本文提出了 DriveVLM-RL,一种受神经科学启发的自动驾驶强化学习(RL)框架。该框架利用视觉语言模型(VLM)构建双通路(Static & Dynamic)奖励机制,通过语义风险推理引导安全驾驶,在 CARLA 模拟器中实现了 SOTA 性能,并解决了 VLM 推理延迟导致的实时部署难题。
TL;DR
DriveVLM-RL 是一项突破性的自动驾驶研究,它通过模拟人脑的“习惯性”与“审慎性”双重认知处理机制,创新性地将视觉语言模型(VLM)集成到强化学习(RL)中。该框架通过异步语义奖励标记,既利用了 VLM 强大的长尾场景推理能力,又规避了其高延迟的致命缺陷。在 CARLA 模拟器中,它不仅刷写了 SOTA 战绩,更证明了 LLM/VLM 可以在“无碰撞惩罚”的情况下教出极其安全的 AI 驾驶员。
1. 痛点:为什么传统的自动驾驶 RL “既慢又笨”?
强化学习在自动驾驶领域一直面临几个核心挑战:
- 碰撞代价昂贵:传统 RL 需要通过不断的碰撞(Negative Reinforcement)来学习安全,这在现实世界中是绝对不可接受的。
- 手动奖励函数难以泛化:人类工程师很难用代码写清“行人稍微移动了一步”和“行人准备横穿马路”之间微妙的语义差别。
- 延迟与智能的矛盾:直接用大型 VLM(如 GPT-4, Qwen-VL)控制车辆虽然聪明,但 1 秒左右的推理延迟会导致车辆早已失控。
DriveVLM-RL 的核心动机是:把 VLM 当做老师(提供语义奖励),而不是当做司机(直接输出控制指令)。
2. 核心机理:神经科学启发的双通路架构
作者从人类大脑处理视觉信息的过程中汲取灵感:我们平时开车大多数时间是靠“习惯性反射”(顶叶皮层处理),只有遇到复杂或突发状况时,才会动用高能耗的“逻辑推理”(前额叶皮层)。
2.1 架构拆解
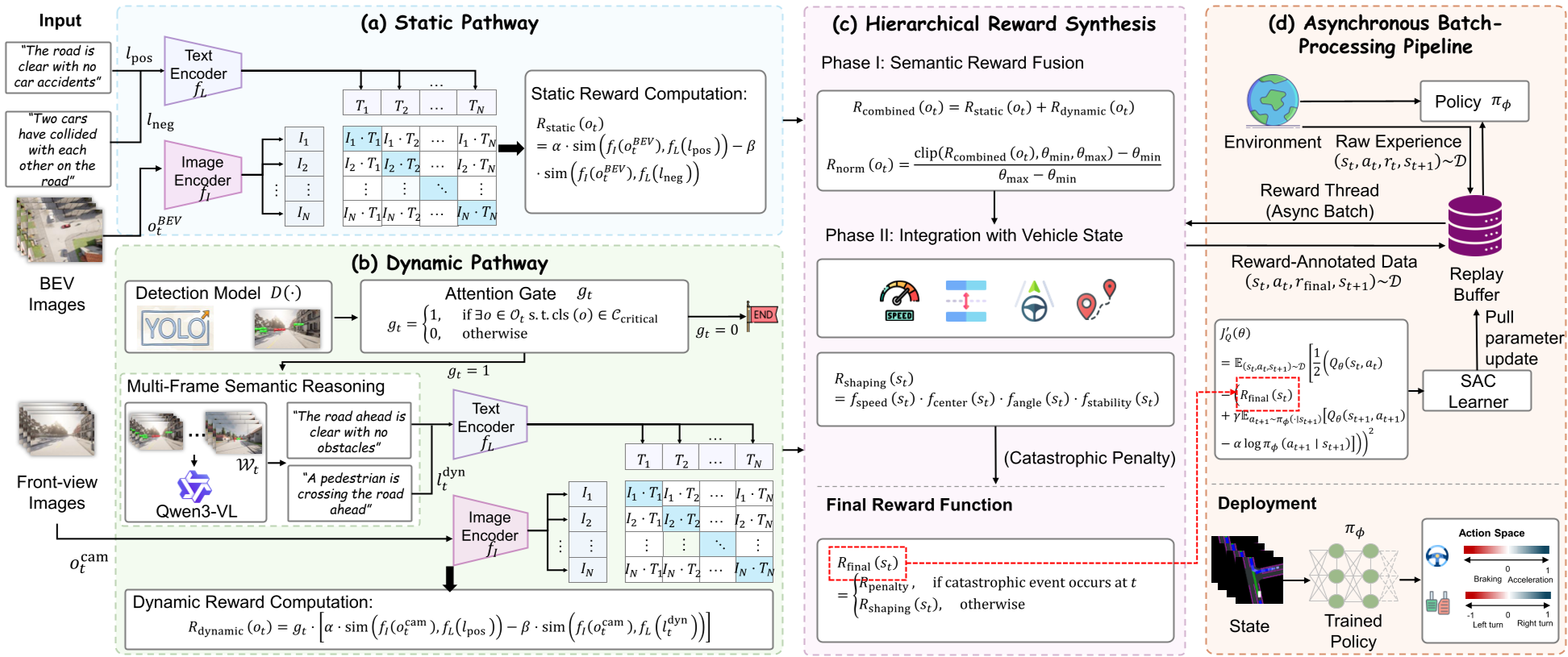
- 静态通路 (Static Pathway):
- 输入:BEV 鸟瞰图。
- 机制:利用 CLIP 计算当前场景与“道路顺畅”对比“发生事故”的文字语义相似度,提供持续的、基础的空间安全信号。
- 动态通路 (Dynamic Pathway) - 核心创新点:
- 注意门控 (Attentional Gate):由 YOLOv8m 组成。只有看到行人、自行车、动物等“安全关键目标”时,才会唤醒昂贵的 LVLM。
- 语义推理:LVLM(如 Qwen3-VL-4B)对多帧图像进行分析,生成如“一名行人在 ego 车道前方乱穿马路”的描述,并将其转化为动态奖励。
- 分层奖励合成 (Hierarchical Reward Synthesis):
- 将语义得分与车辆状态(车速轨迹跟随、车道居中度、平顺性)进行乘法融合(Multiplicative Composition),有效防止了“语义上安全但实际上违规”的 Reward Hacking 行为。
