本文提出了 DROID-W,一个鲁棒的实时单目 RGB SLAM 系统,通过引入可微的“不确定性感知捆集调整”(UBA)来解决动态环境下的定位与建图难题。该系统在多个具有挑战性的真实世界数据集上达到了 SOTA 的相机位姿精度与场景几何重建质量。
TL;DR
在自动驾驶和机器人领域,SLAM 系统常因“动”而困:移动的人、车、甚至是晃动的门都会干扰相机的定位。DROID-W 通过在经典的 DROID-SLAM 中融入像素级动态不确定性估计,利用 DINOv2 特征的跨视图一致性来识别并屏蔽干扰。它不仅在学术测试集上刷榜,更在野外(In the Wild)环境和杂乱的 YouTube 视频中展现了惊人的实时鲁棒性。
核心痛点:为什么传统的静态假设不再奏效?
大多数 SLAM 系统(如 ORB-SLAM2, DROID-SLAM)构建在“静态世界”假设之上。当画面中出现移动物体时,重投影误差(Reprojection Error)会急剧增大,导致后端优化(Bundle Adjustment, BA)被这些错误的“噪点”主导,进而产生轨迹漂移或建图崩塌。
现有的动态 SLAM 解决思路通常分为两类:
- 语义遮罩法:预先训练检测器过滤“人、车、狗”等物体。缺点是:没见过的动态物体(如飘动的布料、移动的雕塑)依然会造成干扰。
- 不确定性建模:如 WildGS-SLAM,依赖于高质量的几何地图来反向学习不确定性。缺点是:如果地图本身在杂乱场景中建坏了,不确定性估计也会跟着失效。
DROID-W 的技术直觉:多视图特征一致性
作者认为:优秀的动态感知不应该依赖于完美的几何,而应该依赖于稳健的视觉特征。
1. 不确定性感知 BA (Uncertainty-aware BA)
DROID-W 修改了 DROID-SLAM 的优化目标函数。它为每个像素 $t$ 引入了一个动态不确定性项 $u_t$。在最小化马氏距离时, $u_t$ 作为权重项: $$ \pmb {\Sigma} _ {i j} ^ {\mathrm {u n c e r}} = \mathrm {d i a g} \left(\mathbf {w} _ {i j} \cdot \frac {1}{\mathbf {u} _ {i} ^ {\prime}}\right) $$ 这意味着,系统会自动“无视”那些不确定性高的区域。
