本文提出了 Delightful Policy Gradient (DG),这是一种改进强化学习中策略梯度估计的新方法。通过引入基于“惊喜度”(Action Surprisal)的 Sigmoid 门控机制,DG 在 MNIST 上下文老虎机、Transformer 序列建模及连续控制任务中均超越了 PPO 和 REINFORCE 等基线方法,实现了更优的收敛速度和扩展性。
TL;DR
传统的策略梯度方法(PG)在更新时只看“甜头”(Advantage),却忽视了“意外”(Surprisal)。Google DeepMind 提出的 Delightful Policy Gradient (DG) 通过一个简单的 Sigmoid 门控,让模型学会“珍惜好运”并“忽略低级失误”。这一改进不仅降低了方差,更从根本上纠正了梯度在难易任务间的分配偏差,在 Transformer 和连续控制任务中展现了极强的 Scaling 潜力。
1. 痛点:策略梯度为何总是“欺软怕硬”?
在深度强化学习中,优化器的更新方向(Direction)决定了学习效率。然而,标准策略梯度存在两个被长期忽视的缺陷:
- 单上下文中的“噪声放大”:当模型偶尔尝试了一个它平时绝不会做的错误动作(低概率负优势),产生的梯度向量会异常巨大,将模型拉离正确轨道。
- 多上下文中的“分配不均”:在同一个 Batch 里,模型倾向于在已经学得很好的任务上投入更多梯度预算,而真正需要攻克的难题却因权重不足而进度缓慢。
作者指出,这不仅仅是采样方差的问题(Variance reduction 无法彻底解决),而是 期望梯度方向本身就偏离了最优的学习路径。
2. 核心直觉:什么是“愉悦度” (Delight)?
为了修正上述偏差,作者引入了 Delight($\chi$) 的概念: $\chi = ext{Advantage} imes ext{Action Surprisal}$ 其中 Surprisal 是 $-\log \pi(A|H)$。
- 意外的成功 (Breakthrough):低概率动作却拿到了正奖励。门控开启($\sigma \approx 1$),全力保留梯度。
- 罕见的失败 (Blunder):低概率动作拿到了负奖励。门控关闭($\sigma \approx 0$),忽略此噪声。
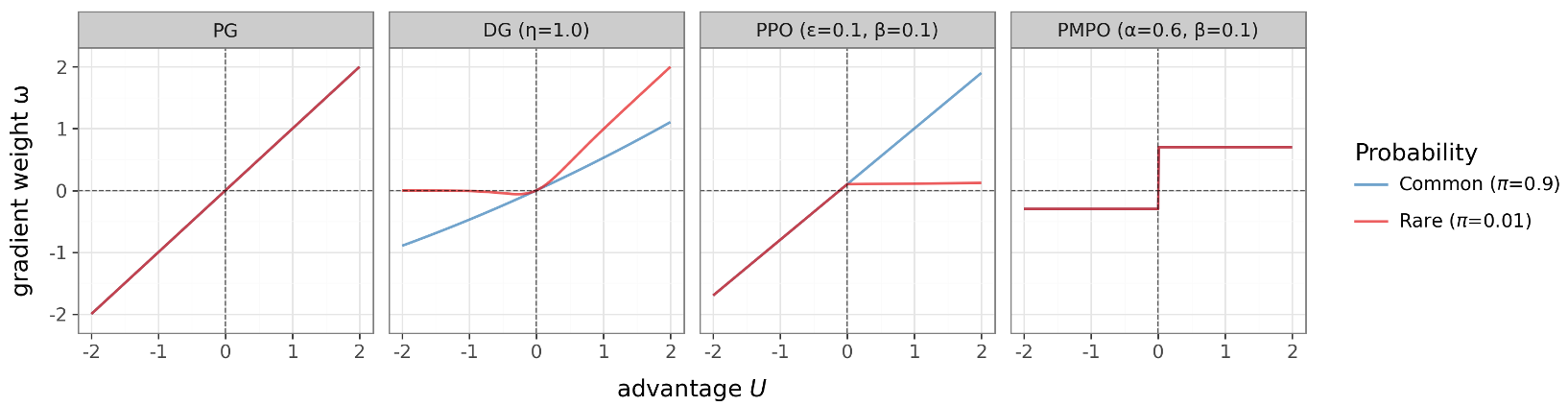 图 1:不同策略下权重 $\omega$ 随优势值 $U$ 的变化。可见 DG 对罕见成功和罕见失败的处理是非对称的。
图 1:不同策略下权重 $\omega$ 随优势值 $U$ 的变化。可见 DG 对罕见成功和罕见失败的处理是非对称的。
3. 方法论详解:一行代码的降维打击
