本文提出了 Em-Garde,一个专为主动式流式视频理解(Proactive Streaming Video Understanding)设计的“提议-匹配”(Propose-Match)框架。该框架通过将高层语义推理与底层流式感知解耦,实现了在保持高精度的同时,在 A100 GPU 上达到 10-15 fps 的实时处理速度。
TL;DR
在主动式视频理解(Proactive Video Understanding)任务中,模型不仅要看懂视频,还要“主动”在特定时刻(如运动员进球、水开、小孩跌倒)给出响应。传统的 VideoLLM 往往在每一帧都进行繁重的推理,导致要么跑不动,要么看不准。本文提出的 Em-Garde 框架,通过在指令下达瞬间先生成“视觉预案”(Proposals),再让轻量化模型在流式过程中进行“视觉比对”,成功打破了这一僵局,实现了 SOTA 精度与 15 fps 的丝滑体验。
背景定位
流式视频理解已从被动问答转向主动交互。然而,由于计算资源有限,现有的 SOTA 模型(如 VideoLLM-Online, StreamAgent)在处理超长视频流时,往往面临内存爆炸或决策滞后的问题。Em-Garde 属于架构创新类工作,它首次系统性地通过语义与感知的解耦,重新定义了主动响应任务的计算管线。
痛点与动机:为什么逐帧决策行不通?
现有的方法大多遵循“感知+推理+决策”同步进行的逻辑。每来一帧,模型都要问自己:“现在该说话吗?”
- 效率瓶颈:复杂的语义推理需要大规模参数支持,难以达到 5-10 fps 的工业级阈值。
- 上下文压力:随着视频变长,Context 越来越大,模型推理速度会线性下降。
- 信噪比低:大多数帧是无意义的,让庞大的 LLM 每一帧都参与计算是极大的浪费。
作者的 Insight:当用户说“水烧开时提醒我”时,大脑已经预见到了“剧烈气泡”或“大量蒸汽”等视觉信号。在流式观察时,由于目标已知,其实只需要进行简单的视觉模式匹配,而不再需要每秒进行几十次“语义思考”。
核心方法论:Em-Garde 的双塔解耦架构
Em-Garde 将流程分为两个互不干扰的阶段:
1. 指令引导提议解析器 (IGPP) —— “预见未来”
在接收到指令 I 时,由一个强大的全量 MLLM(如 Qwen2.5-VL)执行。它不直接观察流,而是根据指令和当前的简短视频背景,解析出多个具体的视觉提议(Visual Proposals)。
- 例如:指令是“提醒我不要让牛奶溢出来”,IGPP 会生成诸如“牛奶表面开始产生细小泡沫”、“液面迅速上升”等具体的视觉 cue。