2. 基于 DINOv2 的不确定性优化
为了计算 $u_t$,作者利用了 DINOv2 特征的语义高度一致性。当相机从位置 $i$ 移动到 $j$ 时,静态场景的特征应该能通过单应性或刚体变换完美匹配。如果匹配不上(特征相似度低),则判定该点为动态点,增加其不确定性。
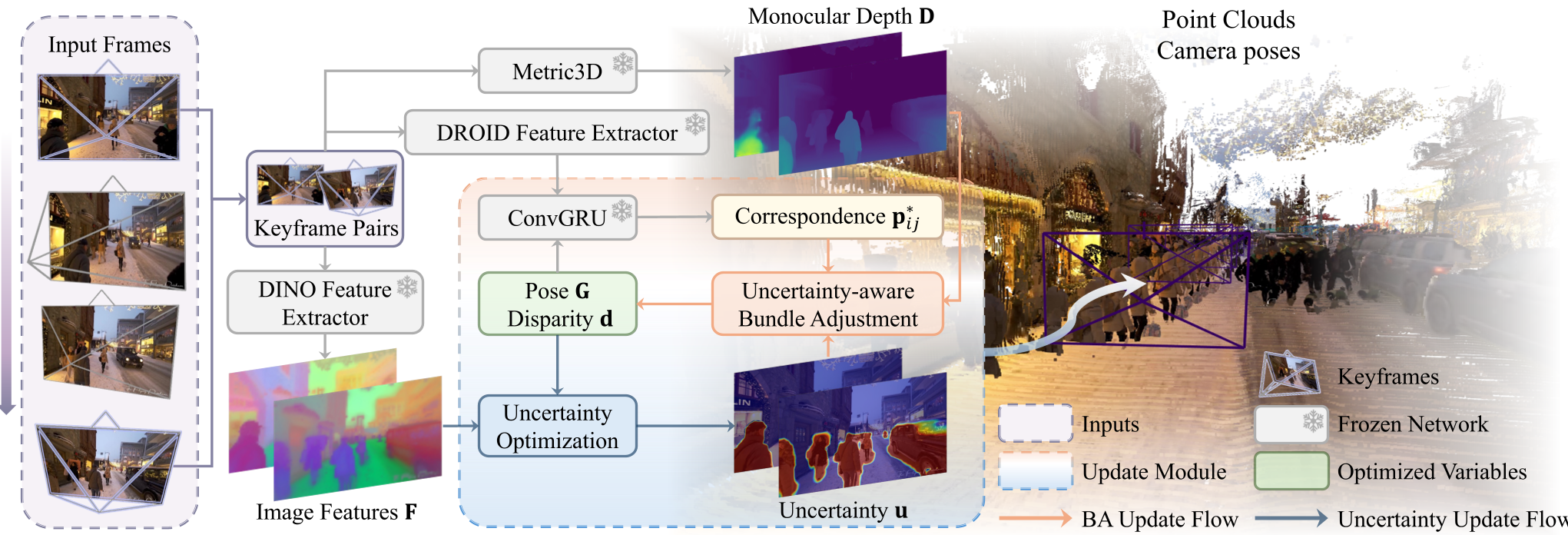 图 1: DROID-W 系统概览,展示了位姿-深度精细化与不确定性优化的交替迭代过程。
图 1: DROID-W 系统概览,展示了位姿-深度精细化与不确定性优化的交替迭代过程。
实验战绩:从实验室到 YouTube 荒野
作者不仅在 Bonn 和 TUM 这种标准动态数据集上进行了测试,还推出了 DROID-W Dataset(包含 LiDAR 地面真值)以及 6 段极度复杂的 YouTube 视频(包括繁华的东京街头、大象群等)。
- 性能表现:在 Bonn 数据集上,其 ATE(绝对轨迹误差)仅为 2.30cm,远优于 DROID-SLAM 的 4.91cm。
- 实时性:在保证性能的同时,运行速度达到了约 10 FPS,比基线方法 WildGS-SLAM 快了近 40 倍。
- 重建质量:在动态干扰下,传统方法往往会产生“重影”或双重墙壁,而 DROID-W 的点云重建极为干净、清晰。
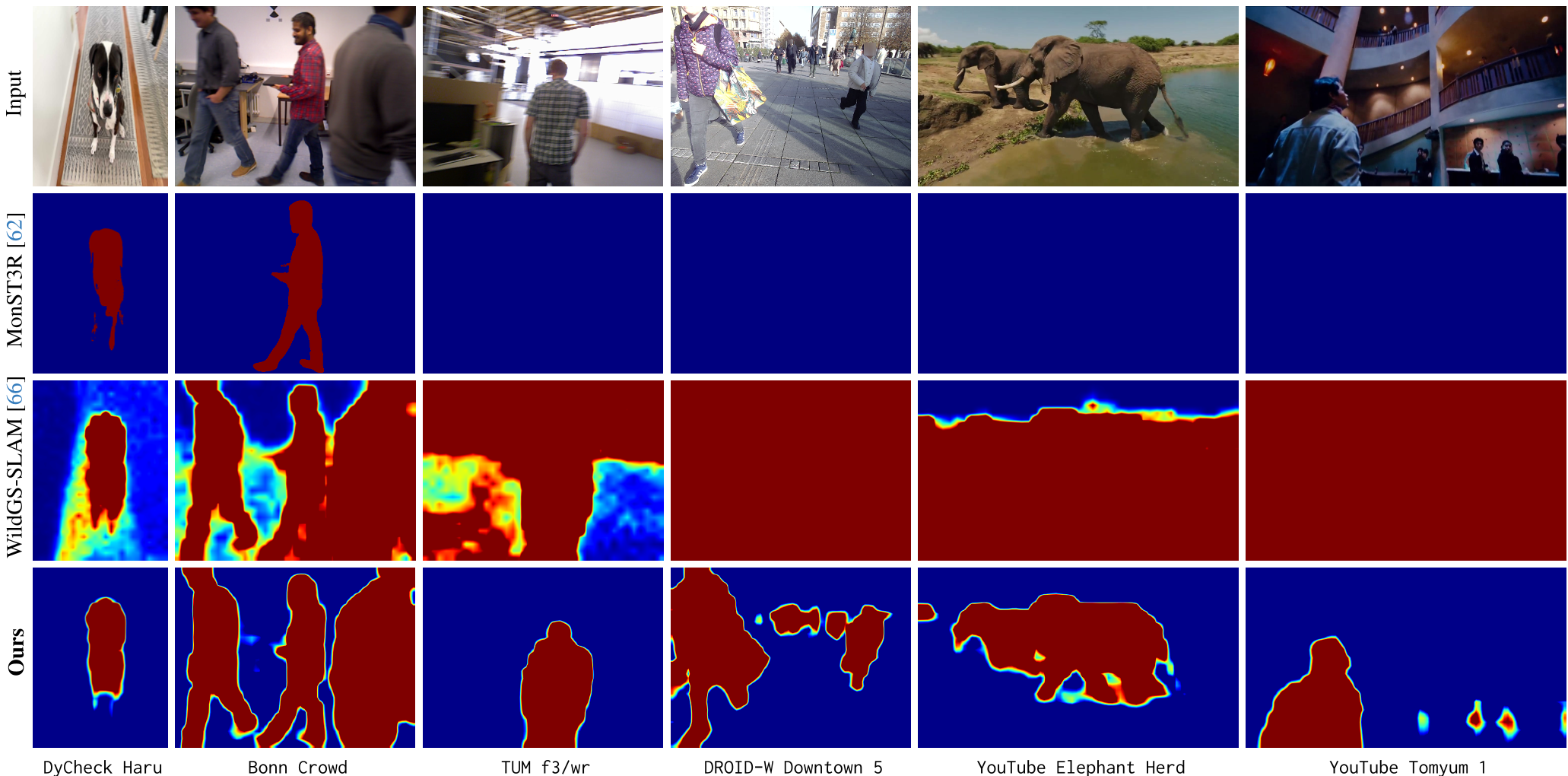 图 2: 不确定性估计可视化。相比之下,DROID-W 能更精准、连贯地捕捉到运动物体的轮廓。
图 2: 不确定性估计可视化。相比之下,DROID-W 能更精准、连贯地捕捉到运动物体的轮廓。
深度洞察
DROID-W 成功的核心在于解耦了不确定性估计与几何重建的依赖。通过局部仿射映射正则化和专门的梯度下降优化,它在没有显式语义标签的情况下,实现了对“动态性”的物理建模。
局限性: 这种方法对 SLAM 的初始化阶段有一定的依赖性。如果在系统刚刚启动、位姿还极其不准时,不确定性估计可能会产生偏差。作者建议未来可以引入更多的重建先验来增强初始化的稳健性。
总结
DROID-W 是一项非常扎实的工作。它向我们展示了:即使是在计算资源有限的实时场景下,通过巧妙地设计可微优化层,深度学习特征(基础模型)也能与经典多视图几何(BA)产生强力的化学反应,让 SLAM 真正走向复杂的外部世界。