本文提出了 dinov3.seg,这是一个基于 DINOv3 (dinov3.txt) 的开放词汇语义分割 (OVSS) 专用框架。通过引入双阶段特征细化、全局-局部文本集成及滑动窗口推理策略,该方法在 ADE20K、Pascal Context 等五个权威基准上刷新了 SOTA 记录。
TL;DR
开放词汇语义分割 (OVSS) 要求模型能识别训练集外从未见过的类别,这高度依赖视觉-语言模型 (VLM) 的泛化能力。本文推出的 dinov3.seg 摒弃了仅依赖 CLIP 全局特征的传统路线,立足于 DINOv3 强大的局部空间表达力,通过双阶段细化和全局-局部文本集成,在多个稠密预测基准上创造了新的 SOTA 记录,尤其是在处理高复杂度、多类别的凌乱场景中表现卓越。
核心痛点:全局语义与局部精度的“博弈”
目前的 OVSS 领域主要受 CLIP 类模型统治。然而,CLIP 的预训练目标是“图像-文本”级别的对比学习,这种 Inductive Bias 使得模型更倾向于理解“整张图是什么”,而在处理“这个像素属于哪个小物体”时却常常丢失细节,导致边界模糊或小物体漏检。
虽然近期出现的 dino.txt 通过对齐 DINOv2/v3 特征与文本编码器改善了局部性,但它本质上还是一个通用的视觉-语言模型,缺乏针对“分割任务”的感知优化。
架构解析:如何构建“分割感知”的 VLM?
dinov3.seg 的成功源于对底层特征的高效重构。其核心架构包含以下三个关键技术突破:
1. 双阶段细化 (Dual-Stage Refinement)
作者认为,单纯在最后对相似度图进行后处理是不够的,必须进行“前置增强”:
- 早期细化 (Early Refinement):在视觉特征与文本交互之前,利用基于
AnyUp的 Transformer 模块对 DINO 特征进行线性重组,提升特征的辨识度,同时确保不破坏原有的图像-文本对齐空间。 - 后期细化 (Late Refinement):在生成图像-文本相关性特征后,利用 SAM (Segment Anything Model) 提供的丰富先验,通过空间细化块(Spatial Refinement)和类别细化块(Class Refinement)进一步消除噪声。
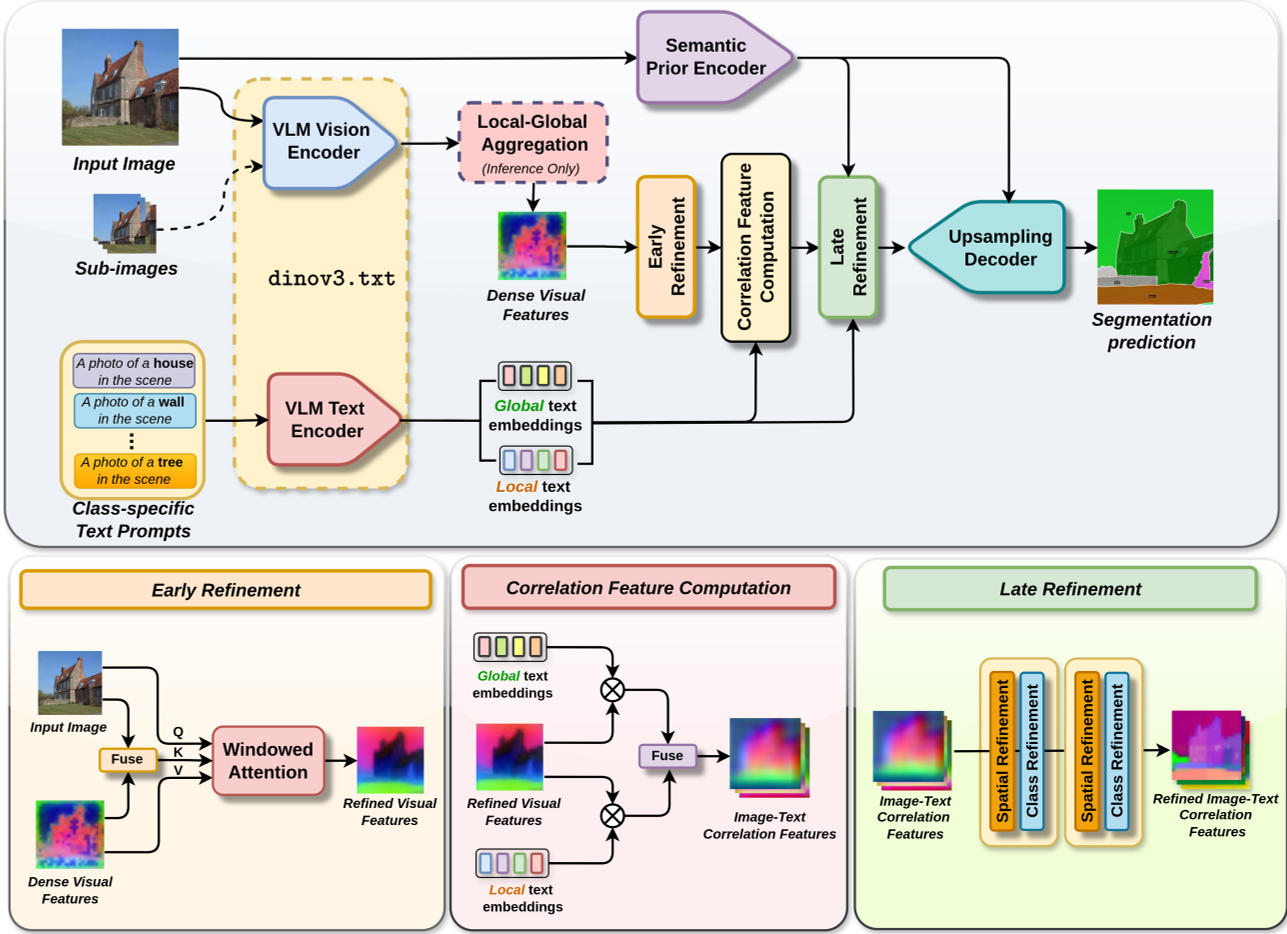
