本文提出了 DualCoT-VLA,一种将视觉与语言思维链(CoT)集成到机器人视觉-语言-动作(VLA)模型中的并行推理框架。该方法通过在连续潜空间中并行提取 3D 空间特征和逻辑规划,显著提升了机器人处理复杂、多步骤任务的能力。
TL;DR
DualCoT-VLA 是一项突破性的机器人模型研究,它通过**并行思维链(Parallel CoT)**机制,解决了 VLA 模型在复杂任务中“想得深”但“反应慢”的痼疾。通过在 Latent Space 中同时并行处理 3D 空间感知(视觉 CoT)与逻辑规划(语言 CoT),模型在将推理速度提升近 40 倍的同时,在 LIBERO 等多个权威榜单刷新了 SOTA 记录。
痛点深挖:想得太久,做得太慢
当前的机器人 VLA 模型正处于从“直觉映射”向“思维后行动”转变的阶段。然而,现有的 CoT 方法面临两个核心瓶颈:
- 模态孤立:现有的方法要么只有文字逻辑(缺少对空间的精细感知),要么只有视觉预测(缺少长程规划逻辑)。
- 推理延迟:传统的自回归(Autoregressive)解码需要逐个生成 Token。对于需要 50Hz 甚至更高频率控制的机器人来说,秒级的推理延迟(Latency)意味着灾难性的反应迟钝。
核心思路:并行隐式推理 (Parallel Implicit Reasoning)
