本文提出了 Generative Score Inference (GSI),一种通用的多模态数据不确定性量化框架。该方法利用扩散模型(Diffusion Models)等生成模型来近似条件评分分布,在大语言模型幻觉检测和图像描述生成任务中达到了 SOTA 性能。
TL;DR
随着大语言模型(LLM)和视觉语言模型(VLM)进入医疗、金融等敏感领域,我们面临一个核心拷问:什么时候可以信任模型的输出? 来自明尼苏达大学的研究团队提出了 Generative Score Inference (GSI)。它不只是简单的评分,而是利用扩散模型去“模拟”模型犯错的概率分布,从而为每一个模型输出打上严谨的统计标签。
核心定位
在学术坐标系中,GSI 填补了传统保形预测 (Conformal Prediction) 在处理多模态、高维数据时“条件覆盖”不足的空白。它不满足于整体均值的可靠性,而是追求对每一个特定问题的可靠性。
痛点深挖:为何传统方法在多模态面前失灵?
传统的统计推断工具(如 Bootstrap 或渐近区间)在处理图像和文本时往往会崩塌。这是因为多模态数据具有:
- 复杂的模态依赖:文本和图像之间的噪声来源完全不同。
- 自回归漂移:LLM 在生成文本时,步步出错步步累积,导致所谓的“幻觉”具有高度的序列复杂性。
- 维度的诅咒:在高维潜在空间中,简单的分位数估计变得极其不准确。
方法论详解:用“生成”来解决“推断”
GSI 的灵感非常直觉化:既然我们无法直接计算复杂的补丁分布,为什么不训练一个专门的模型来生成这些误差评分(Scores)呢?
GSI 运行流水线 (Pipeline)
- 评分计算:在校准集上,计算模型输出与真值之间的差异分 $s(y, \hat{y})$。
- 条件生成模型训练:训练一个扩散模型 $P(s|x)$,学习在给定输入 $x$ 的情况下,评分 $s$ 的分布。
- 合成采样:对于新样本,通过扩散模型生成 1000 个可能的评分。
- 构建预测集:取这些合成评分的 $(1-\alpha)$ 分位数,确定信任边界。
