The paper introduces STAR (Synthesis, Training, And Reinforcement), a holistic post-training pipeline designed to optimize Large Language Models (LLMs) for long-horizon tool-use tasks. Using TravelPlanner as a benchmark, the authors demonstrate that their RL-trained 1.5B–7B models achieve SOTA performance, significantly surpassing proprietary models like Kimi-K2.5 and GPT-4o.
TL;DR
Reinforcement Learning (RL) is the "secret sauce" for moving LLMs from text generators to autonomous agents. However, for long-horizon tasks like planning a 7-day multi-city trip, the community has lacked a clear recipe. The STAR pipeline (Synthesis, Training, and Reinforcement) provides that recipe. By systematically testing reward types, model sizes, and data mixes, the authors achieved SOTA results on the TravelPlanner benchmark, proving that even a 7B model can outperform commercial giants when trained with the right RL strategy.
The Core Challenge: Long-Horizon Fragility
Traditional agentic RL focuses on "short-turn" tasks (e.g., answering a single question). Real-world agency requires long-horizon planning: satisfying dozens of constraints (budget, dietary, smoking rules, flight times) across 10+ tool interactions. If an agent fails at Turn 12, the entire trajectory collapses. Prior works often tweak one variable (like exploration), but STAR is the first to provide a holistic view of the "Design Space":
- Reward Shaping: Does the agent need a "nudge" (dense reward) or just the final result (sparse)?
- Model Scaling: Does a 7B model learn differently than a 1.5B model?
- Data Composition: How much data is enough before the model "breaks" and loses its general intelligence?
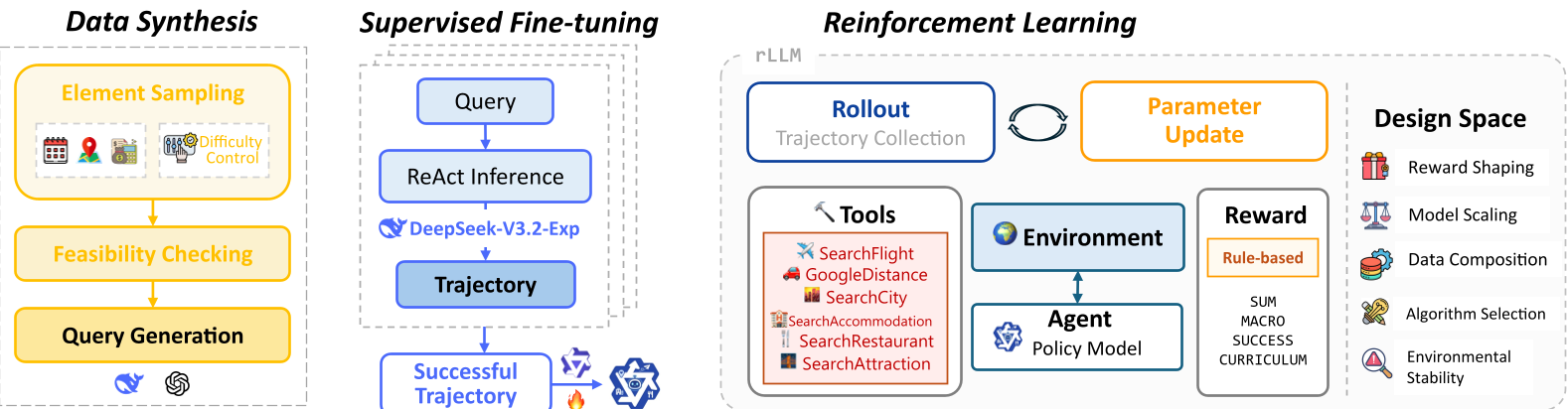
Methodology: The 5-Axis Decomposition
The STAR framework employs GRPO (Group Relative Policy Optimization), which eliminates the need for a separate value/critic model by normalizing rewards within a sampled group. The researchers analyzed five critical variables:
1. The Scale-Reward Paradox
The study discovered that reward design is scale-dependent.
- Small Models (1.5B) are "lost" in long trajectories. They require Curriculum Rewards (starting with dense feedback and gradually becoming sparse) to learn.
- Large Models (7B) have a high "internal prior." They can handle simple dense rewards directly and actually find complex curricula restrictive.
2. The Alignment Tax (OOD Generalization)
A fascinating insight is the Alignment Tax. If you train a model too hard on a specific task (using high-density rewards), its general performance on other tasks (like QA) drops.
- Optimal Balance: The
MACROreward (rewarding constraint satisfaction, not just any tiny step) kept OOD performance high while maintaining in-domain mastery.
3. Data "Sweet Spot"
More data is not always better for RL. The experiments showed that 1,000 training samples with a balanced difficulty mixture is the "sweet spot." Beyond 1K, notice the divergence: in-domain performance plateaus while Out-of-Domain (OOD) reasoning crashes due to overfitting.
