本文推出了首个城市级真实世界接地(Grounded)视频世界模型 SWM(Seoul World Model)。该模型以首尔为原型,通过检索增强生成的策略,利用街景图像作为视觉锚点,实现了在长达数百米的真实城市轨迹上生成空间忠实、时间连贯且支持文本驱动场景变化的动态视频。
TL;DR
想象一下,在首尔街头实时生成一场电影级的追逐戏,且所有建筑与地标都与现实完全一致。KAIST 与 NAVER AI 联合推出的 SWM (Seoul World Model) 通过将预训练视频扩散模型与海量街景数据库结合,突破了传统世界模型只能“瞎想”的限制,实现了真实地理位置、相机轨迹与文本描述三位一体的精准生成。
背景定位
目前的世界模型(World Models)大多是“想象力过剩”的:给定一个起始帧,它们会构建逻辑自洽但地理虚构的环境。但在自动驾驶虚拟测试或智慧城市规划中,我们需要的是基于真实物理空间的模拟。SWM 的出现,填补了这一空白,将世界模型从“虚幻引擎”带入了“真实世界数据采集”。
痛点深挖:为什么“接地”这么难?
- 瞬时内容干扰 (Temporal Misalignment):你去年拍的街景里停着一辆红车,但模拟器生成的是雨夜,这时参考图里的红车会变成“鬼影”干扰生成。
- 数据极其稀疏:街景车每隔十几米才拍一张,直接拿这些跳跃的图训练,模型会学会“瞬移”而非平滑移动。
- 长程漂移 (Drift):自回归生成每一步都会错一点点,走两百米后,生成的街景早就对不上真实的地图坐标了。
核心方法论:SWM 的三板斧
1. 跨时空配对与语义参考
为了解决瞬时物体干扰,作者提出了 Cross-temporal pairing。在训练时,参考帧和目标帧来自同一地点但在不同时间拍摄。这意味着它们只有建筑布局(Persistent Structure)是重合的。通过这种设计,模型学会了“无视”参考图里的过往行人,只提取建筑底座等永久特征。
2. 模型架构与检索增强
SWM 基于 Cosmos-Predict 模型,通过几何参考(Geometric Referencing)和语义参考(Semantic Referencing)双通道进行调控。
- 几何参考:通过深度图将参考图 Warp 到目标视角。
- 语义参考:直接将原始参考图作为外挂 Token 喂给 Transformer,保留外观细节。
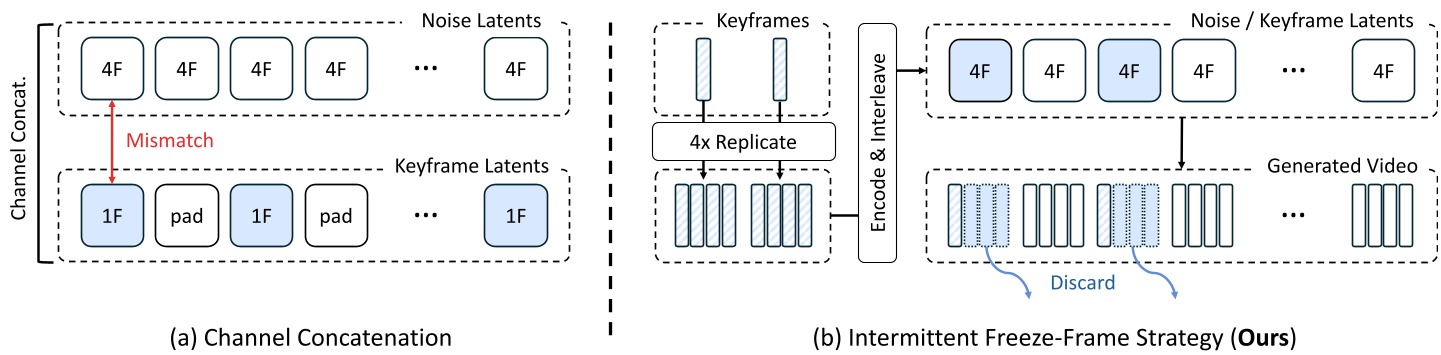 图 1:SWM 总体架构。左侧为基于当前位置的街景检索,中间为双通道引用的 DiT 结构。
图 1:SWM 总体架构。左侧为基于当前位置的街景检索,中间为双通道引用的 DiT 结构。
3. 虚拟前瞻锚点 (Virtual Lookahead Sink)
这是本文最具启发性的设计。传统的 Attention Sink 会永久保留第一帧,但在开出两条街后,第一帧就没用了。SWM 会在生成的每段路径终点(未来位置)检索一张新图作为 Lookahead Sink。模型生成时就像在瞄准一个远处的靶标,保证生成的轨迹始终向真实地理坐标收敛。
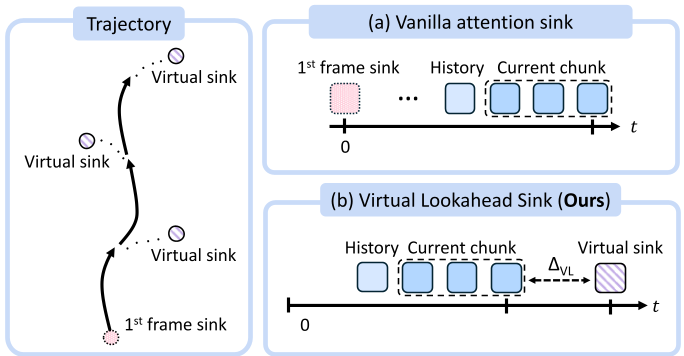 图 2:虚拟前瞻锚点(下)与传统固定锚点(上)的对比。通过动态更新未来锚点,实现了无限里程的生成精度。
图 2:虚拟前瞻锚点(下)与传统固定锚点(上)的对比。通过动态更新未来锚点,实现了无限里程的生成精度。
实验与结果:统治级的性能
研究团队在首尔(训练集)以外的釜山和美国安娜堡进行了测试。结果显示,即便从未见过这些城市,SWM 依然能凭借强大的 RAG 能力准确还原当地建筑风格。
- FID 指标:性能提升接近一倍。
- 相机跟随:在转向和长直道任务中,生成的视角与预设轨迹的对齐度极高。
 表 1:与 SOTA 模型的定量对比。SWM (TF) 在所有几何一致性指标(RotErr, TransErr)上均表现最佳。
表 1:与 SOTA 模型的定量对比。SWM (TF) 在所有几何一致性指标(RotErr, TransErr)上均表现最佳。
深度洞察
SWM 的成功证明了:对于城市级的物理仿真,模型参数里的记忆不如外部数据库的检索可靠。 通过引入虚拟前瞻机制,SWM 给自回归生成戴上了“地理导航”,这彻底解决了视频生成模型在大规模场景下易“跑飞”的顽疾。
局限性
- 数据依赖:如果某个角落没有街景覆盖,生成的质量会退化到普通世界模型的水平。
- 动态性延迟:目前模型生成动态车辆时偶尔会出现“突然消失”的现象,这与底层视图插值流水线的质量有关。
未来展望
随着这类接地世界模型的成熟,未来我们或许可以足不出户,通过文字指令“让家门口的街道变成赛博朋克风格”或“模拟一场五十年一遇的特大洪水”,其对于城市韧性测试和高阶自动驾驶训练的价值不可估量。