DG 的实现极其简洁,几乎是标准的“Drop-in replacement”。它在更新量中插入了一个 Sigmoid 因子: $$\Delta heta \propto \sum \sigma( ext{Delight}) \cdot ext{Advantage} \cdot abla \log \pi$$
这种机制在数学上可以被视为一种局部熵正则化门控。它迫使梯度向“交叉熵预言机”(Supervised Cross-Entropy Oracle)靠拢,即平等地对待每一个任务上下文,而不是被简单任务牵着鼻子走。
4. 实验战绩:从 MNIST 到 Transformer 的全面碾压
4.1 MNIST 诊断测试
在将 MNIST 视为 Contextual Bandit 的实验中,DG 显著快于 PG,并跨越了 PG 的物理性能上限。即使 PG 使用无限样本,其效果也无法达到 DG 在单样本下的表现,这证明了 DG 确实优化了梯度方向本身。
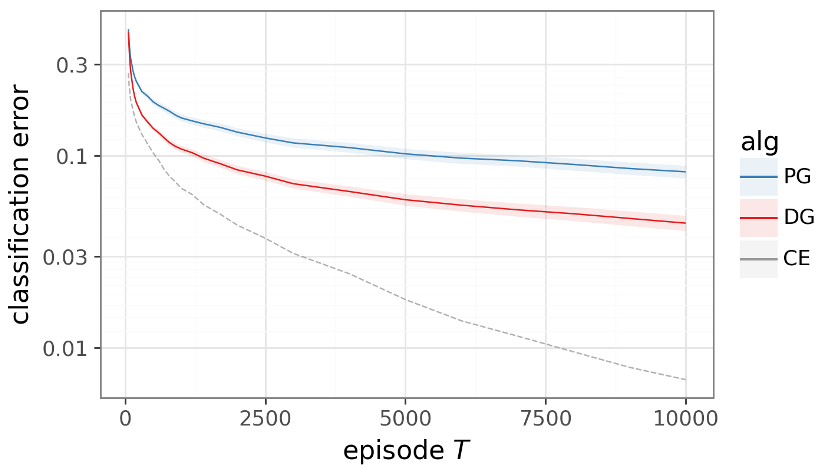 图 2:在没有标签只有奖励的情况下,DG 补全了 PG 与监督学习(CE)之间 50% 的差距。
图 2:在没有标签只有奖励的情况下,DG 补全了 PG 与监督学习(CE)之间 50% 的差距。
4.2 Transformer 序列扩展性
在挑战性的 Token Reversal 任务(要求 Transformer 逆序生成字符)中,随着序列长度 $H$ 和词表大小 $M$ 的增加,传统方法如 PPO 迅速失效。而 DG 展现出了更优的幂律扩展特性(Power-law scaling),优势随任务难度指数级放大。
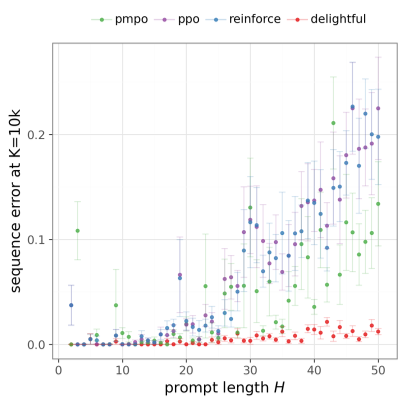 图 3:在 Transformer 任务上,DG 的收敛速度和最终精度远超 PPO。
图 3:在 Transformer 任务上,DG 的收敛速度和最终精度远超 PPO。
5. 深度洞察与总结
为什么 DG 有效? 从算法直觉上看,DG 赋予了模型一种“自省”能力:如果我做错了一件我本来就知道不该做的事,别大惊小怪;如果我意外做对了一件我本以为会失败的事,那才是真正的价值所在。
局限性与未来展望:
- 连续动作空间的敏感度:在连续控制任务中,Surprisal 的计算依赖于概率密度,可能需要剪切(Clipping)或白化(Whitening)处理。
- 超参数倾向:虽然文中统一使用 $\eta=1$,但在极大规模或极稀疏奖励的场景下,温度系数的动态调节可能仍是必要的。
总结: Delightful Policy Gradient 提供了一个极简且强大的视角:策略梯度学习中,权重分配与方向选择同等重要。它不仅是一个更稳健的优化器,更为未来超大规模模型(如 LLM 的强化学习微调)提供了更具扩展性的梯度加权新基准。