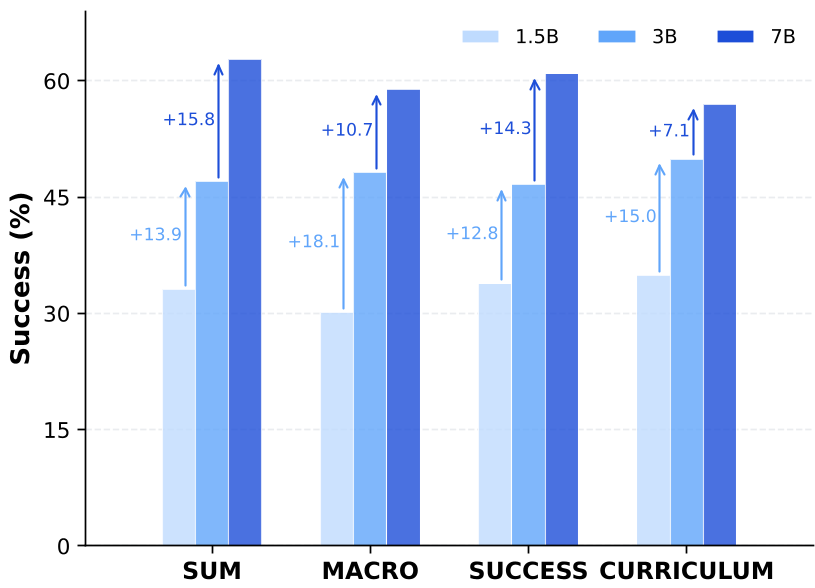
Experimental Results: Beating the Giants
Using the distilled recipe, the STAR-trained models achieved significant breakthroughs on TravelPlanner:
- 7B STAR-model: Achieved a success rate of ~63%, dwarfing Kimi-K2.5 (~12%) and even proprietary models.
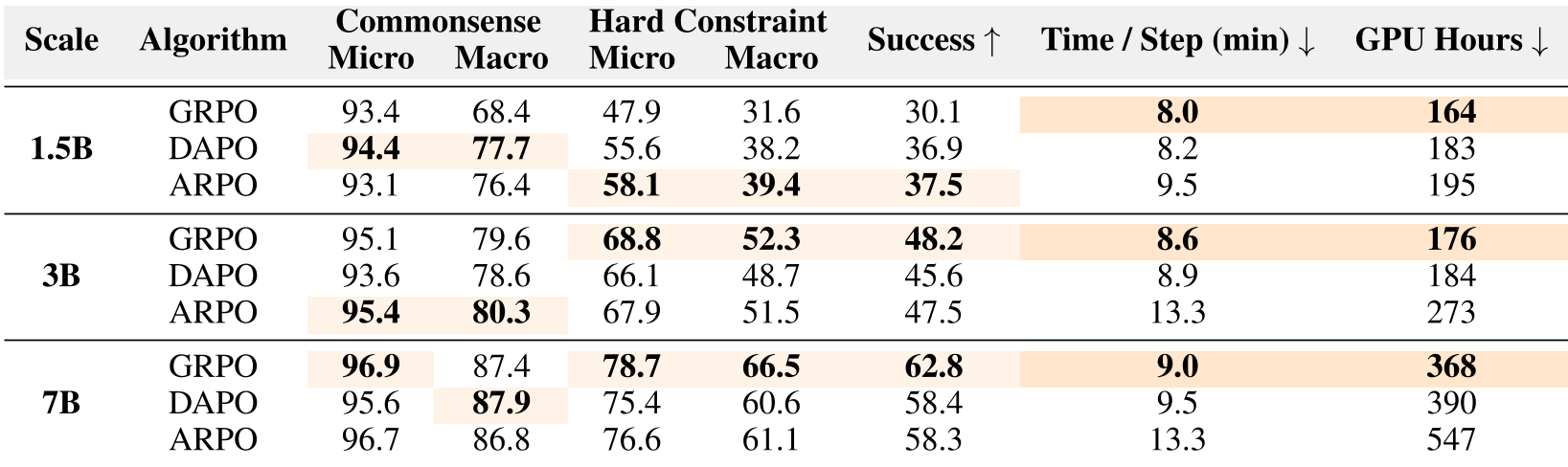
- Algorithm Efficiency: While exploration-heavy algorithms like ARPO helped small models, the standard GRPO was fastest and most effective for 7B models, suggesting that we should "invest in model capacity rather than complex heuristics" as we scale.
Critical Analysis: The Backtracking Bottleneck
Despite the success, the paper identifies a major wall for current LLM agents: Global Backtracking. In failure cases, if an agent selects a city and later finds no available hotels meeting the user's "Private Room + Party" constraint, it doesn't "backtrack" to change the city. instead, it "stubbornly proceeds" by picking an invalid hotel. This suggests that the next frontier for Agentic RL is not just better planning, but the ability to admit mistakes and re-plan globally.
Final Takeaway
The "Recipe" for 2026:
- Use 1K high-quality, mixed-difficulty prompts.
- For 7B+ models, keep it simple with Dense Rewards + GRPO.
- For small models, use Curriculum Shaping + Exploration Algorithms.
- Watch for the Alignment Tax—don't let your agent become a "one-trick pony."
STAR proves that with systematic RL, open-source small models can handle the complexity of "long-horizon agency" that previously required human-level intuition.