本文提出了 Group3D,一个基于多视图 RGB 输入的开放词汇(Open-Vocabulary)3D 物体检测框架。该方法通过引入多模态大语言模型(MLLM)驱动的语义兼容性分组策略,协同几何一致性进行 3D 实例构建,在 ScanNet 和 ARKitScenes 基准测试上刷新了多视图 SOTA 记录。
在 3D 视觉领域,**开放词汇(Open-Vocabulary)**检测一直是通向通用机器人的圣杯。然而,依赖昂贵的 LiDAR 数据或预定义的标签类别限制了其应用。最近,韩国成均馆大学与延世大学的研究团队提出了 Group3D,证明了仅凭普通的 RGB 视频流,配合大语言模型的语义直觉,就能在 3D 空间中实现精准的物体定位与识别。
1. 核心速览
TL;DR:Group3D 是一套无需 3D 标注训练、直接作用于多视图 RGB 图像的 3D 检测框架。它通过 MLLM 指导的语义兼容分组,解决了多视图合并中常见的“过度合并”痛点,在 ScanNet 等基准上大幅领先现有方法。
背景定位:该工作属于 Training-free / Zero-shot 3D 感知路线。它不依赖现有的 3D 边界框训练,而是巧妙地将 2D 基础模型(SAM)、深度估计算法与大语言模型(GPT-4/5 等)结合。
2. 痛点:被误导的几何一致性
在传统流程中,系统会将不同视角下的物体碎片(Fragments)像拼图一样合并。如果几何证据是完美的,这没问题。但在实际 RGB 序列中:
- 深度估计有误差:导致两个靠近的物体在 3D 空间中“挤”在了一起。
- 视角遮挡:几何信息不完整,算法以为它们是一个整体。
这种**纯几何驱动(Geometry-only)**的合并一旦出错,后续语义识别再强也无法把由于误合并而连在一起的“书架”和“柜子”分开。
3. 核心机制:语义兼容分组(Semantic Grouping)
Group3D 的直觉非常深刻:如果语言模型告诉你这两个东西在语义上不可能是一个物体(比如“墙”和“门”),那么即便它们在几何位置上重叠,也不应该合并。
架构详解
其工作流程分为三步:
- 场景记忆构建:通过 MLLM 扫描各视图,提取该场景特有的词汇表。