为了兼顾“深度思考”与“实时控制”,作者抛弃了低效的逐词生成,提出了 DualCoT-VLA。其核心逻辑在于:利用 Learnable Query Tokens 将思考过程压缩到单次前向传播中。
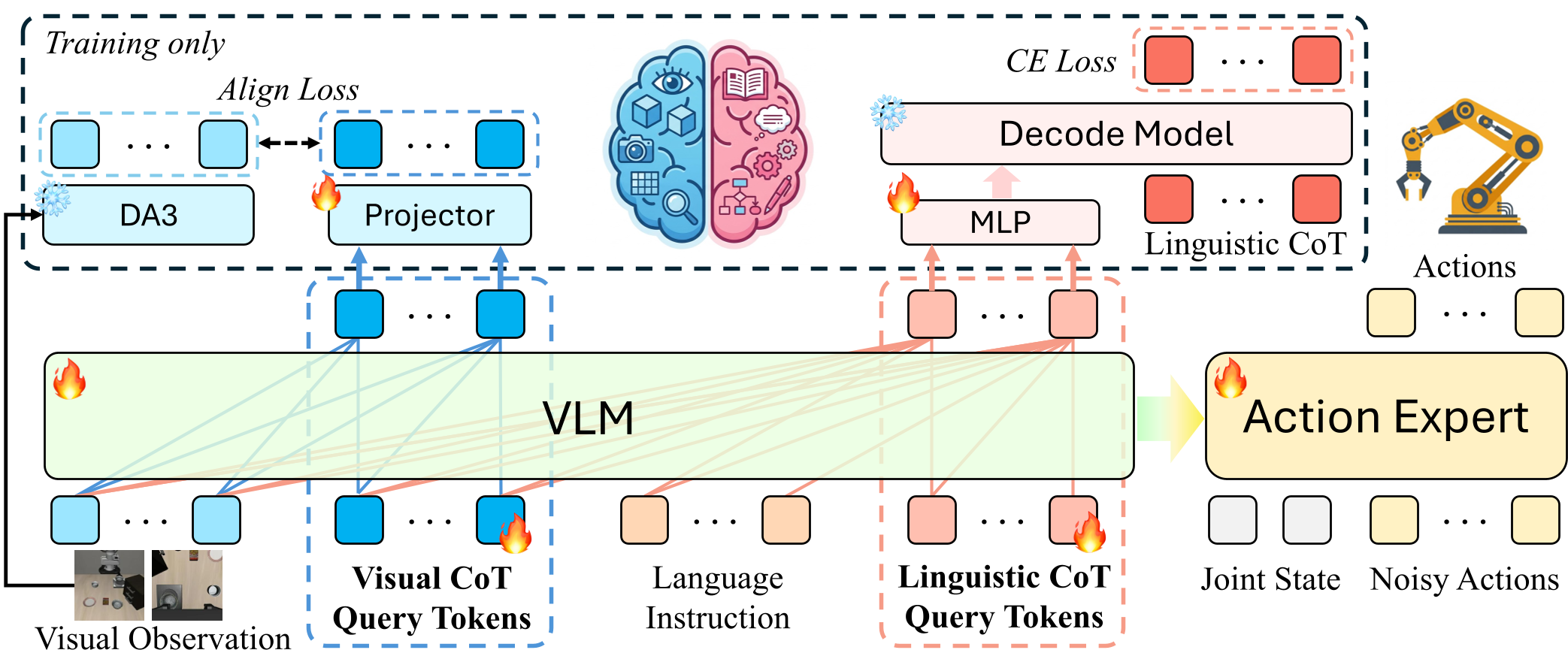
1. 架构解析
模型由三个主要部分组成:
- VLM Backbone:负责处理视觉观测、指令以及特制的两组推理 Query(Qvis 和 Qlin)。
- Dual-Stream 监督:
- 视觉流 (Visual CoT):通过将潜状态与 Depth Anything 3 (DA3) 的特征对齐,强制模型理解 3D 几何结构。
- 语言流 (Linguistic CoT):通过轻量级 LLM 监督,确保潜状态包含分步骤的任务规划逻辑。
- Action Head:采用基于 Flow-Matching 的 DiT(Diffusion Transformer)架构,利用推理增强后的隐向量生成连续动作。
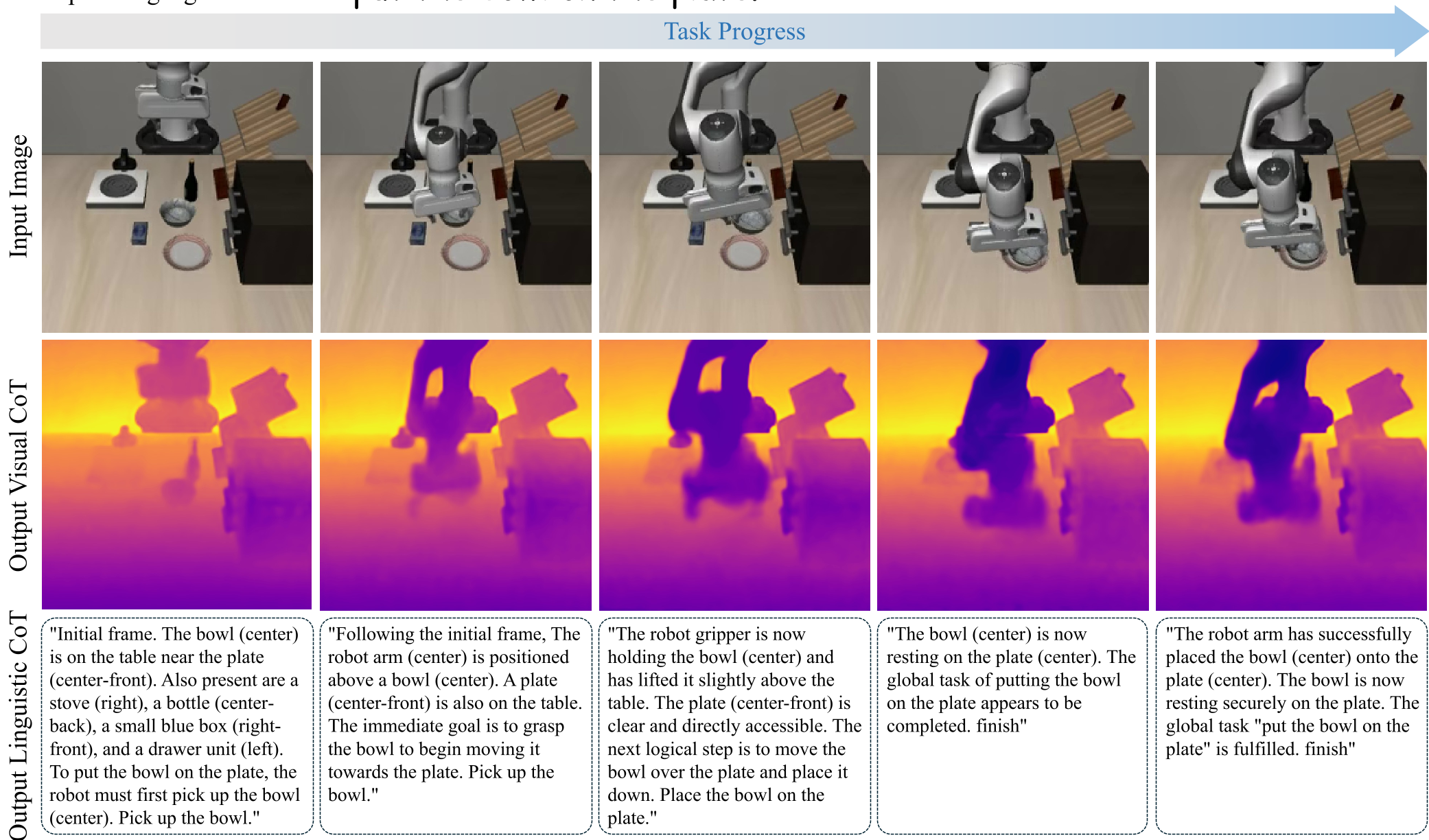
2. 将“思考”可视化
DualCoT-VLA 的迷人之处在于,虽然它是隐式推理,但其潜状态是具备语义的。作者通过探针技术(Lightweight Probe)将 Visual Tokens 还原回深度图,发现模型确实精准捕捉到了物体的空间位置;同时,通过辅助解码器,Linguistic Tokens 也能被翻译成清晰的人类语言规划步骤。
