本文提出了 Dream Diffusion Policy (DDP),这是一种将扩散世界模型与扩散策略深度集成的视觉运动控制框架。通过共享 3D 视觉编码器,DDP 在 MetaWorld 等仿真环境和真实机器人任务中实现了卓越的 Out-of-Distribution (OOD) 鲁棒性。
TL;DR
机器人正在执行任务,突然有人把目标物体挪走或遮住摄像头,普通的 Diffusion Policy 会瞬间“降智”报错。慕尼黑工业大学(TUM)等机构提出的 Dream Diffusion Policy (DDP) 给出了一个充满哲学意味的解法:当现实不可靠时,闭上眼睛靠“想象”去完成动作。 DDP 在 MetaWorld 挑战中将 OOD 成功率从 23.9% 提升至 73.8%,在真机实验中更是实现了从 0 到 1 的质变。
痛点深挖:视觉流的“单一性危机”
当前的端到端动作克隆(Imitation Learning)方法本质上是在学习一种极其脆弱的统计映射:即“看到 A,执行 B”。
- 短板:一旦环境发生训练集未见的剧烈变动(Covariate Shift),比如相机被遮挡或物体被瞬移,输入特征空间会彻底崩溃。
- 主流解法的局限:传统的 Domain Randomization(领域随机化)只能增强小范围扰动的抗性,而无法处理本质的逻辑断层;如果完全依赖强化学习重训练,又会导致专家演示的精细技能流失。
核心直觉(Insight):人类在运动控制中具备**“动力学直觉”**。如果你在拿杯子时突然停电,你的大脑会根据记忆和肌肉感觉预测杯子的位置。DDP 的目标就是为机器人构建这种“预测性直觉”。
方法论详解:共享编码与预测性想象
DDP 的精髓在于将 Diffusion Policy(策略)与 Diffusion World Model(世界模型)进行了“骨肉相连”级的耦合。
1. 架构协同:3D 共享编码器
DDP 采用基于点云的 3D 表示(继承自 DP3),通过一个共享的 3D 编码器 $E_\psi$ 提取几何潜向量。
- 策略端:负责根据历史观测 $O_{0..M-1}$ 去除噪声,输出动作序列 $a$。
- 世界模型端:负责根据历史观测和当前计划的动作,预测未来的观测潜向量 $O_{M..M+N-1}$。
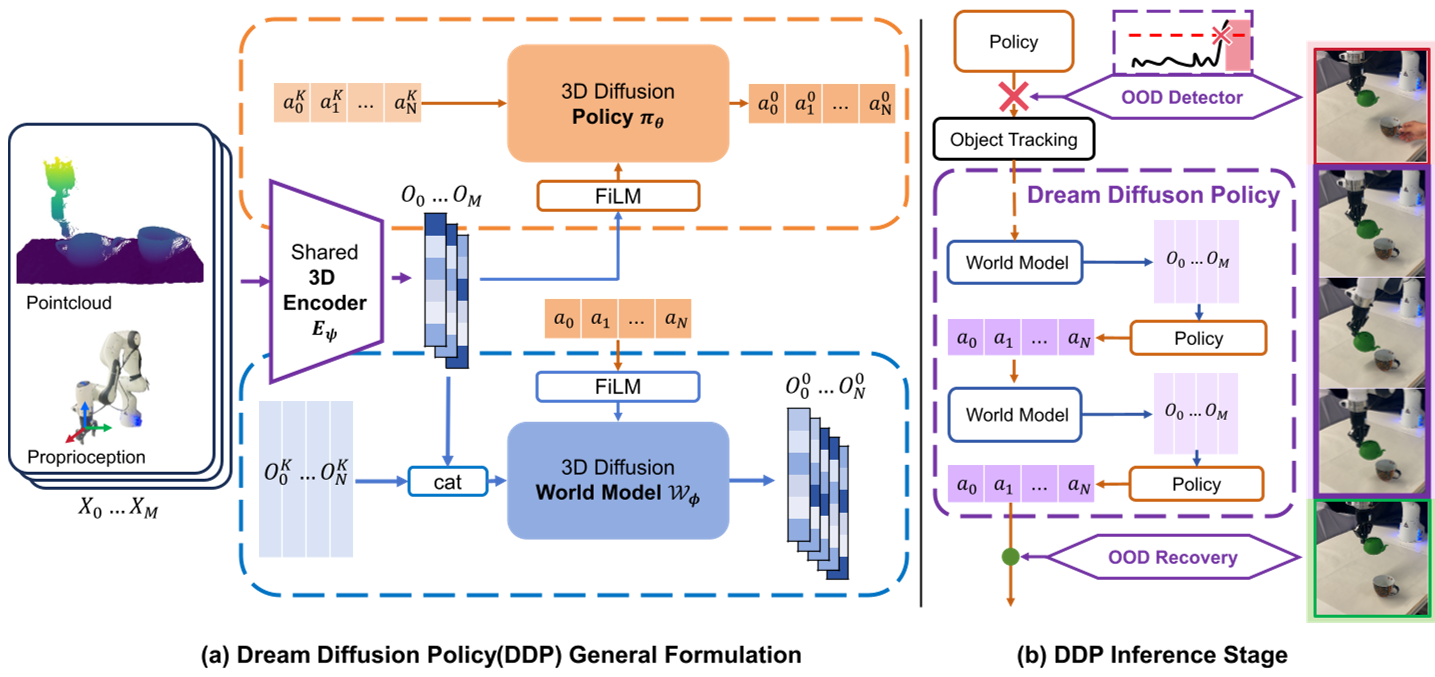
2. OOD 检测器:现实与想象的缝隙
