本文提出了 GSMem,一个基于 3D Gaussian Splatting (3DGS) 的零样本具身探索与推理框架。该框架将 3DGS 作为持久性空间记忆,通过神经辐射场实现高质量的新视角合成,使智能体具备在 Embodied AI 任务中“回溯”并从最优视角观察已探索区域的能力。
TL;DR
具身智能领域长期面临一个令人头疼的问题:如果机器人走过去时没看清某个东西,它就永远“丢”了这份记忆。GSMem 改变了这一现状。它利用 3D Gaussian Splatting (3DGS) 构建了一个持久的、可实时渲染的 3D 空间存储。即使机器人物理上已经离开,它也可以在脑海中对旧场景进行“事后重观测”,从任意最优视角恢复细节,彻底解决了视觉遮挡和感知漏检带来的记忆断层。
背景定位:从“幻灯片”记忆到“全息”记忆
传统的具身智能体主要依靠两种记忆模式:
- 对象级抽象(Object-centric):把房间存成一张图谱(Scene Graph),但这依赖于目标检测的准确率。
- 视图级快照(View-based):存一堆照片。但照片是死的,角度不对就看不见背后的东西。
GSMem 在学术坐标系中属于向连续辐射场记忆进化的前沿工作。它将 3D 场景参数化为数百万个高斯点,不再是离散的点云或简化的语义标签,而是一个可以随时“回去看看”的 3D 电影。
痛点深挖:不可挽回的遗忘
作者指出,人类在回忆时可以脑补出不同角度的细节,但当前 AI 却被“锁定”在初始视角。比如,如果机器人最初经过衣架时由于角度太偏没识别出“白袍”,在离散场景图中这个信息就永久丢失了。这种视觉依赖性和分辨率限制是零样本具身推理(Zero-shot EQA)的致命伤。
核心方法论:空间回忆(Spatial Recollection)
1. 3DGS 映射与在线语言场
GSMem 不仅仅存 RGB,它还为每个高斯点赋予了一个 CLIP 嵌入向量。
- 优化: 为了实时性,它没有用复杂的 3D 优化,而是通过“权重一致反向聚合(Weight-consistent reverse aggregation)”,将 2D 特征直接升维到 3D 高斯点上。
- 多层级检索: 结合了“显式对象标签”和“隐式语义场”,即便分类器认不出某个奇怪的花瓶,CLIP 语义场也能通过“艺术感、陶瓷”等描述定位到它。
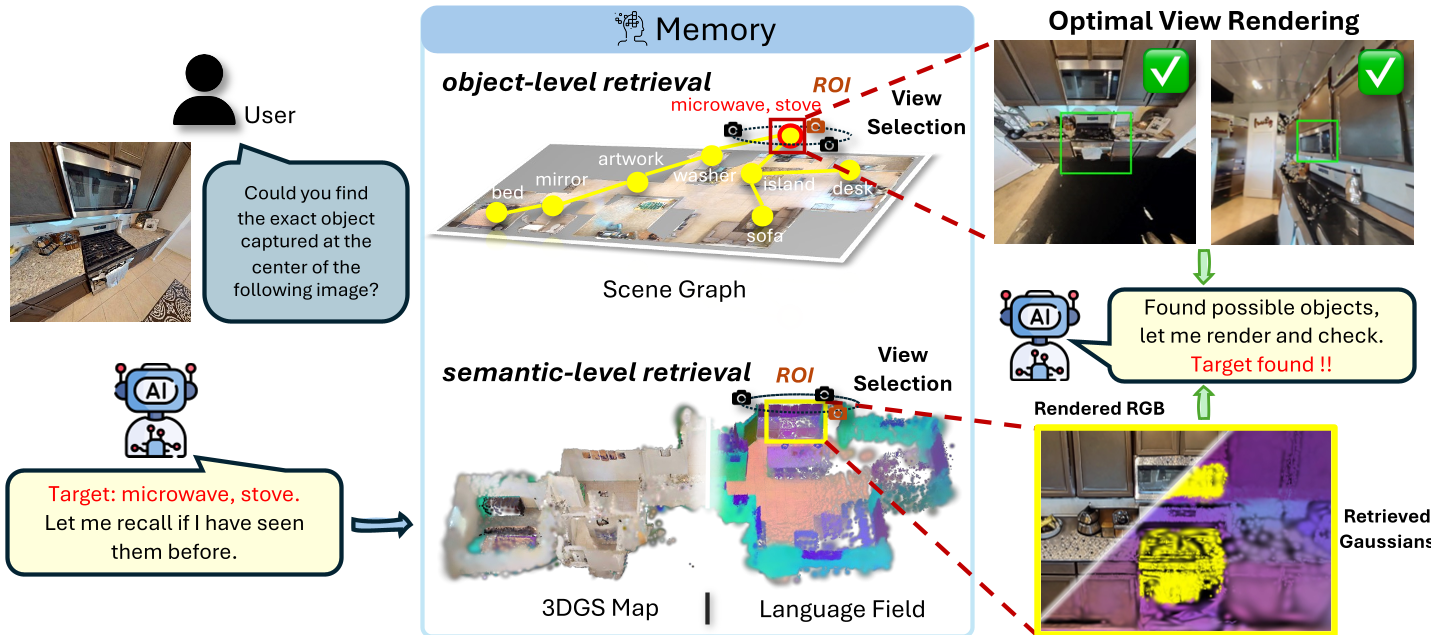
2. 最优视图幻视(Hallucinate Optimal Views)
当 VLM 提出疑问(如“那个白袍在哪?”)时,GSMem 的核心大招是:
- 采样路径: 在 ROI 区域周围采样 108 个候选相机位姿。
- 多阶段打分: 考虑几何可见性(Ray Marching)、投影面积、以及 3DGS 特有的不透明度分数 (Opacity Score)。
- 视觉重构: 选出那个能看清细节的最佳位姿进行渲染。
3. 混合探索:语义与几何的双重驱动
机器人该去哪?GSMem 给出了一个优雅的权衡公式:
- 语义得分: VLM 说这块可能有答案,那就优先去。
- 几何得分: 利用 Fisher Information Matrix (FIM) 的迹作为代理指标,评估哪些区域的 3DGS 参数还不确定。如果语义没线索,就去填补几何空白。
实验战绩
在 OpenEQA 和 GOAT-Bench 两大硬核榜单上,GSMem 均表现出色:
- 更强的鲁棒性: 在对比实验(Fig 4)中,当目标检测器因错误识别(如把白门认成冰箱)而失效时,GSMem 凭借连续的语言场依然完成了定位。
- 长程记忆: 在终身导航任务中,GSMem 的成功率比之前的 SOTA(3D-Mem)高出约 4.3%。

深度洞察与总结
Takeaway: GSMem 的本质是利用 3DGS 的生成能力 来弥补 感知模型的识别不足。它不仅是存储,更是一种具有“推理能力”的存储。
局限性: 尽管推理速度优化到了 1.2s 每帧,但 3DGS 在极度稀疏观测下的渲染质量仍依赖于扩散模型的后处理(Ablation 证明了 Diffusion 的价值)。此外,对于动态场景(人来人往的房间),如何保持 Gaussian 记忆的一致性仍是未来挑战。
展望: 随着单步扩散模型和 3DGS 硬件加速的成熟,这种“具有后验重观测能力的持久记忆”可能成为下一代家用服务机器人的标配架构。