3. 异步训练:解决 2000ms 推理延迟的银弹
为了不让 VLM 拖慢 RL 训练速度,DriveVLM-RL 采用了异步流水线(Asynchronous Pipeline):
- 交互线程:SAC 智能体以最高速度采集环境数据存入 Buffer。
- 奖励线程:独立的 Worker 不断从 Buffer 里拿数据给 VLM 打分,更新 Reward 占位符。
- 学习线程:只有标记好 Reward 的转场数据才会被用于更新策略梯度。
最关键的部署优势:当模型练成后,所有的 VLM 和检测器全部丢掉,部署的只是一个通过语义“耳濡目染”熏陶出来的轻量级 Policy Network,推理延迟忽略不计。
4. 实验结果:语义推理能否替代碰撞惩罚?
研究团队在 CARLA Town 2 进行训练,并在多个未见过的城镇(Town 1, 3, 4, 5)进行了泛化性测试。
4.1 SOTA 对比
 在与 13 种基线方法(包括专家设计、LLM 代码生成、机器人 VLM 奖励法)的对比中,DriveVLM-RL 在保持高车速(25.10 km/h)的同时,将碰撞率(CR)降至 0.126。
在与 13 种基线方法(包括专家设计、LLM 代码生成、机器人 VLM 奖励法)的对比中,DriveVLM-RL 在保持高车速(25.10 km/h)的同时,将碰撞率(CR)降至 0.126。
4.2 “无碰撞惩罚”生存挑战
这是本论文最惊人的实验:如果把环境反馈的碰撞惩罚全部设为 0,模型还能学会避开危险吗?
- 结论:DriveVLM-RL 依然表现强劲,累计碰撞数比对比基线低 67%。
- 直觉解释:因为动态通路时刻在告诉 AI “前面有人,不安全”,通过语义相似度产生的负向奖励让 AI 在真正撞上去之前就学会了恐惧感。
5. 深度洞察与总结
DriveVLM-RL 代表了自动驾驶领域的一个重要转向:从“几何感知”走向“语义认知”。
优势总结 (Strengths):
- 可部署性:解决了端到端自动驾驶中基础模型(Foundation Model)推理太慢的痼疾。
- 安全性:通过前瞻性的语义评价,让 RL 具备了预测风险的能力,而不仅仅是事后总结。
局限性与展望 (Limitations & Future Work):
- 跨场景泛化:虽然在城镇道路表现优异,但在结构迥异的高速公路或多层复杂立交桥场景中,当前的语义词汇表仍显单薄。
- Sim-to-Real:论文工作目前集中在仿真器,未来如何应对真实传感器的噪声和视觉领域漂移(Domain Shift)仍需进一步验证。
DriveVLM-RL 不仅仅是一个算法框架,它更像是一套“教育大纲”,指引着未来的自动驾驶系统如何从互联网规模的视觉语言知识中汲取真正的“驾驶智慧”。