本文提出了 GAMEPLAYQA,一个用于评估 3D 虚拟智能体感知与推理能力的基准测试框架。该框架采用密集标注的多人游戏视频(1.22 标签/秒),涵盖了 Self-Other-World 的三元实体分解。通过评估 16 种前沿 MLLMs,发现当前最强模型(如 Gemini 2.5 Pro)在处理决策密集型场景和跨视频理解方面仍与人类存在显著差距。
TL;DR
随着多模态大模型(MLLMs)逐渐成为具身智能(Embodied AI)的感知中枢,我们对其要求已不再是简单的“看图识物”。GAMEPLAYQA 提出了一个全新的评估范式:利用高频、决策密集且多视角的 3D 游戏视频,通过 Self-Other-World 三维标注体系,深挖模型在感知智能体状态、预测他人意图及理解复杂环境事件中的缺陷。实验证明,即便是现有的顶级对齐模型,在面对 1.22 标签/秒的超高信息密度时,依然难逃“时间幻觉”与“角色错位”的陷阱。
为什么 3D 游戏是 LLM 的最佳“认知沙盒”?
现有的视频基准(如 MVBench 或 Video-MME)大多包含的是被动拍摄的内容,动作节奏缓慢且语义稀疏。但在真实的机器人或自动驾驶场景中,智能体必须在极短时间内处理:
- Dense State-Action Tracking:连续追踪自身动作反馈。
- Other-Agent Modeling:预测竞争者或协作者的意图。
- Multi-POV Fusion:整合来自多个传感器的同步视角。
