本文提出了 DynFlowDrive,一种基于 Rectified Flow(修正流)的自动驾驶潜空间世界模型。该方法通过显式建模环境状态随交互动作的连续演变过程,在 nuScenes 和 NavSim 榜单上均取得了 SOTA 性能,其中在 NavSim 上的 PDMS 得分达到了 88.7%。
TL;DR
传统的自动驾驶世界模型往往停留在“根据当前画面预测一张未来图”的思维定式中。本文提出的 DynFlowDrive 认为,未来的演化不应是一个静态的目标,而应该是一个由轨迹驱动的连续动力学过程。通过引入 Rectified Flow (修正流) 技术,DynFlowDrive 成功在潜空间内构建了一个受控的速度场,让模型学会“看”场景是如何随驾驶动作丝滑演进的。这一改动让规划误差降低了 20% 以上,且在推理时完全不增加算力负担。
1. 痛点:一步到位还是渐进演化?
在端到端(End-to-End)自动驾驶中,世界模型(World Model)被寄予厚望,希望它能像老司机一样预测“如果我这么开,环境会发生什么”。
然而,现有的 Latent World Models 普遍采用 One-step Regression(如上图 2a 所示)。这种方法直接将当前 latent mapping 到下一时刻。
- 忽略了过程:它只关注终点,不关注从 A 到 B 的物理演变轨迹。
- 难以评估安全性:比如面对行人,缓慢刹车和快撞上时死刹车,最终位置可能一样,但过程及其蕴含的风险完全不同。
2. 核心架构:Rectified Flow 进入潜空间
DynFlowDrive 不再只是“猜”下一帧的长相,而是学习一个速度场 (Velocity Field)。
2.1 基于流的动力学建模
通过 Rectified Flow 形式化,模型学习如何将当前的潜状态 $z_t$ 沿着由轨迹 $T$ 定义的路径转化为 $z_{t+1}$。
- 速度场预测:模型预测 $v_ heta = \mathcal{F}_ heta(x_s, s, h_t)$,其中 $s$ 是流的时间步(不同于真实的物理时间)。
- ODE 积分:在预测未来时,通过 Euler 积分逐步推动 latent state 的演进。这使得模型能捕捉场景演化的“速率”和“趋势”。
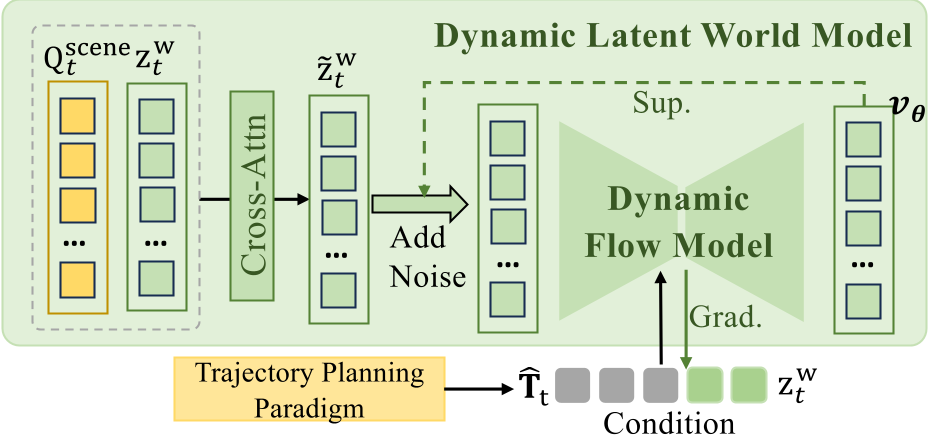 图:DynFlowDrive 整体流程,包含轨迹规划分支(黄色部分)和基于流的世界模型分支(蓝色部分)。
图:DynFlowDrive 整体流程,包含轨迹规划分支(黄色部分)和基于流的世界模型分支(蓝色部分)。
2.2 稳定性感知(Stability-aware)选择
基于学习到的速度场,作者提出了一个极其直观的物理指标:方向一致性。 如果一条候选轨迹导致预测的 latent 演进过程中速度场方向剧烈抖动,那这条轨迹及其导致的场景演化在物理上大概率是不连贯、不安全的。通过计算连续步长间速度因子的余弦相似度(角偏差),模型能自动选出最“稳”的那条路。
3. 实验战绩:全线飘红
DynFlowDrive 在 nuScenes(开环)和 NavSim(闭环)两大基准测试中表现极为强势。
- 规划性能:在 nuScenes 上,相比基线 SSR,平均 L2 位移误差从 0.39m 下降到 0.31m。
- 零开销推理:这是一大亮点。虽然训练时引入了复杂的流模型,但在 inference 阶段世界模型是不参与计算的。模型通过训练时的“稳定性引导”,已经让 Planning Head 学会了更好的特征表示。
 表:nuScenes 上的对比实验,可以看到 DynFlowDrive 在 L2 误差和碰撞率上均优于之前的世界模型方法。
表:nuScenes 上的对比实验,可以看到 DynFlowDrive 在 L2 误差和碰撞率上均优于之前的世界模型方法。
4. 深度洞察:为什么这种方法更有效?
- 物理直觉的显式捕捉:传统的回归模型是在黑盒里学映射,而 Flow-based 模型被迫去理解“变化率”。这相当于给模型增加了一层关于运动学的 Inductive Bias。
- 解耦表示与动力学:作者使用了预训练的 foundation encoder(如 VAE)来提取特征,而不是让模型从头学图像编码。这保证了 latent space 的稳定性,让模型能专心于“演化规律”的学习。
- 多步积分的威力:消融实验(见表 5a)显示,随着积分步数从 1 增加到 5,误差持续下降。这证明了将复杂的场景演化拆解为多个微小步长,确实能显著缓解长程预测的漂移问题。
5. 总结与展望
DynFlowDrive 为端到端驾驶提供了一个非常优雅的范式:用连续流建模未来,用物理稳定性指导规划。
局限性:虽然精度提升明显,但目前主要还是依赖潜空间特征。未来如果能结合 Vision-Language Models (VLMs) 引入更高层的语义推理(例如:判断行人是否有过马路意图),其鲁棒性可能更上一层楼。
Takeaway: 自动驾驶的未来不在于画出最美的“未来图像”,而在于理解那隐藏在潜空间中、受物理定式约束的动力学“流”。