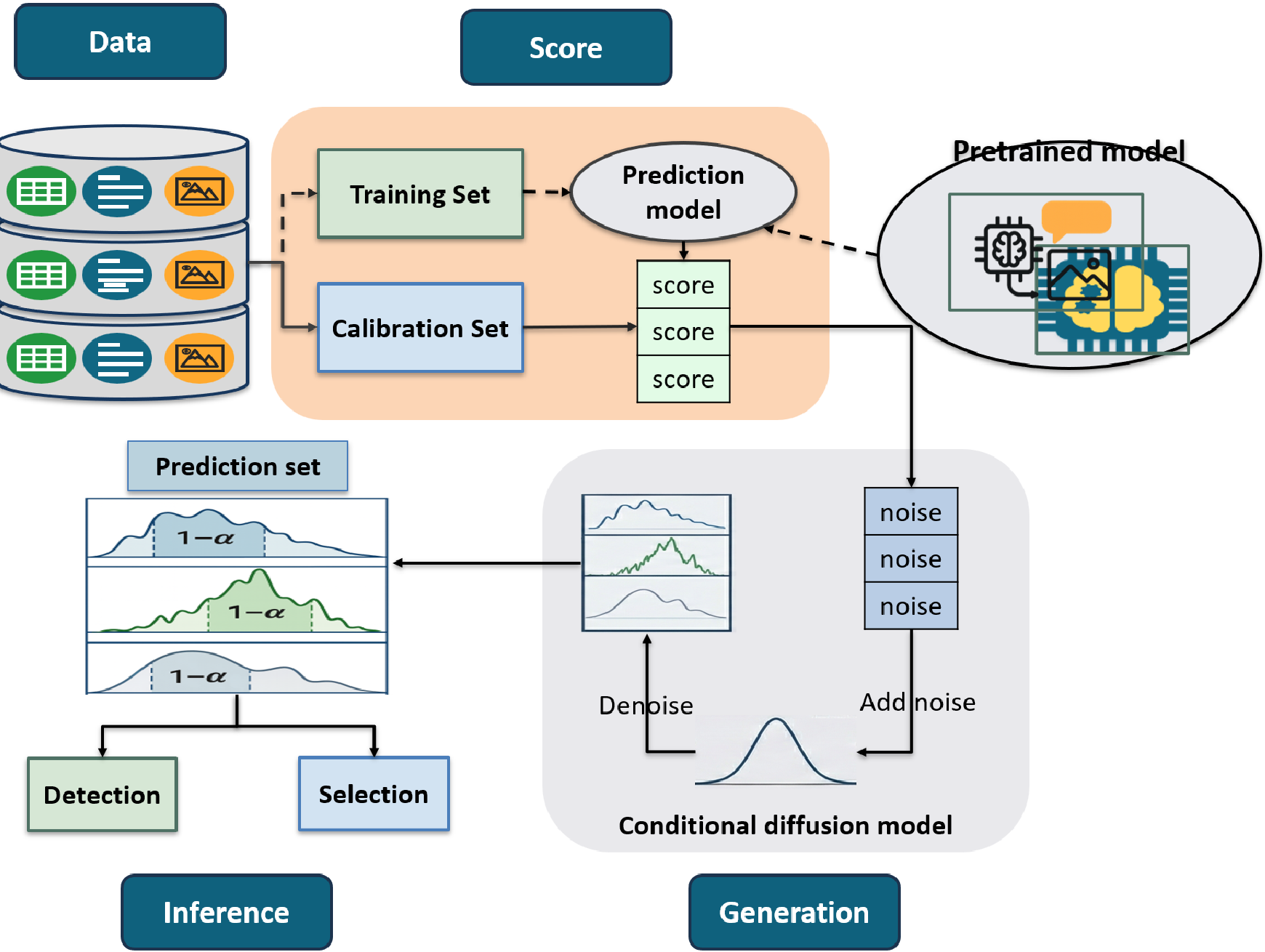 上图展示了 GSI 从样本分割到通过扩散模型生成合成评分,最终构建预测集的完整逻辑。
上图展示了 GSI 从样本分割到通过扩散模型生成合成评分,最终构建预测集的完整逻辑。
实验战绩:全方位的跨维打击
1. 幻觉检测 (Hallucination Detection)
在 WikiQA 任务中,研究者对比了当下最火的 Semantic Entropy (SE)。SE 仅仅检查模型输出的自我一致性,而 GSI 引入了“参考感知评分”。
- 结果:GSI 在保持相同虚警率(Type I Error)的前提下,检出幻觉的成功率(Power)显著高于 SE 和基于分类的 CA 方法。
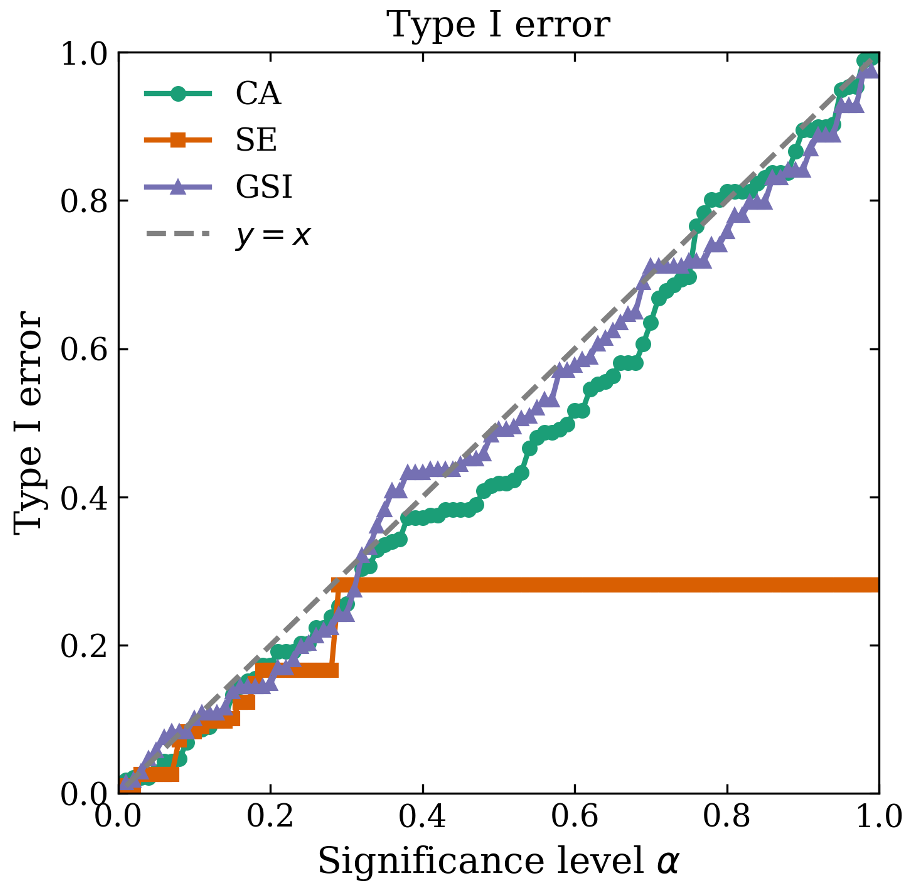 图示表明,随着显著性水平 $\alpha$ 的变化,GSI (粉色线) 的统计功效最快接近 1.0。
图示表明,随着显著性水平 $\alpha$ 的变化,GSI (粉色线) 的统计功效最快接近 1.0。
2. 图像描述筛选
在 MS-COCO 数据集上,任务是挑选出那些模型能“说得准”的图片。
- 表现:GSI 在控制错误发现率 (FDR) 的同时,识别出的高质量描述比基线方法多出约 15%。
深度洞察:为什么扩散模型是最佳拍档?
论文在附录中给出了严谨的数学证明(Theorem 3.2)。之所以选择 Conditional Diffusion,是因为它在捕捉非高斯、异方差以及多峰分布(Multimodal Distribution)方面具有天然优势。相比 GAN 容易模式崩溃,扩散模型能生成更具代表性的“误差样本”,这对于估计分布的长尾概率(即预测不确定性的关键)至关重要。
结论与展望
GSI 的成功标志着不确定性量化从“查表时代”进入了“生成时代”。
- 局限性:采样过程涉及多次逆向去噪步骤,推理成本(Inference Time)高于简单的分位数回归。
- 未来启示:这一框架可以无缝迁移至异常检测或强化学习的安全评估中。它告诉我们:要解决 AI 的可靠性问题,最好的武器可能正是 AI 本身。