本文提出了 Drive My Way (DMW),这是一个个性化的视觉-语言-动作 (VLA) 驾驶框架。该方法通过学习用户嵌入 (User Embedding) 来对齐长期驾驶习惯,并结合自然语言指令实现实时风格调整,在 Bench2Drive 闭环仿真中实现了 SOTA 的个性化表现。
TL;DR
传统的自动驾驶往往是“千人一面”的模板化操作。来自 UC Riverside 等机构的研究者提出了 Drive My Way (DMW),这是首个能够同时兼顾驱动长期驾驶习惯(通过用户画像)与短期实时意图(通过自然语言指令)的视觉-语言-动作 (VLA) 框架。它不仅能听懂“我赶时间”,还能通过学习你过去的开车习惯,模仿你独特的驾驶风格。
核心痛点:为什么自动驾驶总是开得像个“机器人”?
现有的自动驾驶系统,无论多么智能,往往面临两个尴尬境地:
- 缺乏个性化 (Personalization):系统预设的模式太死板,无法像人类司机那样在“激进”与“保守”之间通过细微的加速、刹车频率来体现个人风格。
- 交互脱节:当你告诉车子“我有点累了”时,目前的 VLA 模型往往无法将其转化为具体的物理操作(如增加跟车距离、减缓过弯速度)。
方法论:长期对齐 + 短期适配的“双轨”架构
DMW 的核心逻辑在于将驾驶风格拆解为“江山易改”的短期情绪和“本性难移”的长期习惯。
1. 长期偏好编码 (Long-term Alignment)
作者构建了一个包含 30 名真实人类驱动的个性化驾驶数据集 (PDD)。通过对比学习 (Contrastive Learning),模型学习如何将用户的文本画像(如“拥有 10 年驾龄的通勤者”)与其实际驾驶轨迹(速度分布、横向控制习惯)映射到同一个嵌入空间。
2. VLA 骨干与残差解码器
DMW 基于 SimLingo 架构,利用 InternVL2 处理视觉信息。为了实现灵动的风格化操作,模型不直接修改基础路径规划,而是设计了一个残差解码器 (Residual Decoder)。这个解码器会输出一个“偏置值”,在保证安全基线的前提下,对车速和转向进行微调。
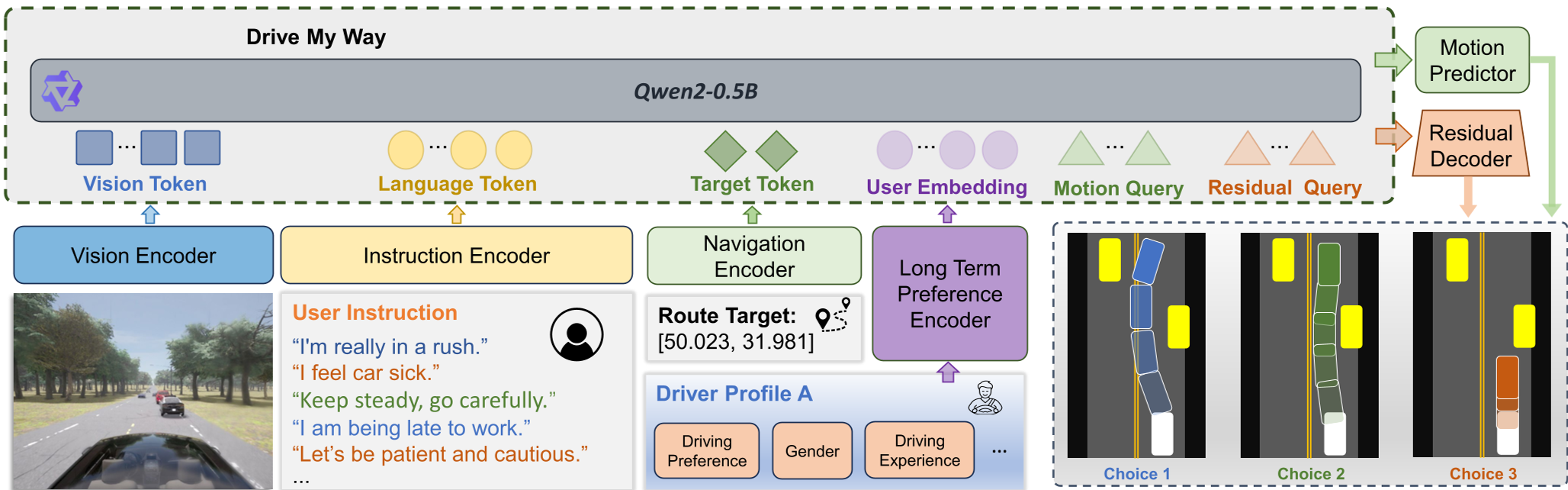
3. 强化学习精调 (GRPO Alignment)
为了让指令真的“落地”,研究者引入了 GRPO (Group Relative Policy Optimization) 算法。通过根据指令风格动态调整奖励函数权重(例如:激进指令下增加 Efficiency 权重,降低 TTC 阈值),模型学会了在安全、效率和舒适度之间进行权衡。
实验战绩:它真的学会了你的风格吗?
在 Bench2Drive 的闭环测试中,DMW 展现出了极强的风格敏感性:
- 效率飞跃:在 aggressive(激进)指令下,DMW 的效率提升了 18.77%,远超原始 SimLingo 的 3.70%。
- 行为一致性:实验数据显示,针对不同驾驶员画像,模型生成的车速、加速度和跟车距离呈现出极显著的统计学差异,成功还原了人类司机的本色。

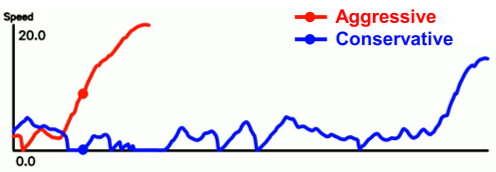
在可视化分析中(见下图),面对障碍物,激进模式的 DMW 会果断变道超车(红线),而保守模式则会选择减速避让(蓝线)。这种基于语义理解的决策差异,正是 DMW 的精髓所在。
深度洞察与总结
DMW 的成功在于它意识到:个性化不是简单的参数调节,而是一种语义到物理空间的非线性映射。
局限性: 尽管在 CARLA 仿真环境下效果惊艳,但从仿真到现实 (Sim-to-Real) 的迁移仍面临挑战,尤其是真实世界中复杂交通流的不可预测性。
未来启示: 随着大模型的进化,未来的自动驾驶将不再是一个冰冷的控制器,而是一个能够共享人类驾驶意识、理解含蓄表达的数字伴侣(Human-centered Driving)。