本文提出了一个多轮合成数据生成框架,通过教师模型(Teacher)基于学生模型(Student)的反馈迭代调整题目难度。该方法在代码生成任务上显著提升了 RL 训练的收敛速度和性能,并在 Llama3.1-8B 和 Qwen2.5-32B 等模型上实现了 SOTA 效果。
TL;DR
在 LLM 的后训练阶段,强化学习(RL)已成为提升逻辑推理能力的标配。然而,研究人员发现 RL 训练往往会陷入“数据量增加,增益却停滞”的怪圈。本文提出了一种全新的多轮合成数据生成管线,不依赖教师模型的微调,仅靠 In-context Learning 就能生成具有“阶梯难度”的题目。这种方法不仅加速了收敛,还让 8B 规模的模型在 LiveCodeBench 等硬核榜单上表现出了跨级别的竞争力。
背景:RL 训练的“无效卷”与熵崩溃
当前的 RL 训练(如使用 GRPO 算法)面临两个极端:
- 极难题目:模型无法产生任何正向奖励,导致探索陷入僵局,浪费计算资源。
- 极易题目:模型过早学会,导致策略熵(Entropy)迅速坍缩,丧失了进一步探索复杂逻辑的能力。
作者指出,目前的开源数据往往缺乏关联性。即使有“简单”和“难”的题目,它们之间往往属于完全不同的领域,无法起到“从易到难”的引导作用。
核心创新:多轮合成数据流水线 (Multi-turn Pipeline)
作者借鉴了目标引导探索中的“踏脚石”概念,通过一个 Teacher 模型(如 GPT-OSS 120B)实现动态题目演化。
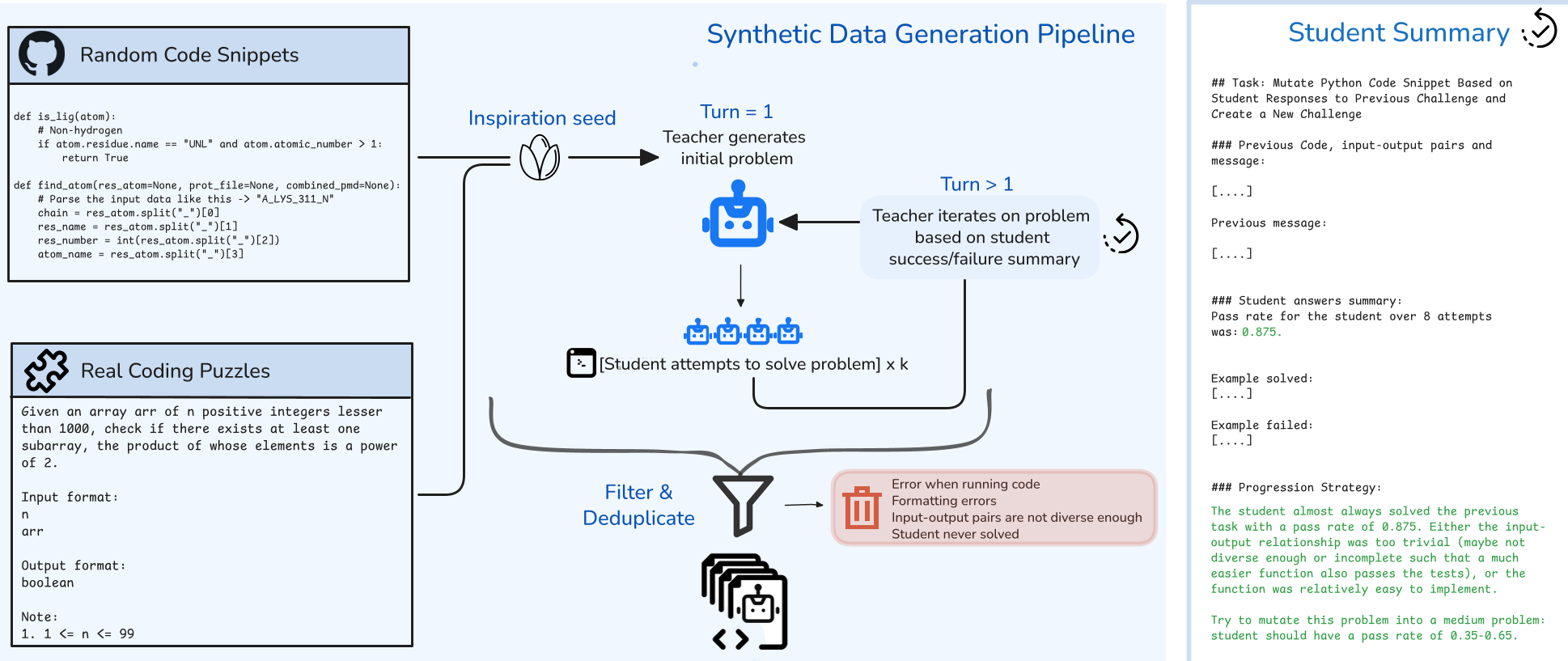
运作流程:
- 启发种子:从 Starcoderdata 等代码库中随机抽取 25-50 行代码片段作为灵感来源。
- 第 1 轮生成:Teacher 生成一个初始问题。
- 反馈闭环:Student 尝试解决,并将结果(通过率、成功/失败的代码样例)反馈给 Teacher。
- 难度突变:Teacher 根据反馈调整题目。如果学生全对,则增加约束(如增加 Budget 限制、时间复杂度要求);如果学生全错,则简化逻辑。
这种方式产生的 Easy-Medium-Hard 链条具有天然的知识连续性,是解决“硬探索”问题的关键。
实验结果:合成数据打败真实数据?
令人振奋的结论是:在固定计算预算下,25K 真实数据 + 20K 合成增强数据 的效果,显著优于 81K 纯真实数据。
关键洞察:
- 中等难度是“最优解”:单靠简单题目会导致严重的过拟合(LCB-Easy 高分,但 Hard 低分),而中等难度题目的训练能提供最稳健的泛化增益。
- 环境多样性 (Diversity):除了题目难度,环境类型(如 Induction, Abduction, Deduction, Fuzzing)的增加也是一条独立的扩展曲线。多样化的环境能有效抑制模型在单一模式上的过拟合。
深度思考:逆向课程(Reverse Curriculum)的奇效
本文的一个硬核发现在于:传统的“从易到难”课程并不总是最优。
作者发现,“从难/中到易”的逆向课程反而能延缓模型熵坍缩的发生。因为在训练初期,模型熵值最高,此时挑战中等难度的题目能最大化信息增益;到了后期模型趋于稳定时,再通过简单题目巩固基础知识,这种策略在 LCB-Medium 上的表现优于顺序课程。
总结与局限性
这篇工作证明了 synthetic RL data 的潜力不在于“量”,而在于“递进关系”。
- 优势:开源模型仅需少量高质量合成链条即可获得巨大提升。
- 局限:目前的 Teacher 模型仍然是解耦的(Off-line),未来的演进方向应当是将 Teacher 实时接入 RL 循环,实现真正的异步对弈。
对于正在构建代码大模型的团队来说,这篇论文提供了一个非常实用的方案:与其疯狂爬取 GitHub,不如精细化地“生产”带有阶梯难度的合成逻辑链。