如何知道视觉坏了?DDP 计算了一个 DR-I Discrepancy(真假差异): $$ \mathcal {D} _ {R - I} (t) = | \mathbf {O} _ {real} ^ {t} - \mathbf {O} _ {pred} ^ {t} | _ {2} ^ {2} $$ 当真实观测坐标和世界模型预测的差距超过阈值时,系统自动切换至 OOD Mode。
3. 递归想象:核心补救机制
一旦进入 OOD 模式,DDP 会启动一个“闭环想象轮转”:
- 主动追踪:利用 6D 姿态估计修正物体瞬移的位移偏差。
- 放弃现实:完全断开不可靠的相机输入。
- 自回归生成:策略基于世界模型上一时刻预测的“虚假”潜向量来生成动作,世界模型再根据动作预测下一时刻。这种“内循环”确保了在失去视觉时,动作依然具有物理一致性。
实验与结果:震撼的“盲操”能力
仿真战绩 (MetaWorld & Adroit)
在 10 项 MetaWorld 任务中,DDP 的表现降维打击了传统的基线模型。
| 算法 | 总平均成功率 (ID) | 总平均成功率 (OOD) | | :--- | :---: | :---: | | DP3 (SOTA 基线) | 89.8% | 0.8% | | DDP (Ours) | 89.5% | 73.8% |
注:在 Adroit 高自由度任务中,加入世界模型后成功率反而提升了,这说明世界模型起到了“时间平滑器”的作用。
真实机器人实验
研究者在 Franka Panda 机器人上测试了:按按钮、倒茶、叠方块。
- 视觉遮挡挑战:在倒茶动作中遮住摄像头,DDP 依然能够凭借“潜空间想象”准确对准杯口。
- 开环测试:在仅给第一帧观测的情况下,DDP 的“纯想象”执行成功率高达 76.7%,展示了极强的动态演化稳定性。
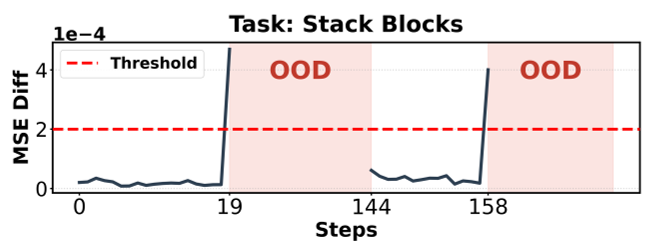 图:DR-I 差异在物体被挪动瞬间产生尖峰,精准触发 OOD 防御机制。
图:DR-I 差异在物体被挪动瞬间产生尖峰,精准触发 OOD 防御机制。
深度洞察与总结
为什么 DDP 如此有效?
- 不仅仅是正则化:很多工作只把世界模型当辅助 Loss,而 DDP 在推理阶段将其作为“数据源”。
- 几何先验的价值:使用点云而非 RGB 图像,使得世界模型学习物理动力学变得更容易,因为它不需要处理复杂的光影,只需预测物体结构的位移。
局限性与未来展望
虽然 DDP 表现强悍,但它目前仍依赖于一个外部的 6D Pose 追踪模块来进行起始点的重新对齐。如果追踪发生漂移,长时间的想象最终还是会偏离物理真实。
结论:DDP 指明了未来具身智能的方向——一个优秀的 Policy 必须首先是一个优秀的物理世界模拟器。只有学会了“做梦(Dreaming)”,机器人才能在混乱的真实场景中保持清醒。