本文提出了 GroupEditing,一个旨在对一组相关图像进行一致性、统一化修改的训练框架。该方法将图像组重构为“伪视频”序列,结合了预训练视频模型的隐式时空先验与 VGGT 提取的显式几何对应关系,在多视角图像编辑任务中达到了 SOTA 水准。
TL;DR
在数字资产创作中,如何让一组不同角度的照片(例如同一个角色的多张生活照)同时换上同一件衣服且严丝合缝?香港科技大学与清华等机构提出的 GroupEditing 给出了答案。它突破了单图编辑的范畴,将图像组视为“伪视频”,利用视频模型的时空直觉配合显式几何对齐,实现了跨视角、跨姿态的高保真一致性编辑。
背景定位
传统的图像编辑(如 InstructPix2Pix, MasaCtrl)大都深耕于“单兵作战”。当面对一组图像时,即便使用相同的 Prompt,生成的纹理和轮廓也常常南辕北辙。GroupEditing 在学术坐标系中属于从单图编辑向多图协同编辑(Group-image Editing)跨越的奠基性工作,它首次将大规模视频扩散模型(WAN-2.1)的生成能力直接转化为图像组之间的一致性约束。
痛点深挖:为什么“对齐”这么难?
研究团队指出,多图编辑的核心挑战在于建立可靠的语义对应关系(Correspondences)。
- 语义层面(隐式):模型需要知道多张图中哪部分是“左眼”,哪部分是“Logo”。
- 几何层面(显式):当物体发生旋转或形变时,简单的 Attention 匹配会失效。
现有的 SOTA 方法(如 Edicho)在处理复杂几何变换时往往力不从心,导致编辑后的物体在切换视角时产生“跳变”。
核心内容:显式几何与隐式先验的“联姻”
1. 将图像组伪装成视频
GroupEditing 的第一步极具洞察力:它不把图片看作独立的个体,而是通过 patchify 处理成 Token 序列,喂给预训练的视频扩散模型。视频模型在训练中学习到的“物体随时间平滑移动”的直觉,被直接借用来处理图像间的空间变换。
2. Ge-RoPE:给模型装上“几何义肢”
为了强化几何对齐,作者引入了 Geometry-enhanced RoPE (Ge-RoPE)。
- 模型从 VGGT 提取密集特征。
- 通过位移场(Displacement Field)调整 RoPE 的空间索引,使不同视图中对应的像素点在 Latent Space 中拥有相似的“位置签名”。