作者认为,3D 游戏提供了一个因果确定且决策密集的环境。在这个环境中,状态转换是毫秒级的,这正是测试 MLLMs 实时感知边界的理想坐标系。
核心方法:Self-Other-World 分解逻辑
为了系统化诊断模型的失败模式,GAMEPLAYQA 定义了三类实体:
- Self(自身): 追踪第一人称视角(POV)下的动作(如:Reloading)与状态(如:Health)。
- Other(他人): 建模视野内敌友的动作与意图。
- World(环境): 感知动态事件(如:Explosion)与静态物品。
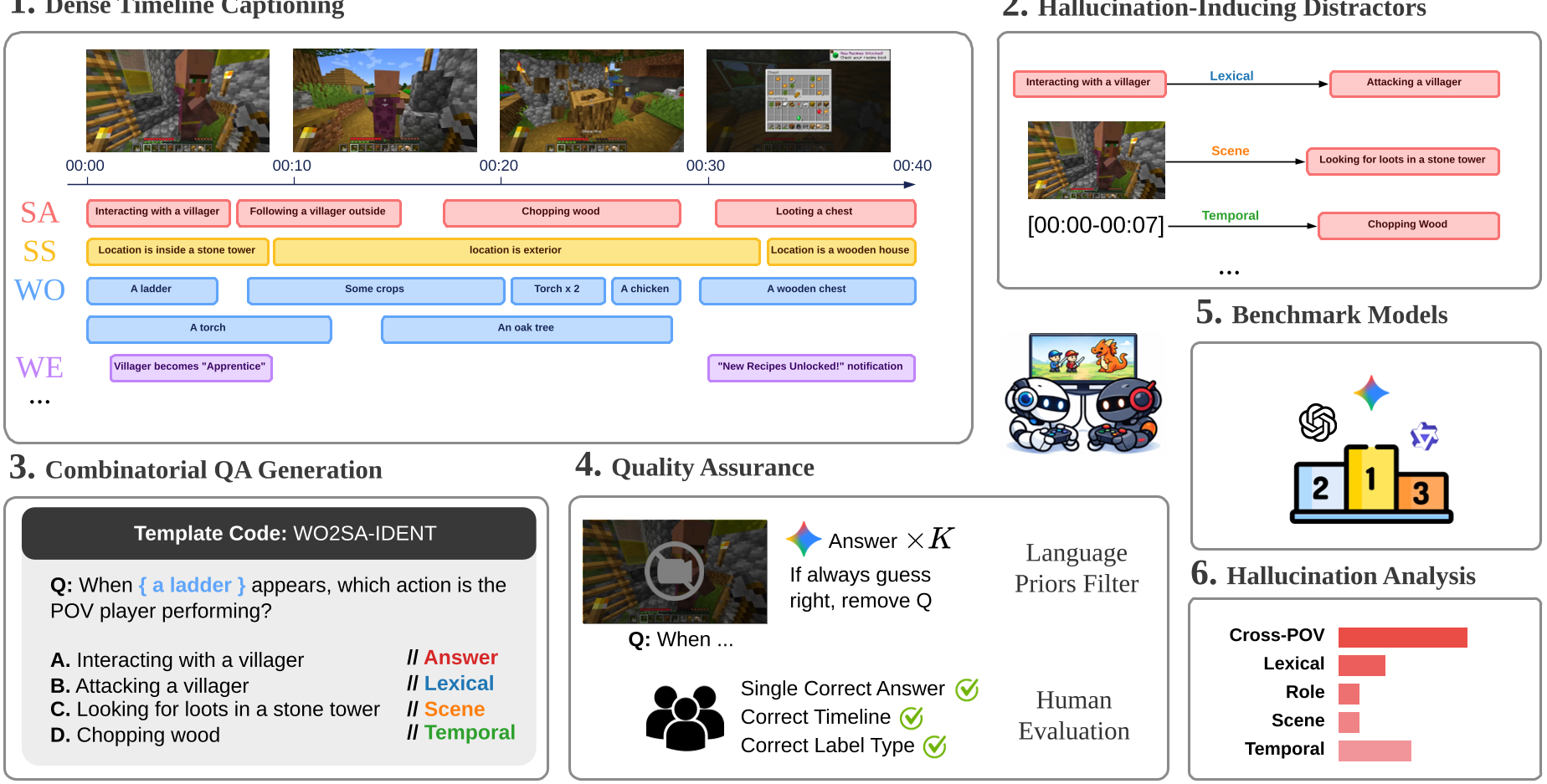
该框架最核心的创新在于其 Distractor Taxonomy(干扰项分类法)。在生成 QA 时,它不只是随机选错项,而是针对性植入:
- Role Distractors: 把张三做的动作安在李四头上。
- Temporal Distractors: 提供视频中确实发生过、但时间点错误的选项。
- Cross-Video Distractors: 测试多视频同步理解时的跨视角特征混淆。
实验与结果:巅峰对决下的“翻车”现场
研究团队评估了包括 GPT-5 系列、Gemini 系列和开源的 Qwen3-VL 等 16 种模型。
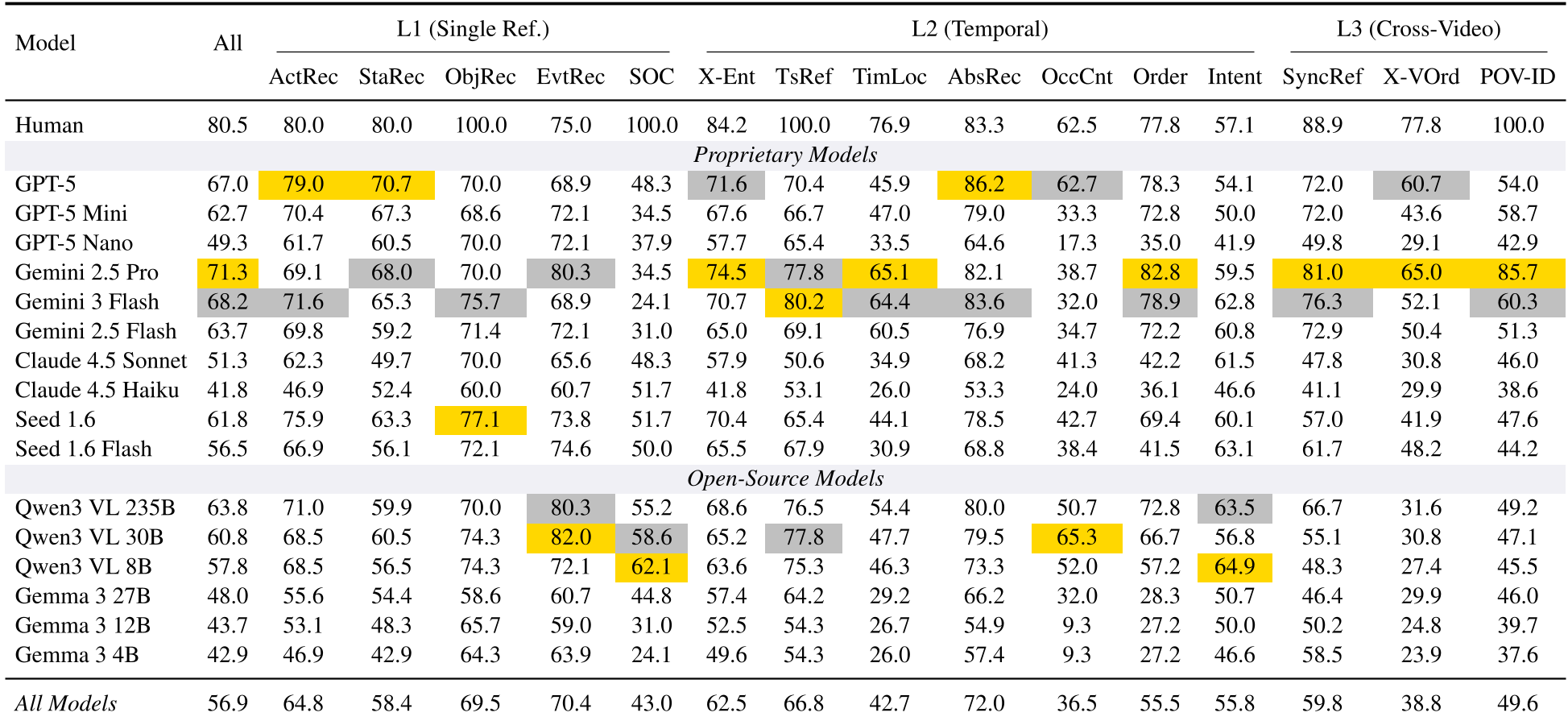
关键洞察:
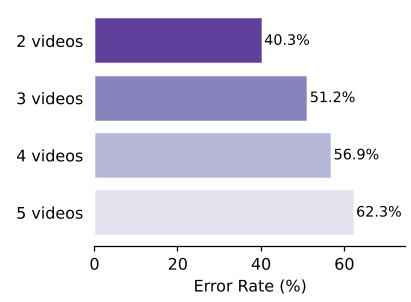