2. 全局-局部文本集成 (Textual Ensemble)
不同于前人只使用单一文本嵌入,本项目同时利用了与 [CLS] 令牌对齐的全局文本嵌入(捕获场景语境)和与 Patch 特征对齐的局部文本嵌入(捕获视觉细节)。这种互补性使得模型在面对如“楼梯”这种具有结构性部分的物体时,能更准确地匹配语义。
3. 滑动窗口聚合推理 (LGA Strategy)
针对高分辨率图像,dinov3.seg 采用了 Local-Global Aggregation (LGA)。它将图像切分为多个重叠子图进行编码,并与全局缩略图的特征进行加权融合。这确保了模型既有“上帝视角”的全局一致性,又能像素级地观察局部微小结构。
实验结果:无死角的性能碾压
在最具挑战性的 ADE20K (A-847) 细粒度数据集(包含 847 个类别)中,dinov3.seg 展现了惊人的泛化能力。
| 任务 | dinov3.seg (mIoU) | 提升幅度 (vs CAT-Seg) | | :--- | :--- | :--- | | A-847 (seen) | 43.07 | +4.39 | | A-847 (unseen) | 17.99 | +4.19 | | PC-459 (unseen)| 21.27 | +4.87 |

从可视化结果(Fig. 5)可以看出,相比于之前的 SOTA 方法(如 CAT-Seg),dinov3.seg 生成的掩码边缘更加锐利,特别是在“背景凌乱”或“物体交叠”的场景下,能够精准区分出细长物体和复杂的建筑结构。

深度洞察
- 参数量与效率的平衡:尽管 dinov3.seg 引入了庞大的 DINOv3 骨干网(总参数量 1.17B),但其计算效率极高,GFLOPs 仅为传统 OVSeg 的一半。这说明自监督预训练的骨干网络虽然“重”,但特征质量高,减少了冗余的计算。
- Unseen 类的跃迁:在 unseen 类别上的显著提升,证明了利用 DINO 系列这种自带“物体感知”属性的特征,比单纯用文本驱动的 CLIP 特征更有利于零样本场景。
总结
dinov3.seg 的出现标志着开放词汇分割进入了“精细化”时代。它不再满足于简单的跨模态匹配,而是致力于将基础模型的广度与语义细化的深度相结合。未来的研究方向可能会集中在如何通过知识蒸馏进一步压缩模型,使其在移动端机器人或自动驾驶边缘设备上实时运行。