本文提出了 GaussianGPT,这是一款基于 Transformer 的自回归 3D 生成模型。它通过将 3D Gaussian Splatting 场景离散化为令牌序列,实现了通过“下一令牌预测”(Next-token Prediction)直接生成复杂的 3D 室内场景,并在场景补全和无限外扩任务上达到了 SOTA 水平。
TL;DR
生成式 AI 正在从 2D 图像/视频向 3D 空间快速演进。传统的 3D 生成多依赖扩散模型(Diffusion),虽然质量高但难以实现“像搭积木一样”的增量生成。慕尼黑工业大学(TUM)的研究团队推出了 GaussianGPT,首次通过纯自回归(Autoregressive)的方式,将 3D Gaussian Splatting 场景转化为令牌序列进行预测,实现了 3D 场景的精准补全、无限外扩和极高质量的物体合成。
痛点深挖:为什么 3D 场景生成很难“自回归”?
在自然语言处理中,文字是天然的一维序列。但在 3D 空间中:
- 缺乏自然顺序:3D 空间没有固定的起始点,如何将三维网格扁平化为一维序列且不丢失空间邻近性?
- 表示不规整:3D 高斯(Gaussians)是无序的点集,参数包括位置、旋转、缩放、不透明度和颜色,直接建模非常混乱。
- 计算开销巨大:场景级别的 3D 数据维度极高,直接处理会导致 Transformer 的上下文窗口爆炸。
核心方法论:从高斯到令牌的华丽转身
1. 场景压缩与离散量化
为了让 Transformer 跑得通,作者首先通过一个稀疏 3D 卷积自编码器将复杂的 3D 高斯原语映射到稀疏的特征网格上。
- 向量量化 (VQ):利用 Lookup-free Quantization (LFQ) 技术,将连续的特征映射为离散的 Codebook 索引。
- 解耦建模:序列中交替出现“位置令牌”(预测下一个点在哪)和“特征令牌”(预测这个点长什么样),这种设计避免了几何与语义特征的相互干扰。
2. 空间感知的 Transformer 架构
即使将 3D 序列化为 1D,传统的 1D 位置编码也会失效(空间上邻近的点在序列中可能相隔万里)。
- 3D RoPE (旋转位置编码):作者引入了 3D 坐标感知的 RoPE,使 Attention 机制直接感知令牌之间的物理距离,而非序列距离。
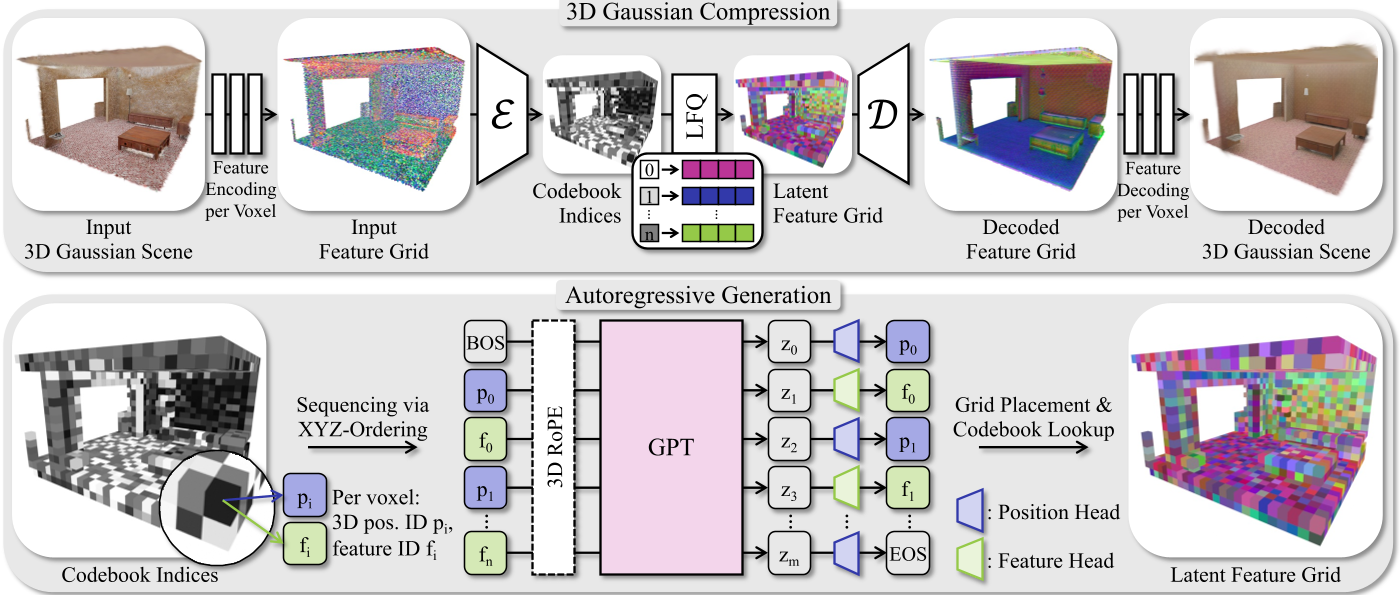 上图展示了 GaussianGPT 的核心流程:从 Gaussian 场景到离散 Token 序列,再通过 Transformer 进行自回归预测。
上图展示了 GaussianGPT 的核心流程:从 Gaussian 场景到离散 Token 序列,再通过 Transformer 进行自回归预测。
实验战绩:不只是补全,更是进化
1. 物体生成:降维打击
在 PhotoShape 椅子数据集上,GaussianGPT 的表现堪称惊艳。其 FID 指标仅为 5.68,对比之前的 SOTA 方法(如 L3DG 的 8.49),提升了约 33%。更重要的是,它生成的结构更加清晰,避开了扩散模型中常见的“噪点”问题。
| Method | FID ↓ | KID ↓ | COV ↑ | MMD ↓ | | :--- | :--- | :--- | :--- | :--- | | π-GAN | 52.71 | 13.64 | 39.92 | 0.08 | | GaussianGPT (Ours) | 5.68 | 1.835 | 67.40 | 4.278 |
2. 场景补全与无限外扩
由于自回归的天性,GaussianGPT 天生擅长“补全”。只要给它一段场景的“开头”,它就能逻辑严密地推导出剩下的部分。通过滑动窗口技术,模型甚至可以生成超出训练尺寸的大规模室内环境,且墙壁、地板的衔接异常平滑。
 图示:给定部分输入(左一),GaussianGPT 能够生成多种语义合理的补全结果。
图示:给定部分输入(左一),GaussianGPT 能够生成多种语义合理的补全结果。
深度洞察:序列化的玄学
有趣的是,作者在消融实验中发现,复杂的空间填充曲线(如 Hilbert 曲线)在 3D 生成中表现并不比简单的 XYZ 顺序好。
- 分析:这是因为 3D RoPE 已经把空间关系“注入”到了注意力矩阵中,此时序列顺序的重要性反而下降了,简单的扫描顺序反而降低了模型预测“下一项”的难度。
总结与展望
GaussianGPT 的出现标志着 3D 生成领域正在吸纳 LLM 的成熟经验。尽管目前在处理真实世界复杂扫描(ScanNet++)时仍受限于自编码器的精度,但其展示的增量生成和因果推理能力,为未来的交互式 3D 设计和具身智能(Embodied AI)模拟环境构建打开了新大门。
局限性:在大规模生成速度(约 4.4 列/秒)和高频细节保留上,仍有提升空间。