- 认知层级的性能滑坡: 所有模型均表现出随认知难度(L1 感知 -> L2 时间推理 -> L3 跨视频理解)增加而精度锐减的趋势。L3 任务中,模型的平均得分跌破 50%。
- “数数”与“排序”是硬伤: Occurrence Count(计次数)和 Cross-Video Ordering(跨视频排序)是最大的痛点。这反映了当前模型在处理 Long-horizon Temporal Attention(长程时间注意力)时的薄弱。
- 游戏的“节奏”决定难度: 在竞技类射击游戏(如 CS2、Battlefield)中,由于画面切换极快,模型的报错率远高于慢节奏的探索类游戏(如 Minecraft)。
深度总结:通往具身智能的门槛
GAMEPLAYQA 的价值在于它证明了:能看懂电影情节的大模型,不一定能演好一个智能体。 当前 LLM 的核心局限在于它们对“动作归一化”和“精确时间戳对齐”的感知极度不完善。
未来的启示:
- 感知密度($\rho$)应成为指标:不能只看视频长度,更要看每秒包含的语义事件密度。
- 多视角对齐是基石:对于机器人领域,如何通过注意力机制强制建立不同传感器(视角)间的时间等效性,是下一步训练 MLLMs 的关键。
如果你正在开发一个试图进入物理世界或 3D 虚拟世界的 AI Agent,GAMEPLAYQA 无疑是目前最严苛的一份抽样体检单。
编者注:该研究由南加州大学团队完成,其数据集与工具链已在 https://hats-ict.github.io/gameplayqa/ 开源。