- 语义兼容性建模:利用 MLLM 将词汇表分组。例如,由于命名模糊性,“沙发”和“长椅”可能被分在同一组,允许合并;但“桌子”和“杯子”必须严格分开。
- 语义门控合并:在合并 3D 碎片时,除了检查空间重叠(Voxel Overlap),还必须通过“语义分组”这道门槛。
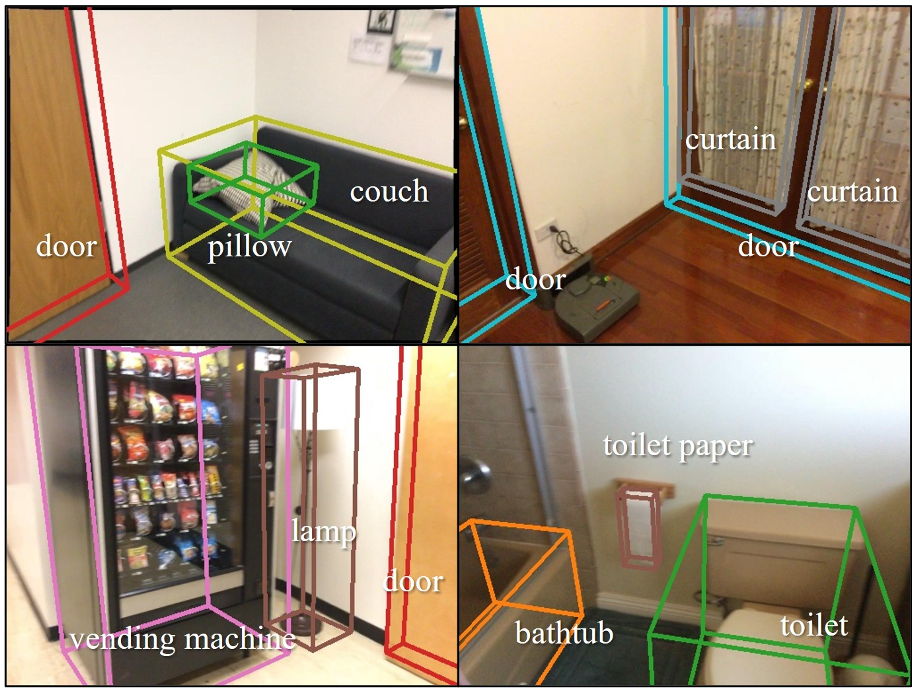 Group3D 利用语义约束引导实例构建,有效避免了因几何模糊导致的错误关联。
Group3D 利用语义约束引导实例构建,有效避免了因几何模糊导致的错误关联。
4. 实验战绩:多视图下的惊人表现
Group3D 在多个数据集上展现了统治力。特别是在 Pose-free(姿态未知) 的极端条件下,它比之前的 SOTA 方法 Zoo3D 提升了近 17 个百分点(mAP25 从 24.2% 提升至 41.2%)。
关键实验发现
- 不仅是检测,还能分割:虽然主要任务是检测,但生成的 3D 实例质量极高,在 ScanNet200 的实例分割任务上也表现不俗(AP50 达到 12.2%)。
- 对 MLLM 的依赖度:消融实验显示,使用 GPT-5.1 这种顶级模型效果最佳,但更换为 8B 规模的高效模型(如 Qwen-VL)依然能保持稳健性能,证明架构本身具有普适性。
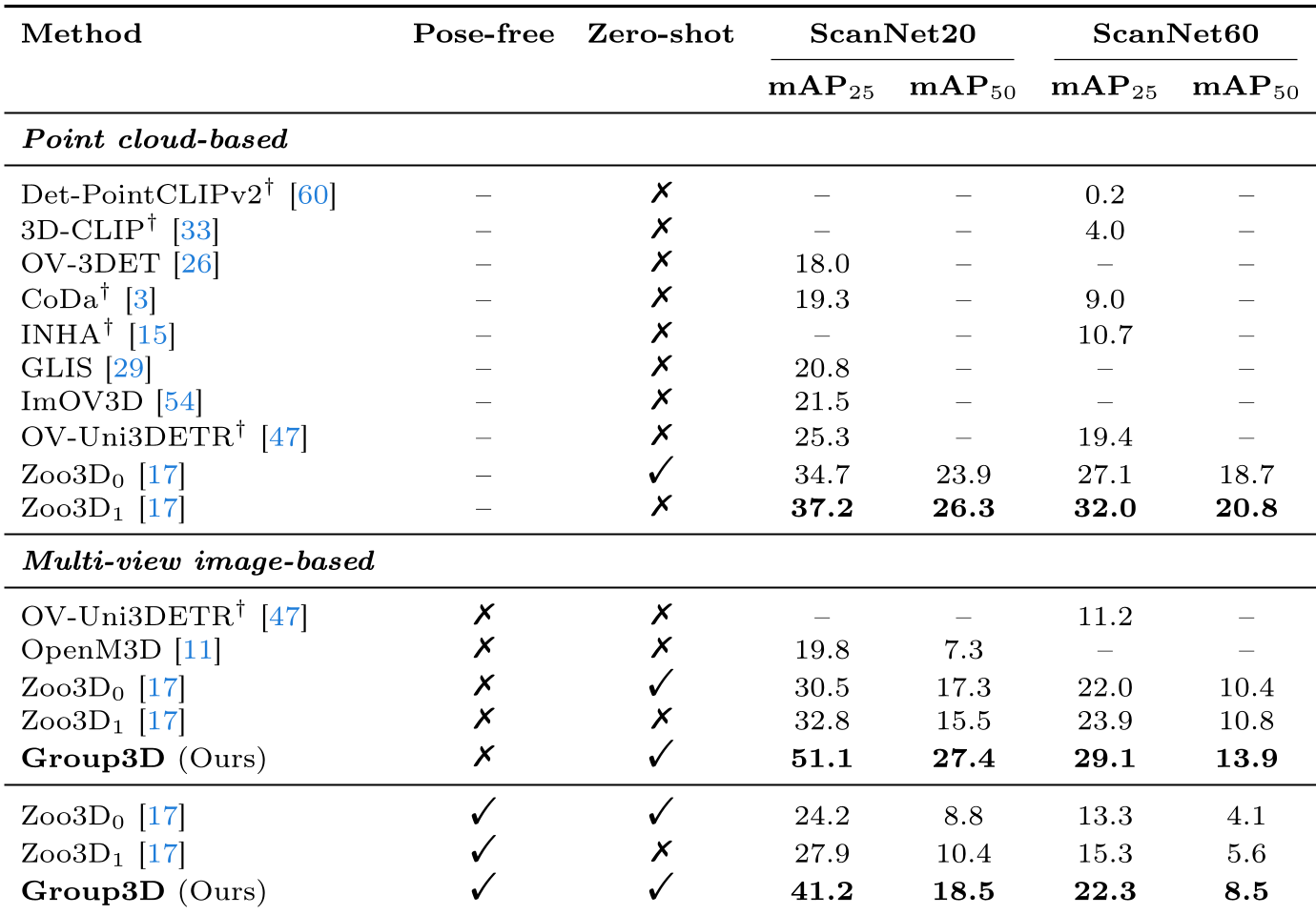 表 1 显示 Group3D 在各类设置下均显著优于现有方法。
表 1 显示 Group3D 在各类设置下均显著优于现有方法。
5. 深度洞察与总结
Group3D 的成功秘诀在于“提前干预”。它没有把语义理解当作最后贴标签的步骤,而是将其作为 3D 结构构建的基础约束。这种“语言引导几何”的思路,为解决 3D 重建中的噪声和歧义性提供了极其经济且高效的新路径。
局限性:目前的系统依赖于预先确定的候选类别数量(K=5),且对于极其精细化的长尾物体,MLLM 的分组逻辑还需要更强的感知对齐。
未来启示:随着 MLLM 的推理成本降低,未来的自动驾驶或家用机器人或许不再需要笨重的预训练 3D 模型,而是通过类似 Group3D 的逻辑,在实时交互中动态理解周围未曾见过的世界。