本文提出了 GlowQ,一种针对量化大语言模型(LLMs)的群体共享低秩近似方法(Group-shared Low-rank Approximation)。该方法通过让共享输入的模块组共同使用一个高精度右因子,并结合协方差对齐的 SVD 优化,在显著提升 4-bit 量化模型精度的同时,减少了推理延迟和内存开销。
TL;DR
量化后的 LLM 精度下降是心头大患,传统的低秩修正(Low-rank Correction)虽然有效,却因为给每一层都贴“膏药”导致推理变慢。GlowQ 另辟蹊径,提出让共享输入的模块组(如 Attention 中的 Q/K/V)共用一个高精度投影因子。配合数据感知的协方差对齐技术,它不仅找回了丢失的精度,还比传统方法快了 37%,实现了真正的“又快又好”。
1. 痛点:被忽视的计算冗余与“各向异性”
在当前的低秩修正管线中,我们通常假设 $W \approx W_q + AB$,其中 $W_q$ 是量化权重,$AB$ 是高精度的低秩修正模块。
然而,现有的方法存在两个严重的直觉盲区:
- 计算翻倍:在 Transformer 中,Q/K/V 投影层以及 MLP 的 Gate/Up 投影层通常共享同一个输入 $X$。如果为它们分别设计独立的修正矩阵 $B_i$,推理时就要计算多次 $B_i X$,这在内存带宽受限的场景下是极其奢侈的。
- 特征偏好:真实数据的激活值并不是均匀分布的,而是具有强烈的各向异性(Anisotropy)。如果修正算法不考虑数据的分布特性,有限的秩(Rank)就会被浪费在那些几乎不怎么触发的维度上。
2. Methodology:从独立修正到“群体共治”
2.1 共享右因子 (Group-Shared B)
GlowQ 的核心 Insight 是:既然输入相同,为什么不让 $B$ 矩阵共享?
作者证明了,对于共享输入的一组模块,使用单一共享的右因子 $B_{shared}$ 在数学上是充分且最优的。对应的修正变为 $A_i (B_{shared} X)$。
- 好处:在推理阶段,高精度的 $R = B_{shared} X$ 只需要计算并缓存一次。后续的所有模块只需进行极轻量级的左乘 $A_i R$。
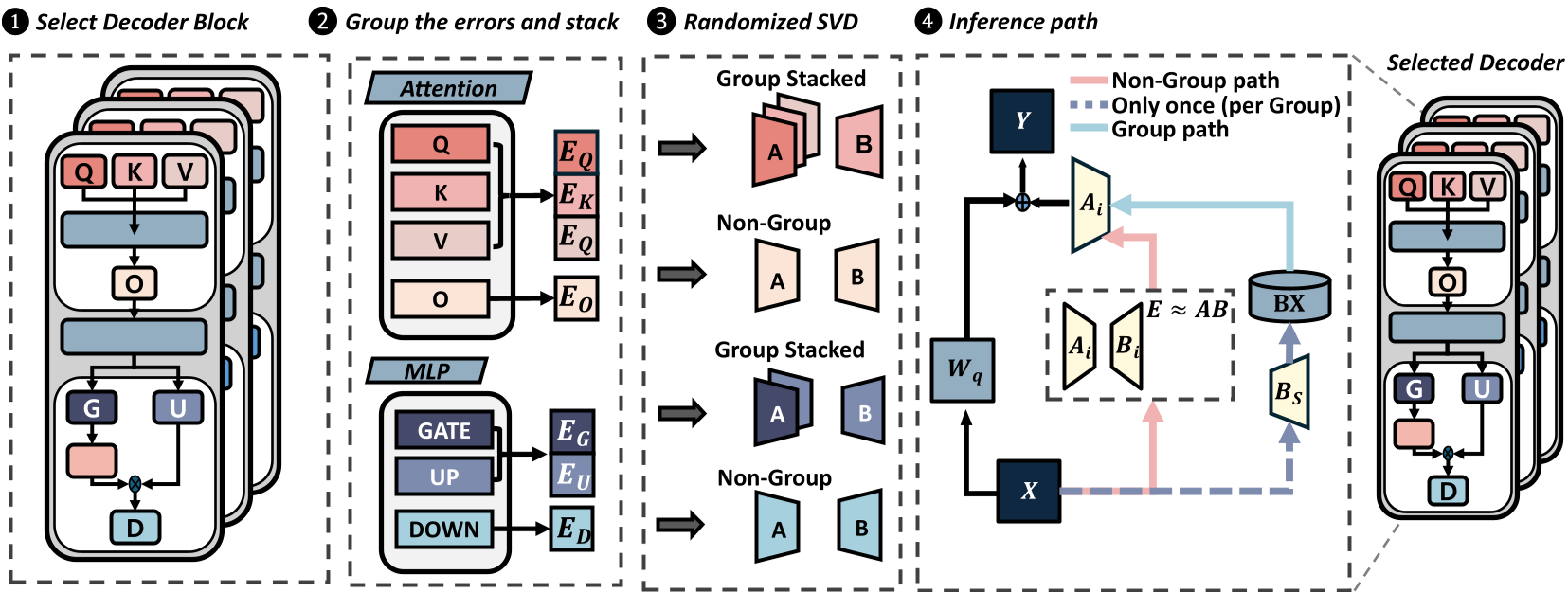 Figure 1: GlowQ 架构概览,展示了如何通过缓存中间投影 R 来减少冗余计算。
Figure 1: GlowQ 架构概览,展示了如何通过缓存中间投影 R 来减少冗余计算。
2.2 协方差对齐 (Data-Aware Alignment)
