本文提出了 DiffusionAnything,一个统一的图像空间扩散策略框架,能够同时处理米级的机器人导航和厘米级的抓取前(Pre-grasp)动作规划。该模型通过多尺度 FiLM 条件化机制,在单一网络中实现了跨任务的端到端学习,且仅需每项任务 5 分钟的自监督数据。
TL;DR
机器人领域长期以来将“导航”(米级避障)与“操作”(厘米级精控)视为两个独立的课题。DiffusionAnything 提出了一种端到端的扩散策略(Diffusion Policy),通过多尺度 FiLM 条件化和轨迹对齐深度推理,仅用一台 RTX 4090 就在单一模型中实现了从走廊穿梭到精准抓取前规划的无缝切换。它不仅推理速度快(10 Hz),且在零样本泛化能力上完胜参数量巨大的 VLA 基础模型。
1. 痛点:臃肿的 VLA 与割裂的模块化架构
当前的机器人方案面临两难境地:
- VLA 模型(如 RT-2, GR00T):虽然具备语意推理能力,但参数量动辄数十亿,推理延迟使得高频控制几乎不可能。更糟的是,它们在陌生场景下的零样本表现往往由于缺乏显式几何推理而发生“灾难性遗忘”。
- 传统模块化方案:导航归导航,操作归操作。这种级联结构(Cascaded Architecture)会导致误差在不同任务模块间累积,且系统切换极其僵硬。
DiffusionAnything 的核心直觉是:无论导航还是操作,本质上都是图像空间到几何轨迹的映射。通过引入环境的物理直觉(如可通行性、注意力区域),可以用极轻量级的架构实现甚至超越基础模型的效果。
2. 核心架构:多尺度 FiLM 条件化与注意力引导
模型的核心是一个基于 UNet 的扩散决策策略。为了让同一个模型识别当前是该“远眺路面”还是“近看苹果”,作者设计了三个关键设计:
多尺度特征调节 (Multi-scale FiLM)
通过嵌入任务模式(Task Mode)、深度比例(Depth Scale)和空间注意力(Spatial Attention)组成的上下文向量 $c$,模型在 UNet 的不同尺度上进行线性调制。
- 导航模式:放大粗糙尺度特征(Coarse Scales),关注地面的可通行性。
- 抓取前模式:放大细微尺度特征(Fine Scales),聚焦于物体的质心和边缘。
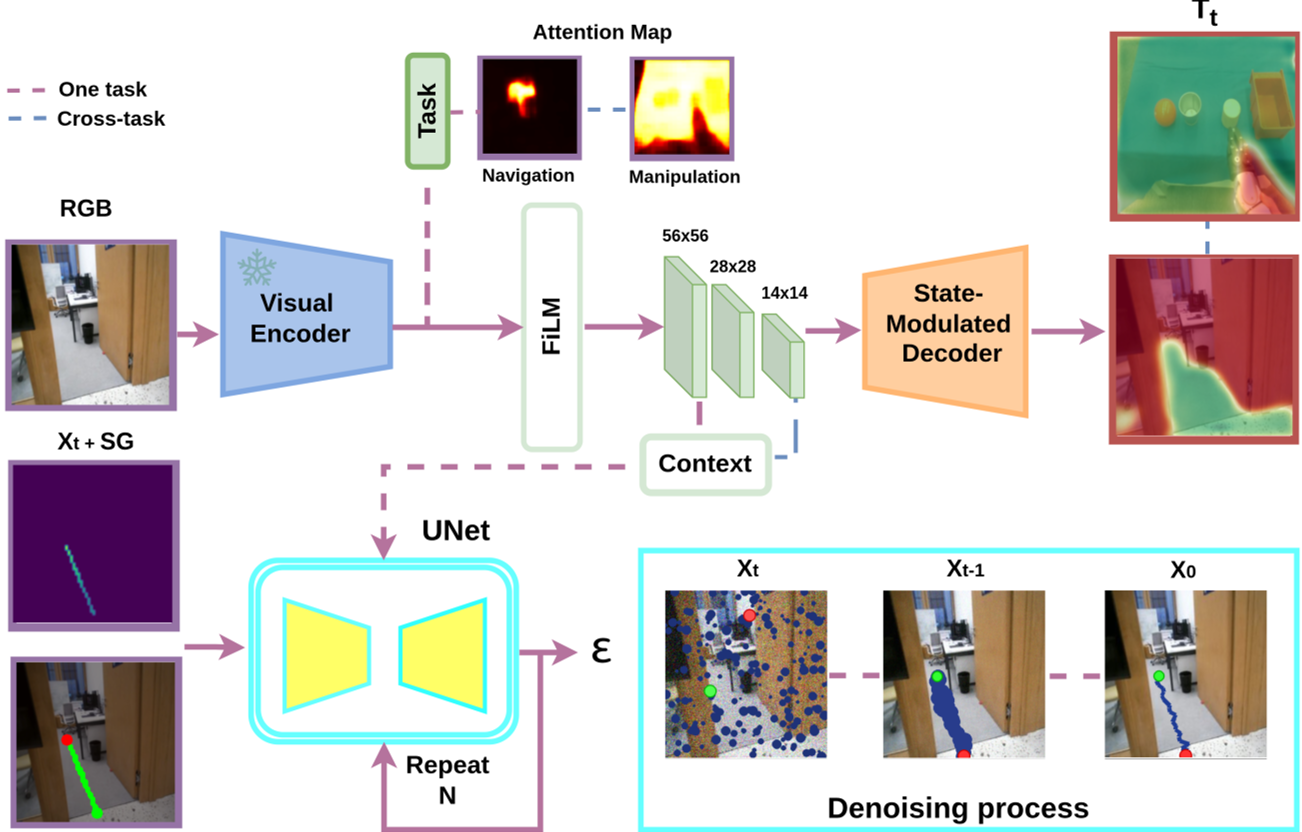