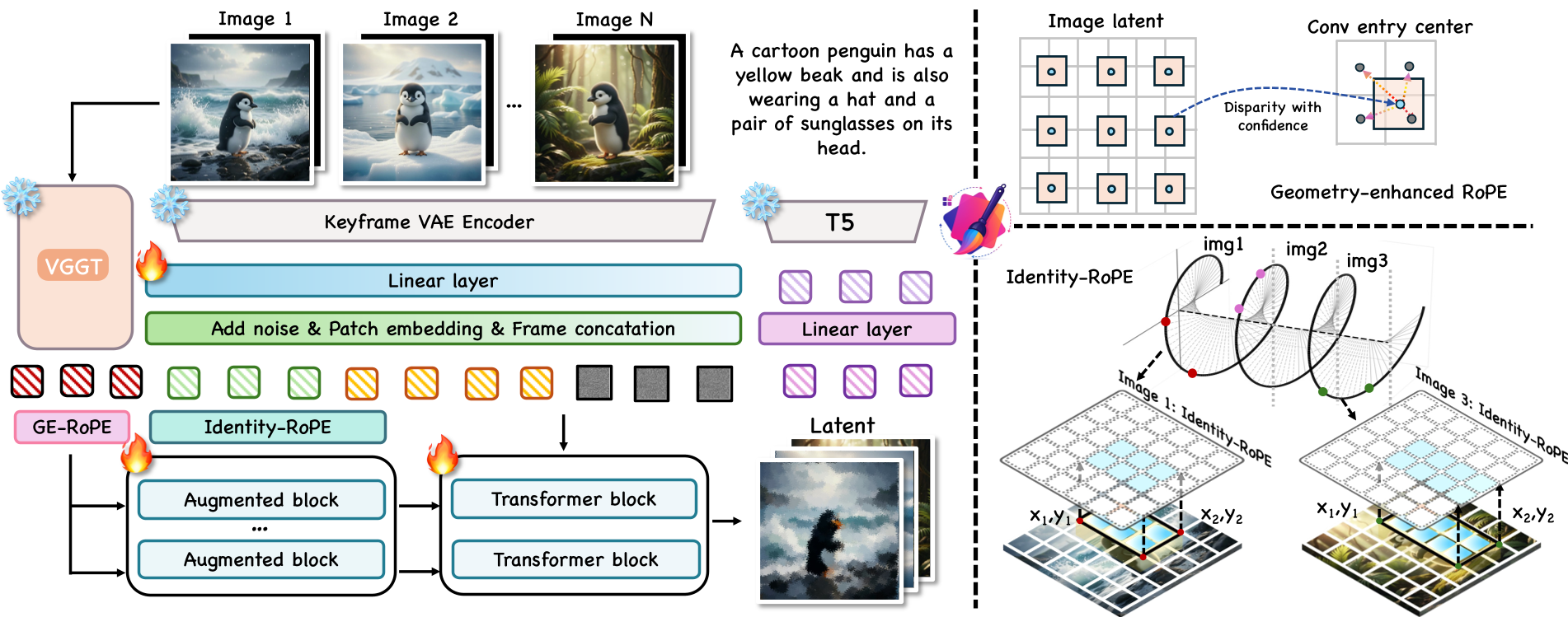 图注:GroupEditing 整体架构。左侧为基于视频模型的 Pipeline,右侧展示了 Ge-RoPE 和 Identity-RoPE 的对齐机制。
图注:GroupEditing 整体架构。左侧为基于视频模型的 Pipeline,右侧展示了 Ge-RoPE 和 Identity-RoPE 的对齐机制。
3. Identity-RoPE:身份守护者
在编辑人物或特定物体时,Identity 的一致性至关重要。作者设计了 Identity-RoPE,它利用 Bounding Box 归一化坐标,确保无论物体在图中哪个位置,其对应的 Token 都能获得一致的身份编码。
实验与结果:全方位碾压
团队构建了 GroupEditData(包含 7k+ 组数据)和 GroupEditBench(800 组基准)。
实战表现
在与 Anydoor, OminiControl 等强力基线的对比中,GroupEditing 在局部编辑(如给狐狸穿上盔甲)和全局风格化(如将吉普车变为水彩风)上均展现了极强的稳定性。
 图注:可视化对比。可以看到 GroupEditing 在多图联动时,物体的细节特征(如颜色、装甲结构)保持得极为稳健。
图注:可视化对比。可以看到 GroupEditing 在多图联动时,物体的细节特征(如颜色、装甲结构)保持得极为稳健。
量化提升
- 一致性:DINO-Score 达到了 0.8168,远超同类框架。
- 审美评分:Aesthetic-Score 提升至 5.39,证明了模型生成的视觉质量。
- 下游赋能:编辑后的图片可直接用于 3D 重建(如 Must3R),生成具有一致纹理的 3D 模型。
深度洞察与总结
GroupEditing 的成功验证了一个关键假设:视频模型蕴含的运动/空间变换规律,是解决静态图像间一致性问题的“银弹”。
局限性: 虽然在语义对齐上表现卓越,但对于极端视角(如正视图到完全背视图)的重度遮挡区域,模型仍存在一定的推测性伪影。
未来展望: 这一技术将直接赋能虚拟主播、电商全视角广告展示以及影视角色一键换装等工业场景。随着视频生成模型底座的不断进化,GroupEditing 这种“借力打力”的思路将成为多媒体编辑领域的主流架构。