本文提出了 DreamPlan,一个通过视频世界模型(Video World Models)对视觉语言规划器(VLM Planners)进行强化学习微调的框架。该方法利用零样本(Zero-shot)VLM 搜集的亚策略数据训练动作条件视频生成模型,并结合 ORPO 算法在虚拟“想象”中完成策略进化,显著提升了机器人在操纵变形物体(如布料、绳索)时的物理落地能力。
TL;DR
视觉语言模型(VLM)虽然在大脑(语义推理)上很强,但在四肢(物理执行)上往往显得“手残”,尤其是在面对折叠布料、拉直绳索等涉及复杂动力学的变形物体时。DreamPlan 提出了一种高效的强化微调方案:先让 VLM 乱试(搜集数据),再用视频扩散模型学会物理规律(建立世界模型),最后在“想象”中通过几率比策略优化(ORPO)自愈。结果显示,它在不依赖大规模实机交互的情况下,将操纵成功率直接翻倍。
1. 背景定位:为什么 VLM 玩不转“变形金刚”?
在具身智能(Embodied AI)领域,直接用预训练的 VLM(如 Qwen-VL, GPT-4O)做规划已不新鲜。然而,这些模型大多是在互联网图文数据上训练的,它们知道“要把布铺平”,但不知道“以什么角度捏住哪个点能让布不缩成一团”。
这种**物理落地(Physical Grounding)**的缺失在操纵变形物体(Deformable Objects)时尤为致命。传统方案要么靠大量专家演示(极其昂贵),要么靠物理仿真器(仿真与现实之间存在巨大的 Sim-to-Real Gap)。那么,能不能让模型自己通过“看视频”学会物理,并在脑海里“预演”正确动作?
2. 核心挑战与直觉
作者发现了一个有趣的现象:即便零样本(Zero-shot)的 VLM 表现很烂,它失败的过程也蕴含了宝贵的“因果律”——动作执行后,物体是怎么变的?
DreamPlan 的核心 Insight 是:利用这些亚策略(Sub-optimal)的交互数据训练一个动作条件视频模型。既然我们造不出完美的动力学公式,那就让深度学习模型去通过视觉特征“模拟”物体的物理形变。
3. 方法论详解:从“乱动”到“预演”
3.1 动作条件的视频生成
普通的视频生成如 Sora 或 CogVideoX 很难精确遵循机器人的指令。DreamPlan 引入了 ControlNet 架构:
- 渲染轨迹:将机器人手臂的运动学配置渲染成简单的视频流。
- 结构化注入:作为 ControlNet 的输入,强制引导视频扩散模型生成与机器人动作严格对齐的物体形变。