为了解决各向异性问题,GlowQ 引入了白化(Whitening)思想。它不仅仅最小化权重误差的 Frobenius 范数,而是最小化期望损失: $$\min | (E_{cat} - AB) \Sigma_x^{1/2} |_F^2$$ 其中 $\Sigma_x$ 是输入的协方差矩阵。通过这个变换,算法被强迫去关注那些激活频率更高、能量更强的方向,从而在低秩限制下捕获最具价值的信号。
2.3 QR-Reduced 随机 SVD
面对超大规模的矩阵堆叠,传统的 SVD 分解太慢了。GlowQ 提出了一套流水线:
- QR 压缩:将巨大的堆叠误差矩阵压缩成一个小型的 $d imes d$ 核心。
- 随机化 SVD:在核心矩阵上进行快速近似分解。
- 平衡恢复:利用奇异值对 $A$ 和 $B$ 进行数值平衡,提升推理时的稳定性。
3. 实验战绩:精度与速度的双赢
在 LLaMA 3 和 Qwen 等主流模型上的测试显示,GlowQ 在 4-bit (W4A16) 设定下几乎追平了 FP16 的表现。
关键数据对比:
- 吞吐量 (Throughput): 相比不带缓存的层级修正(Layerwise),GlowQ 提升了 9.6%,而选择性恢复版本 GlowQ-S 则暴力提升了 37.4%。
- 首字延迟 (TTFB): 在 LLaMA 3 上最高降低了 25.3%。
- 困惑度 (PPL): 在 WikiText-2 等任务上,表现一致优于传统的 GPTQ 和 AWQ。
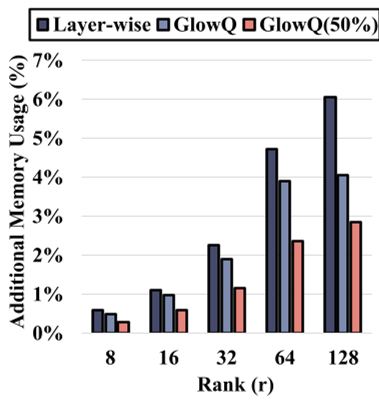 Figure 2: 内存与困惑度的权衡曲线。GlowQ(红色)展示了在极低内存占用下维持高精度的能力。
Figure 2: 内存与困惑度的权衡曲线。GlowQ(红色)展示了在极低内存占用下维持高精度的能力。
4. 深度洞察:为什么协方差对齐这么重要?
论文给出的热力图展示了一个惊人的事实:
- 未对齐前:共享子空间与各层独立子空间几乎没啥联系,热力图是一片混沌。
- 对齐后:热力图呈现出完美的对角线分布!这意味着,一旦考虑了数据的分布,不同层对于“哪些特征最重要”其实是有高度共识的。这就是“共享右因子”不仅可行而且高效的物理直觉。
5. 总结与展望
GlowQ 证明了在 LLM 压缩领域,算法设计必须尊重架构特征。通过识别 Transformer 内部的输入共享机制,并结合统计学上的协方差对齐,我们可以在不损失精度的前提下,大幅削减量化修正带来的额外开销。
局限性:目前 GlowQ 仍属于 Post-training 范畴,对于极低比特(如 2-bit)的恢复能力仍有提升空间。未来,这种基于输入共享的低秩补丁(Patch)思想,有望被推广到 KV Cache 压缩以及多模态大模型的实时推理中。