轨迹对齐的深度推理 (Trajectory-Aligned Depth)
为了避免计算全图深度图带来的巨大开销,DiffusionAnything 采用了按需推理策略:它只预测预测轨迹路径点上的深度值。这种设计让机器人能以极低的计算成本感知目标距离,确保了米级到厘米级的精度切换。
3. 实验表现:从“走廊”到“桌面”
在 Unitree G1 人型机器人上的实测数据令人惊艳:
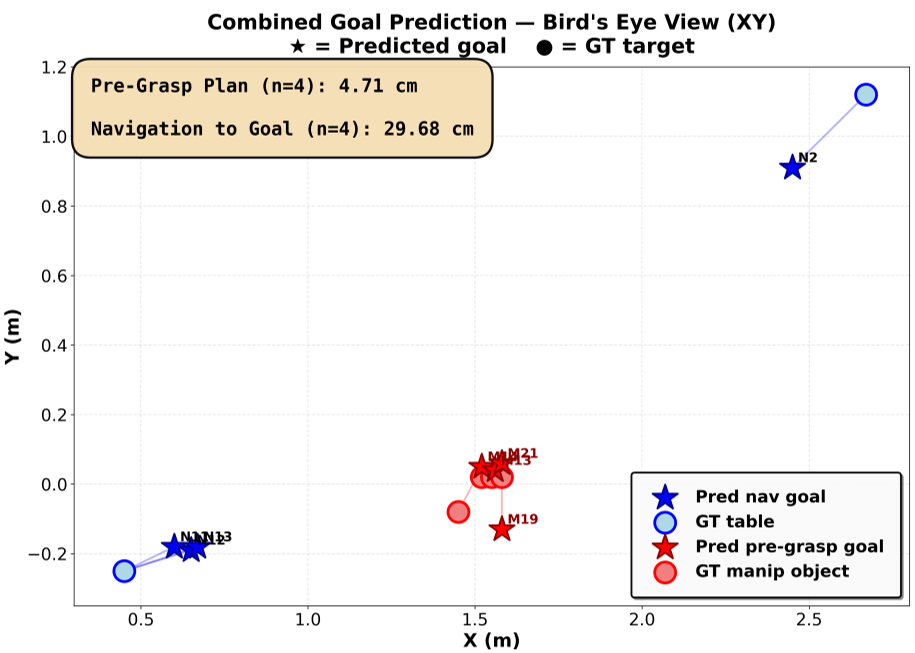
- 高精度切换:模型在抓取前规划任务中实现了 4.71 cm 的精度,相比导航任务的 29.68 cm 精度,通过深度比例条件化实现了 6 倍的性能增益。
- 极端数据的胜利:仅需 5 分钟 的任务相关数据。通过 AnyTraverse 自动生成伪标签,无需昂贵的人工演示。
- 对比 VLA 基础模型:在移动操作(Loco-manipulation)对比中,GR00T 在新场景下的成功率骤降至 30% 左右,而 DiffusionAnything 在新场景中依然保持了 100% 的避障成功率。
 上图展示了任务自适应的注意力切换:(a) 探索模式下关注地毯;(b) 导航模式下关注远端目标;(c) 抓取前模式下精准锁定物体细节。
上图展示了任务自适应的注意力切换:(a) 探索模式下关注地毯;(b) 导航模式下关注远端目标;(c) 抓取前模式下精准锁定物体细节。
4. 总结与深度洞察
DiffusionAnything 的成功不仅在于算法的优化,更在于其对机器人任务共性的深刻理解。
- 几何先验的价值:仅仅依靠端到端的语义学习是不够的。引入“可通行性”和“轨迹对齐深度”这种显式的几何推理,是提升零样本泛化能力的关键。
- 小即是美:在机器人领域,2GB 显存、10Hz 推理的高效小模型,往往比云端部署的巨型 VLA 模型更具实用价值。
局限性:目前该模型仍高度依赖 AnyTraverse 的自监督质量。未来如果能将执行后的闭环反馈(如碰撞或抓取失败)实时在线融入扩散策略的微调中,其生命周期管理将更具想象力。
关键词:Diffusion Policy, Robot Navigation, Pre-grasp Planning, Zero-shot Generalization, FiLM Conditioning.