- 强化学习优化 (RL):作者发现 SFT 生成的提议往往太抽象。通过 GRPO 算法进行强化学习,模型学会生成“感知友好型”的提议,更易于被底层模块识别。
2. 轻量级提议匹配模块 (LPMM) —— “高效监视”
在流式环节中,仅使用一个超轻量级的 Embedding 模型(如 2B 规模)。
- 向量空间比对:将实时帧的 Embedding 与预存的 Proposals Embedding 计算余弦相似度。
- 突变检测:当相似度得分 $s_i$ 出现剧烈上升且超过阈值 $ heta$ 时,触发响应。
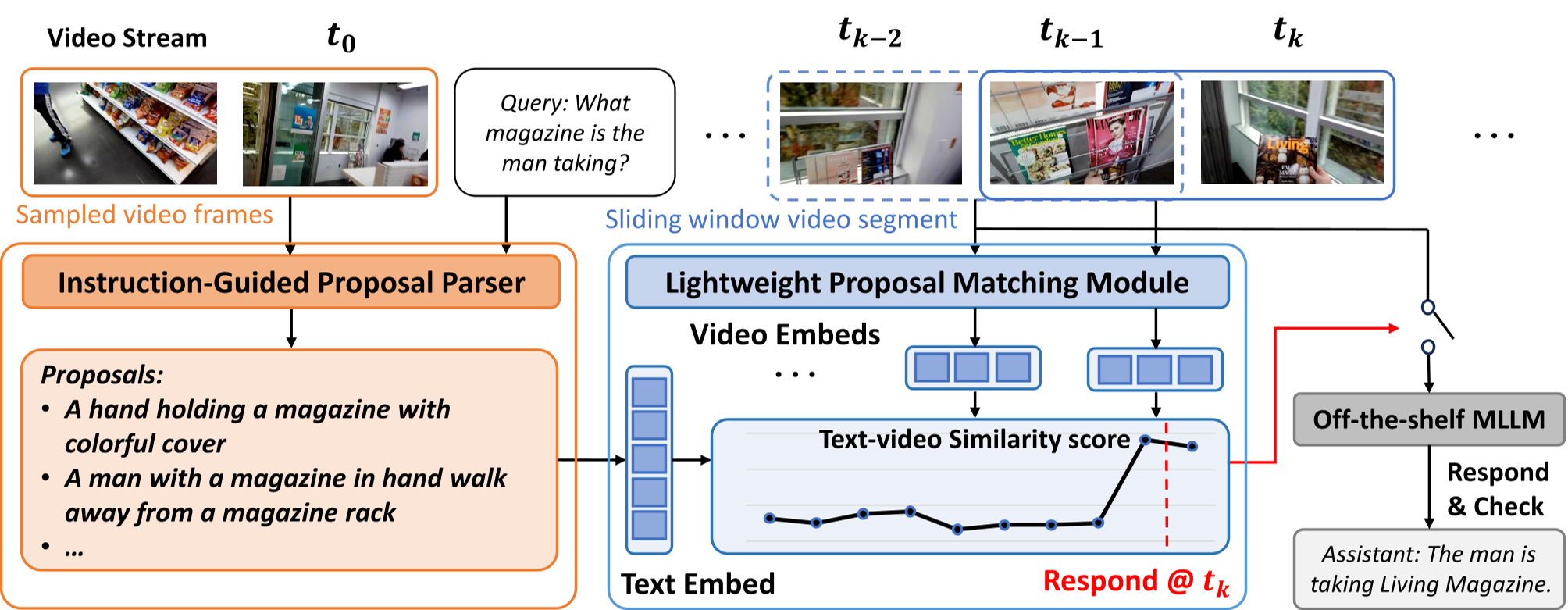 图 1:Em-Garde 框架概览,橙色部分为异步的高层语义解析,蓝色部分为高频流式匹配。
图 1:Em-Garde 框架概览,橙色部分为异步的高层语义解析,蓝色部分为高频流式匹配。
实验与结果
性能表现(Accuracy & Efficiency)
在 StreamingBench 和 OVO-Bench 两个主流基准测试中,Em-Garde 的表现令人印象深刻:
- 准确率:在 OVO-Bench 的 Forward Active Response 任务上,F1 分数相较于之前的 SOTA 提升了近 10%。
- 推理速度:如图 3/Figure 8 所示,虽然 MM-Duet2 等模型也有不错表现,但其延迟随时间激增;而 Em-Garde 的延迟几乎是常数级的,始终保持在 10-15 fps。
 表 1:在 OVO-Bench 上的性能对比,Em-Garde 在 CRR, SSR 等任务中全面领先。
表 1:在 OVO-Bench 上的性能对比,Em-Garde 在 CRR, SSR 等任务中全面领先。
消融实验:RL 的杀手锏
如图 4 所示,RL 训练后的 Proposals 更加务实。例如在识别斯诺克得分变化时,RL 之前的模型可能会关注“奥沙利文”整个人,而 RL 之后模型会精准锁定“比分板上的数字 24”,这种时间对齐性显著降低了误触发率。
深度洞察与总结
核心 takeaway:主动式视频理解的本质是预期(Anticipation)与验证(Verification)。Em-Garde 通过将预期(解析)与验证(匹配)分置于不同的时间尺度,完美解决了实时交互的算力矛盾。
局限性与展望:
- 负向提议(Negative Proposals):目前模型在处理视觉相似但语义相反的场景时仍有挑战。
- 长程推理:目前的匹配是局部的,对于需要跨越数分钟视频进行逻辑推理的任务,仍需结合更强的记忆管理机制。
总之,Em-Garde 为具身智能(Embodied AI)助理和长视频监控提供了一个高度可落地的技术范式。