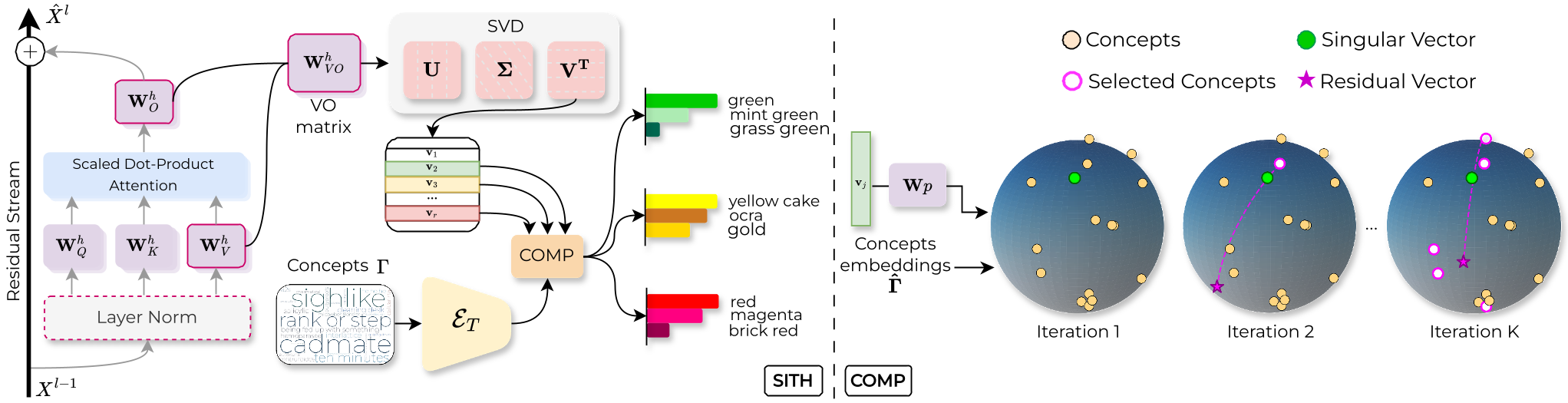 图 1:SITH 与 COMP 流程图。左侧展示了从 VO 矩阵到语义概念的分解;右侧详细描述了 COMP 如何在迭代中兼顾重建精度与语义一致性。
图 1:SITH 与 COMP 流程图。左侧展示了从 VO 矩阵到语义概念的分解;右侧详细描述了 COMP 如何在迭代中兼顾重建精度与语义一致性。
实验战绩:不只是解释,更是外科手术
SITH 的强大之处在于它赋予了研究者无需重新训练就能“编辑”模型的能力。
1. 消除伪相关(Spurious Correlations)
在 Waterbirds 任务中,模型常把“背景是水”当成“识别到水鸟”的证据。SITH 自动识别出那些编码“背景”、“位置”概念的奇异向量,直接将其奇异值归零(Zero-out)。
- 成绩:在不触碰模型其他部分的情况下,最差组准确率(Worst-group Accuracy)显著提升,表现优于头级消减方法 TextSpan。
2. 安全过滤:封锁 NSFW 内容
通过识别并压制与“裸露”、“暴力”相关的奇异向量,SITH 能在保持模型原有视觉理解能力的同时,大幅降低其对不安全内容的敏感度。其效果甚至可以媲美专门在安全数据集上精调过的模型。
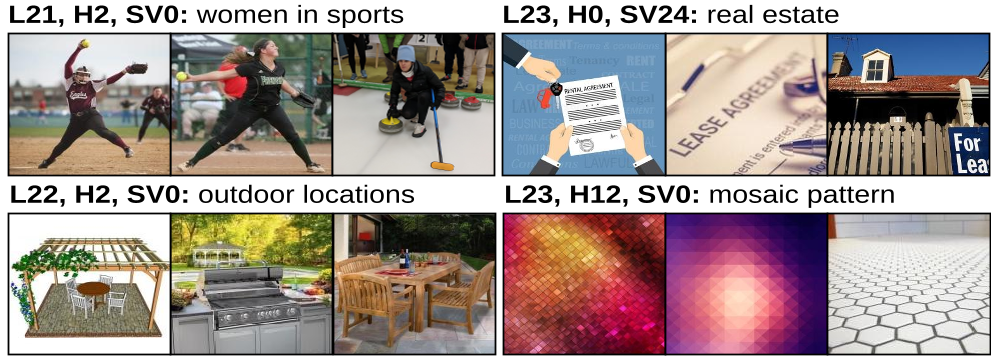 图 2:奇异向量与图像的对齐验证。我们可以看到,被 SITH 标记为“Street”或“Celebration”的轴,对应的正是这些含义的典型图像。
图 2:奇异向量与图像的对齐验证。我们可以看到,被 SITH 标记为“Street”或“Celebration”的轴,对应的正是这些含义的典型图像。
专家视角:精调到底改变了什么?
论文还探讨了一个哲学问题:Fine-tuning 时模型学到了新东西吗? SITH 的分析显示(见原文图 7 和图 8):Fine-tuning 并没有创造新的语义基石,而只是对预训练模型中原本就存在的稳定语义轴进行了“重新加权”。 这是一个非常符合“柏拉图表征假设”的结论——强模型已经理解了世界的大部分概念,场景适配只是在调整这些概念的音量。
总结与局限
SITH 证明了 Data-Free Interpretability 是完全可行的。它避开了昂贵的激活值计算,直接通过权重的数学分解触及了语义本质。 局限性:目前主要针对 VO 矩阵进行分析,对于 QK(Query-Key)矩阵(决定“哪里需要注意”)的权重级解释仍处于初级阶段。未来若能完全解耦“注意力产生”与“语义写入”的权重逻辑,我们将真正拥有操作 VLM 的全能手术刀。