本文提出了专业化预训练(Specialized Pretraining, SPT),通过在预训练阶段交织少量(1-5%)通常用于微调的领域特定数据,显著提升模型在 ChemPile、MusicPile 和 ProofPile 等专业领域的性能。实验表明,SPT 能在保持通用能力的同时,减少达到目标性能所需的预训练 Token 量达 1.75 倍。
TL;DR
在 AI 工业界,标准的做法是拿一个大规模预训练好的模型(如 Llama-3)然后在自己的垂直领域数据上做微调(Finetuning)。然而,DatologyAI 团队的最新研究指出,这种策略其实是一种**“微调者的谬误” (Finetuner’s Fallacy)**。通过一种名为 SPT (Specialized Pretraining) 的简单策略——在预训练阶段就混入 1%-5% 的领域数据——我们可以用更小的参数规模、更少的计算量,获得远超大模型微调的效果。
痛点深挖:消失的泛化与沉重的“微调税”
传统的“预训练-微调”两阶段范式假设通用知识和领域知识是解耦的。但研究发现:
- 灾难性遗忘:在微调阶段强行注入领域知识,会迫使权重发生剧烈偏移,导致模型迅速忘掉通用常识。
- 过拟合陷阱:领域数据通常较少,微调时的集中训练极易导致模型“死记硬背”而非理解规律。
- 推理开销(Inference Tax):为了让领域能力达标,开发者不得不使用更大的模型(如 70B 而非 8B),这在长期推理部署中产生了巨大的经济成本。
核心方法:专业化预训练 (SPT)
SPT 的直觉非常朴素:不要把鸡蛋都放在微调这个篮子里。
作者将通常预留给微调阶段的领域数据集 $D_{dom}$,以比例 $\delta$ 混入海量的通用语料库。即使领域数据集只有 300M tokens,在 200B tokens 的预训练过程中,这些专业数据也会被循环重复 10-50 次。
 图 1:SPT 在预训练阶段交织领域数据(蓝色实线),相比于仅作通用预训练(虚线),在微调后的领域损失更低,通用知识保留更好。
图 1:SPT 在预训练阶段交织领域数据(蓝色实线),相比于仅作通用预训练(虚线),在微调后的领域损失更低,通用知识保留更好。
为什么 SPT 有效?——“弥散式”暴露的正则化作用
作者通过实验发现,在预训练阶段,每个 Batch 中只有极少量的领域 Token。由于此时大部分梯度更新仍由通用语料主导,通用语料起到了天然正则效应。模型在潜移默化中习得了领域结构,而不会像微调那样因为“营养过载”而产生过拟合风险。
实验与战绩:小模型反杀大模型
研究涵盖了化学 (ChemPile)、音乐 (MusicPile) 和数学证明 (ProofPile) 三大领域。
- 1B > 3B 的跨级打击:在数学证明领域,一个经过 SPT 训练出的 1B 模型,其微调后的表现竟然超过了未经 SPT 的 3B 模型。
- 计算效率倍增:达到相同的领域 Loss,SPT 能够节省约 1.75 倍的 Token 预算。
- 推理经济学:虽然 SPT 在训练阶段可能比单纯微调一个开源大模型多花一点钱,但因为可以用更小的模型跑业务,在推理 Token 达到 1T 后,综合成本将大幅下降(图 3)。
 图 2:SPT 在不同领域下均展现出对 NPT (Naive Pretraining) 的明显压制。
图 2:SPT 在不同领域下均展现出对 NPT (Naive Pretraining) 的明显压制。
深度洞察:关于“重复”的 Scaling Law
以往的 Scaling Law 很少讨论数据重复且过拟合的阶段。本文提出了一个新的分解模型: $$\mathcal{L}{test}(T, \delta) = \mathcal{L}{train}(T, \delta) + \mathcal{L}_{gap}(T, \delta)$$ 其中将 训练损失 (Training Loss) 和 泛化间隙 (Train-test Gap) 分别建模。通过这一公式,开发者只需通过少量的 pilot runs(初步实验),就能预测在给定算力预算下,混入百分之几的领域数据($\delta$)是最佳的。
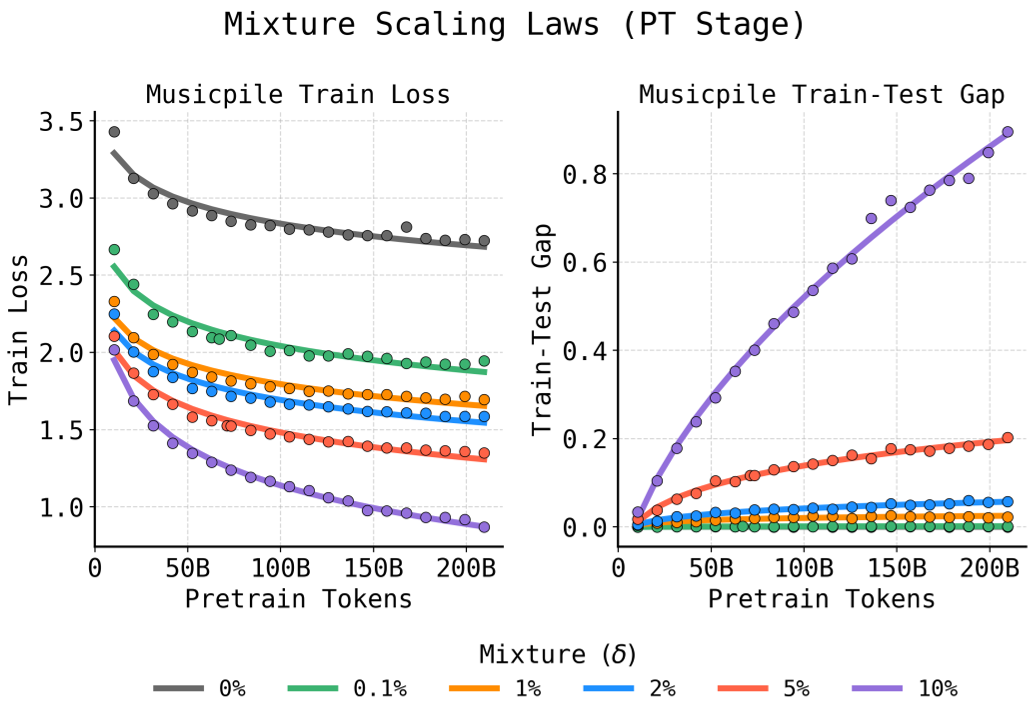 图 3:将测试损失分解为训练损失(负指数)和泛化间隙(正指数)之和,精准刻画了重复数据导致的过拟合拐点。
图 3:将测试损失分解为训练损失(负指数)和泛化间隙(正指数)之和,精准刻画了重复数据导致的过拟合拐点。
总结与局限性
Takeaway: 如果你手里有一批珍贵的私有领域数据,且你的目标是部署一个极致性能的专业模型,请务必把它加进预训练阶段。
局限性:
- SPT 的增益与领域和通用语料的分布差异 (Domain Similarity) 呈正相关。如果你的领域本身就和网页文本很像(如普通的新闻分析),SPT 的提升会边际递减。
- 对于极小规模的数据(少于数千万 Token),过早引入仍可能导致过度重复,此时“持续预训练 (Continued Pretraining)”可能是更稳妥的选择。
未来的专业模型将不再是“基座模型 + 后期补丁”,而是从第一行代码开始,就带着领域基因原生生长的智能体。