本文提出了 DiReCT,一种针对流匹配 (Flow-matching) 视频生成模型的轻量级后期训练框架。通过引入解耦的对比正则化机制,该方法在不增加推理成本的前提下,显著提升了生成视频的物理常识一致性,在 WorldModelBench 榜单上超越了参数量大其数倍的模型。
TL;DR
尽管当前的视频生成模型(如 Sora, Wan 2.1)能拍出电影级大片,但它们经常让球穿过墙壁、让水向上流。本文提出的 DiReCT 框架通过一种巧妙的“找茬”式对比学习——即解耦对比正则化 (Disentangled Regularization of Contrastive Trajectories),在不增加模型规模的情况下,大幅强化了视频生成的物理真实性,刷新了多项物理评测榜单。
痛点深挖:为什么 AI 视频总是“不讲物理”?
目前的主流模型大多基于流匹配 (Flow-matching) 架构。其训练目标是回归每帧之间的“速度场”。但问题在于:
- 平均律陷阱:当模型遇到相似的描述时,它倾向于学习一种“平均速度”,导致动作变得平庸且模糊,失去了精准的物理碰撞或加速细节。
- 语义与物理的纠缠 (Semantic-Physics Entanglement):在文本提示词中,“一辆车在开”和“一辆车撞墙”语义极度接近,模型很难仅仅通过重建损失分辨出哪种轨迹是符合物理逻辑的。
- 梯度冲突:之前的对比学习方法(如 $\Delta$FM)随机选取负样本。但在视频领域,如果负样本语义太接近,对比梯度会直接与重建梯度“打架”,导致画面质量崩坏。
核心方法:DiReCT 的双尺度“炼金术”
为了解决上述冲突,作者提出了 DiReCT,它通过两个尺度的对比来强制模型区分物理轨迹:
1. 宏观对比 (Macro-Contrastive, MaNS)
利用语义聚类,强行拉开不同类别场景之间的距离。例如,生成“奔跑的人”时,绝对不拿“走路的人”做对比,而是拿“流动的云”做负样本。这确保了梯度是协同的,建立了全局的速度场结构。
2. 微观对比 (Micro-Contrastive, MiNS) —— 核心创新
这是本文的精华。作者利用 LLM(如 Qwen2.5)对物理规律进行粒子级“投毒”。
- 方法:保持场景描述完全一致,仅修改一个物理参数(如:将“弹性碰撞”改为“穿透”)。
- 效果:这创造了极难分辨的“硬负样本”。模型被迫在语义几乎相同的空间里,学会识别哪怕极其细微的物理违背(如重力加速度不对、材质硬度不对)。
 上图展示了 5 种物理扰动维度:动力学、力学、材质、交互、量级。
上图展示了 5 种物理扰动维度:动力学、力学、材质、交互、量级。
实验结果:小参数也能“智取”大模型
实验数据令人振奋。DiReCT 在仅有 1.3B 参数的情况下,在物理评测集 WorldModelBench 上的表现竟然超过了 10B 规模的 Mochi 和 5B 规模的 CogVideoX。
| 模型 | 参数量 | WorldModelBench 总分 (↑) | | :--- | :--- | :--- | | CogVideoX-5B | 5B | 5.33 | | Mochi-1 | 10B | 4.91 | | DiReCT (Ours) | 1.3B | 5.68 |
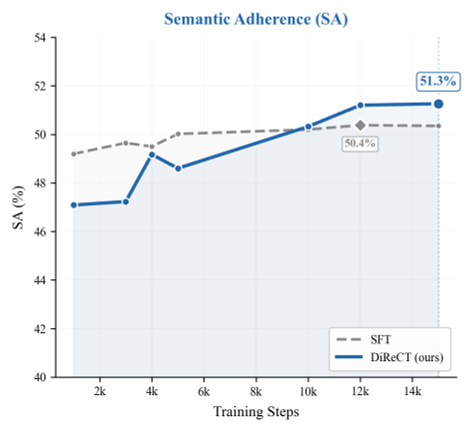 训练曲线显示:传统的 SFT(有监督微调)很快会陷入停滞,而 DiReCT 的物理感知信号能支撑模型持续进化。
训练曲线显示:传统的 SFT(有监督微调)很快会陷入停滞,而 DiReCT 的物理感知信号能支撑模型持续进化。
可视化分析:谁更懂物理?
在对比图中可以明显看到:
- 基线模型(如 LTX, CogVideoX):饼干浸入咖啡时会像液体一样溶化,或者勺子搅拌时直接穿过容器壁。
- DiReCT:物体保持了良好的结构完整性,搅拌和碰撞动作完全符合现实直觉。

总结与洞察
DiReCT 的成功告诉我们:视频生成模型的未来不在于无脑堆算力,而在于“高质量的裁判”。通过解耦语义与物理,并利用 LLM 生成精准的物理负反馈,我们可以在极小的模型代价下,获得极大的物理逻辑提升。
局限性:目前该方法依赖离线生成的视频作为负样本,且对 LLM 扰动提示词的质量有依赖。未来如果能实现端到端的实时物理梯度回传,视频生成将真正具备“世界模型”的潜质。