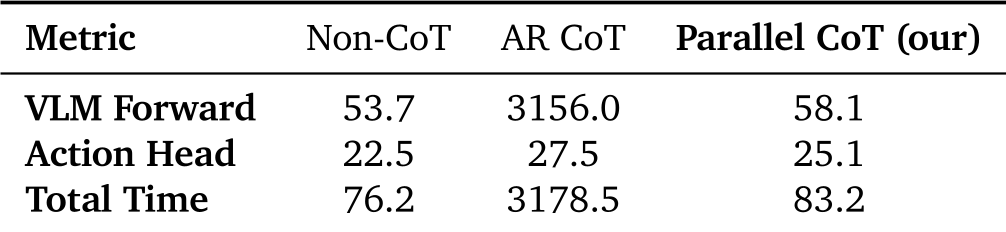
实验战绩:SOTA 与 40 倍加速
基准测试对比
在 LIBERO 基准测试中,DualCoT-VLA 在空间感知(Spatial)和长程任务(Long)中均表现优异,平均成功率(98.8%)超越了现有的 AR CoT 模型。
极速推理
这是最令人印象深刻的数据:
- 传统 AR CoT 模型:VLM 前向耗时 3156 ms(无法用于实时控制)。
- DualCoT-VLA (本文):VLM 前向耗时仅 58.1 ms。
- 总体验:单次推理总时间 83.2 ms,足以支持流畅的物理机器人闭环部署。
深度洞察与总结
DualCoT-VLA 真正的价值在于它证明了思维链不一定要以“说话”的形式存在。对于具身智能任务,逻辑和感知的融合应该在特征层发生。通过将 3D 几何先验与文本规划逻辑同时注入潜空间,模型获得了比纯自回归模型更稳健的表征,同时规避了自回归推理的“误差累积”和“延迟陷阱”。
局限性:尽管加速明显,但模型性能仍受限于 VLM Backbone 的原始能力。如何在更小的本地化计算设备上维持这种双流推理的性能,将是未来的研究方向。
启发:并行推理不仅是速度的优化,更是一种对机器人 Inductive Bias(归纳偏置)的重新思考:空间与逻辑应是并列的,而非串行的。