GeoRect4D is a unified generative feedback framework for high-fidelity dynamic 3D reconstruction from extremely sparse multi-view videos (e.g., 4 views). It couples an anchor-based dynamic 3D Gaussian Splatting (3DGS) substrate with a single-step diffusion rectifier, achieving state-of-the-art performance with a significant PSNR improvement of up to 3.32 dB on challenging datasets like MPEG.
TL;DR
Reconstructing a moving 3D world from just four cameras is a "mission impossible" of computer vision, usually resulting in "ghostly" artifacts and blurry mess. GeoRect4D solves this by creating a closed-loop system: it uses a stable 3D Gaussian Splatting foundation and "rectifies" it using a smart AI-powered diffusion model that knows how to fill in the blanks without losing physical consistency.
The "Sparse-View" Nightmare in Dynamic Scenes
When you only have a few viewpoints of a moving person or object, the math behind 3D reconstruction breaks down. The model doesn't know what the "back" of the person looks like, so it creates "floaters" (semi-transparent blobs) or "geometric collapse" to satisfy the pixels it can see.
While modern AI (Diffusion Models) can "hallucinate" missing details, they are usually "unaware" of 3D geometry. If you ask a 2D AI to fix the frames, the person's arm might change shape between views, or the background might flicker wildly—a phenomenon known as Structural Drift.
Methodology: The Closed-Loop Rectifier
The brilliance of GeoRect4D lies in its two-stage orchestration: Geometric Purification and Generative Distillation.
1. The Stabilized 3DGS Substrate
The researchers use an anchor-based 3D Gaussian Splatting approach. To prevent the model from getting confused about what's moving and what's static, they identify "dynamic primitives" using positional-gradient statistics. If a Gaussian is constantly getting high gradients, it's likely part of a moving object.
2. Degradation-Aware Generative Prior
Instead of using a standard image generator, they built a Single-step Diffusion Rectifier.
- Structural Locking: It uses skip connections from the encoder to the decoder to ensure the generative "hallucinations" stay glued to the rendered 3D structure.
- Spatiotemporal Coordinated Attention: It looks at neighboring views and frames to ensure that whatever it adds is consistent in space and time.
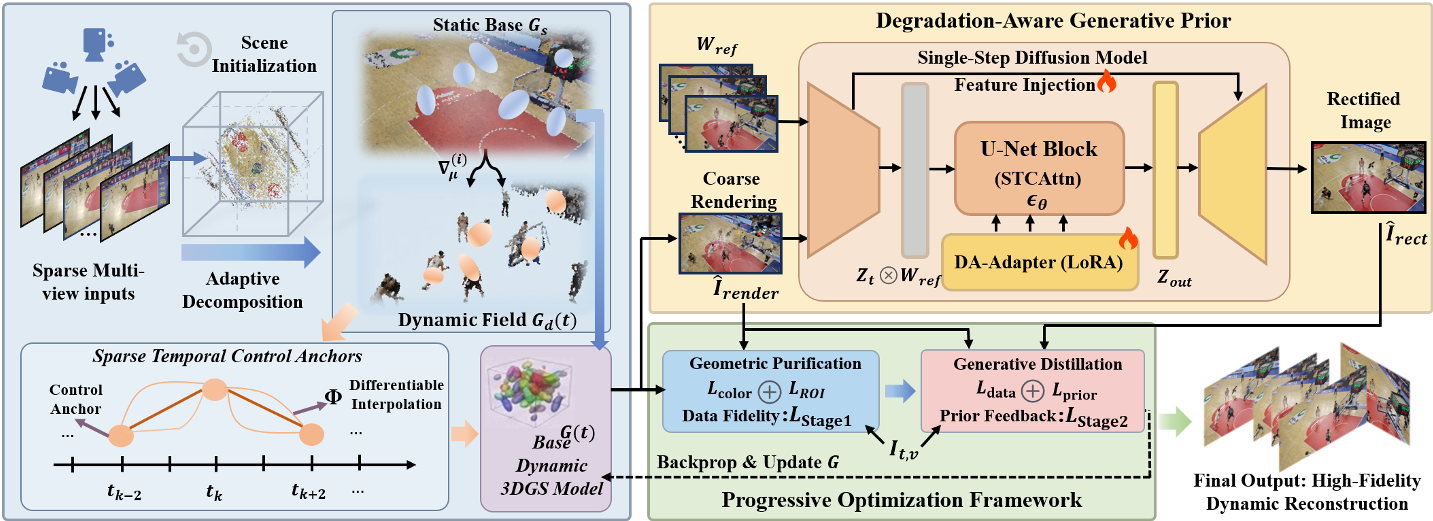 Fig 2: The GeoRect4D framework, showing the interaction between the explicit 3D substrate and the generative rectifier.
Fig 2: The GeoRect4D framework, showing the interaction between the explicit 3D substrate and the generative rectifier.
3. Progressive Optimization
Optimization happens in two stages:
- Stage 1 (Purification): They use Stochastic Pruning. By treating Gaussian existence as a Bernoulli random variable, they "stress test" the geometry. Weak, semi-transparent floaters that only exist to cheat the loss function are pruned away, leaving a solid geometric skeleton.
- Stage 2 (Distillation): Once the skeleton is stable, the generative rectifier "paints" high-fidelity textures onto it.
Experimental Excellence
The results on the MPEG dataset (known for its fast movements and complex topology) are particularly striking. GeoRect4D achieved a PSNR of 22.60 dB, outperforming previous SOTA methods like Swift4D (19.28 dB) by a wide margin.
 Fig 4: Qualitative comparison showing how GeoRect4D preserves sharp silhouettes (e.g., the basketball player) where other methods produce blur.
Fig 4: Qualitative comparison showing how GeoRect4D preserves sharp silhouettes (e.g., the basketball player) where other methods produce blur.
| Metric | Swift4D | Ex4DGS | GeoRect4D (Ours) | | :--- | :--- | :--- | :--- | | PSNR (dB) ↑ | 19.28 | 17.95 | 22.60 | | LPIPS ↓ | 0.267 | 0.316 | 0.175 | | tOF (Temporal) ↓ | 1.731 | 1.660 | 1.412 |
Critical Insight & Future Outlook
The core takeaway is that Generative AI should be a "teacher" rather than a "replacement" for 3D geometry. By distilling 2D generative knowledge into an explicit 3DGS representation, GeoRect4D keeps the best of both worlds: the reliability of 3D math and the creativity of Diffusion models.
Limitations: The system still relies on SfM (Structure from Motion) for initialization. If the initial sparse cameras can't see a textureless surface, the model might still struggle. However, for the future of Free-Viewpoint Video (FVV) and VR, this represents a massive leap in quality for consumer-grade capture setups.
Conclusion
GeoRect4D proves that we don't need dozens of synchronized cameras to capture reality. With a solid geometric foundation and a "degradation-aware" AI assistant, high-fidelity 4D reconstruction is now possible from just a handful of views.