- 背景剥离:只预测目标物体的局部裁剪视频,避免背景和光照干扰,让模型专注于“形变”本身。
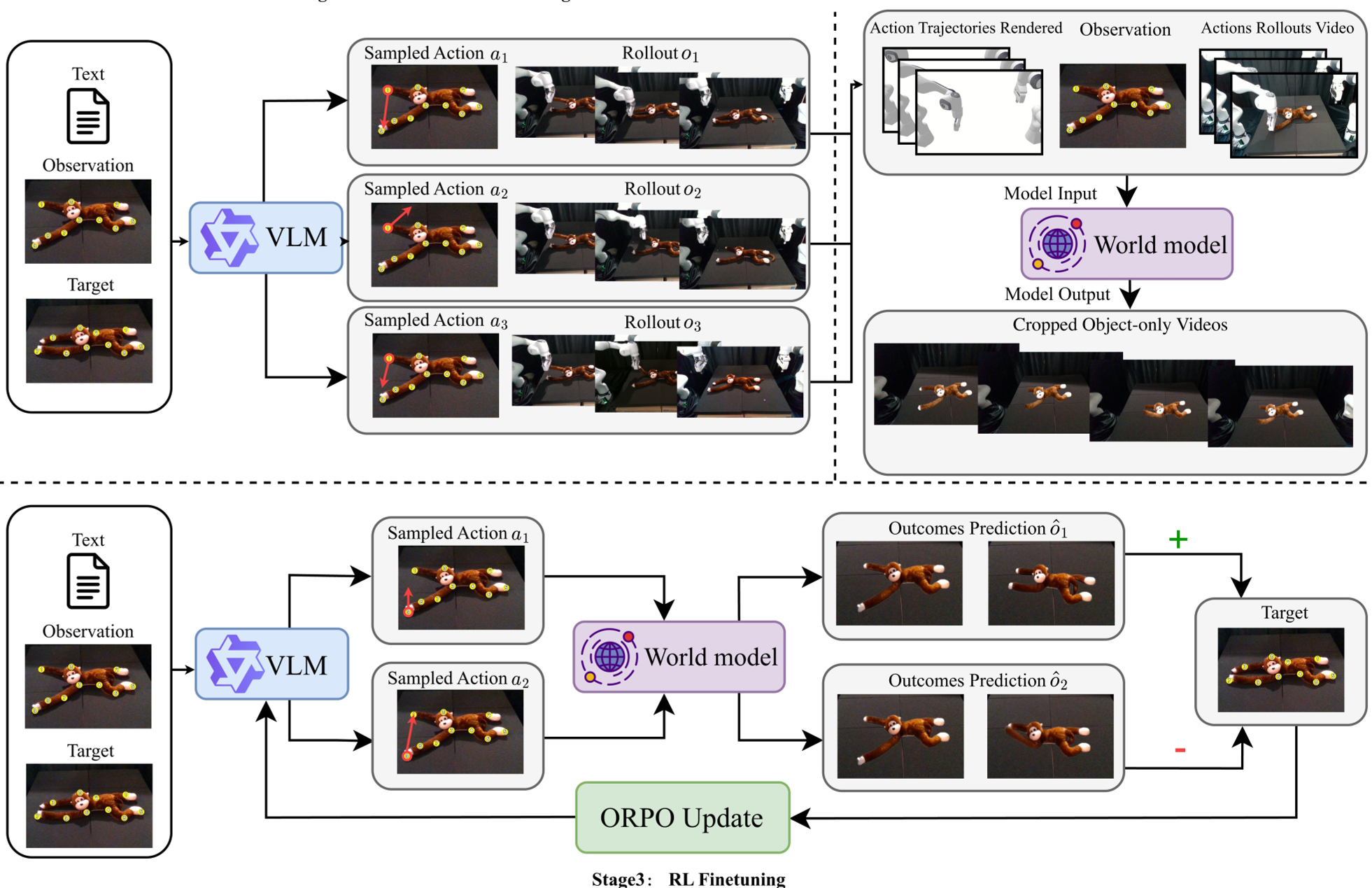
3.2 离线强化学习:ORPO 带来的效率革命
如果每次模型规划都要生成一段视频,那由于扩散模型推理慢,机器人决策会比树懒还慢。DreamPlan 巧妙地采用了 Best-of-K 策略:
- 离线评估:对于每个状态,VLM 同时生成 K 个候选动作,世界模型预测每个动作的视频后果,由 GPT-4O 打分找出最好的。
- 偏好学习:利用 ORPO (Odds Ratio Policy Optimization) 算法,直接在对比中训练 VLM。这使得 VLM 在微调后,看到图像就能直接内化物理直觉,“盲选”出最高概率成功的动作,而不再需要实时运行复杂的视频模型。
4. 实验战绩:全线碾压零样本基线
在绳索拉直、布料折叠和玩具重定位三个高难度任务中,DreamPlan 展现了恐怖的适应力。
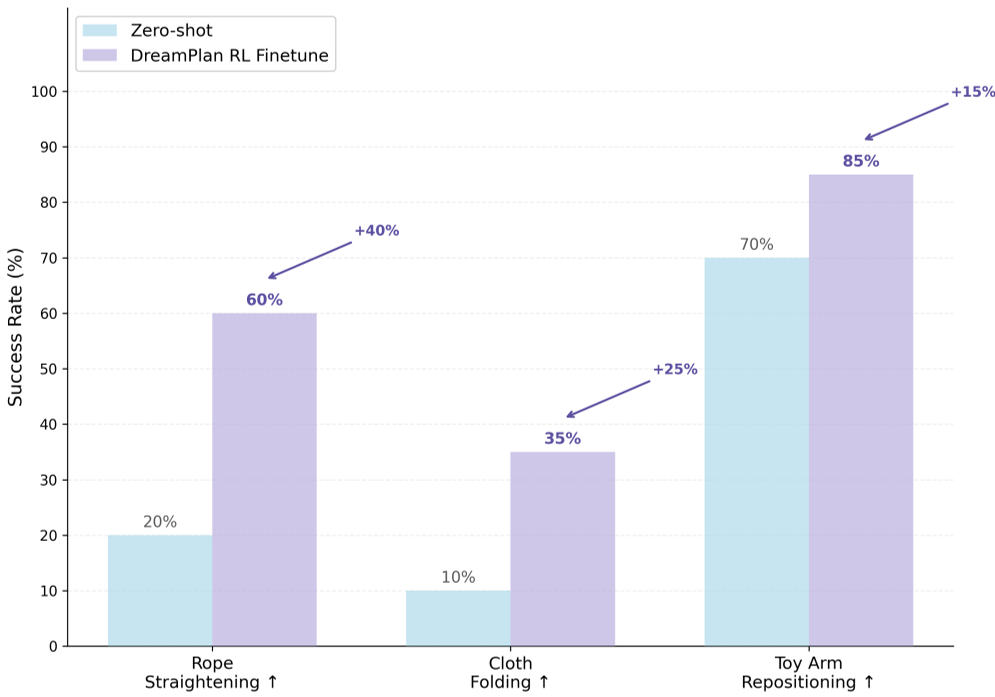
- 性能飞跃:在 Qwen3-VL-8B 基础上,平均得分从 0.33 飙升至 0.60。
- 跨级挑战:仅 8B 参数的 DreamPlan 甚至击败了没有经过物理微调的 32B 模型(0.35分)和 GPT-4O。
- 效率对比:推理时间从采样方案的近 1000 秒压缩到 1.12 秒,推理效率提升约 1000 倍。
 图中绿色边框显示了微调后模型精准的物理操作(如绳索拉直),而粉色边框则显示了原始 VLM 无效的各种瞎忙。
图中绿色边框显示了微调后模型精准的物理操作(如绳索拉直),而粉色边框则显示了原始 VLM 无效的各种瞎忙。
5. 深度洞察与总结
总结 (Takeaway): DreamPlan 的价值在于它证明了视频生成模型就是未来的物理仿真器。通过将昂贵的视频生成过程“蒸馏”进轻量级的文本/图像模型中,我们可以让 VLM 这种“纯智力”模型真正习得“物理常识”。
局限性 (Limitations):
- 视野受限:目前主要依赖局部裁剪视图,无法处理更大规模或受遮挡严重的复杂场景。
- 动作原子性:目前的动作还基于离散的 Keypoints 采样,对于更精细、连续的力矩控制还有待进一步拓展。
未来展望: 随着大规模视频生成技术(如 Sora 级模型)的普及,将视频作为“通用世界模型”来微调具身智能模型可能成为 SOTA 路径。未来的机器人可能不再需要在仿真器里苦练,而是在观看、模拟和自我微调中,习得操纵万物的能力。