小米 HyperAI 团队发布了 GUI-CEval,这是首个针对中文移动生态定制的分层级、全流程 GUI Agent 评测基准。通过在真实物理设备上采集 201 个主流 App 数据,该基准评价了模型从感知到执行的完整链路,实验表明 Qwen2.5-VL 和 UI-TARS 等模型在中文环境下虽处于领先地位,但复杂交互成功率仍待提高。
TL;DR
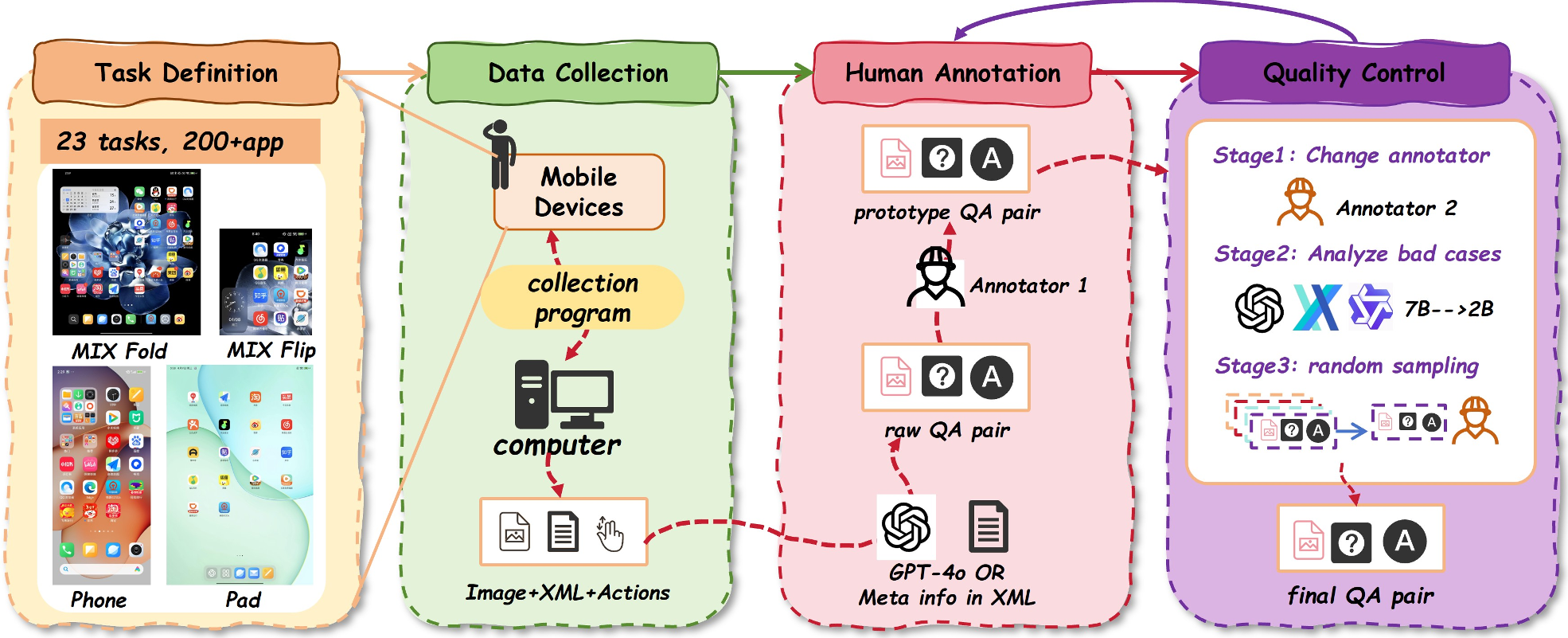
随着多模态大模型(MLLM)的爆发,能够像人一样操作手机的“智能体”已初具雏形。然而,由于中文移动生态的特殊性,现有的英文评测基准已显得捉襟见肘。小米 HyperAI 团队近日推出的 GUI-CEval,通过 201 个真实 App、四类物理设备以及 8,000+ 测试任务,构建了一个覆盖“感知-规划-反射-执行-评估”全链路的中文 GUI Agent 诊断框架。
1. 痛点:为什么 AndroidWorld 不足以评测中文模型?
尽管业界已有 AndroidWorld、ScreenSpot 等知名基准,但它们在评价中文 GUI Agent 时存在三大软肋:
- 语言与环境错配:多数基准基于英文应用,无法捕捉中文特有的交互逻辑(如复杂的支付流、特有的权限弹窗)。
- 任务维度片面:往往只侧重于“点哪里”(Grounding)或“离线预测”,忽略了 Agent 在执行错误后的“自我修复”(Reflection)和“结果判定”(Evaluation)能力。
- 数据脱离真实:自动化采集往往缺乏真实用户的真实意图,导致评测结果与实际体验严重脱节。
2. 方法论:分层诊断模型能力的“全身扫描”
GUI-CEval 并没有简单地给出一个“成功率”分数,而是将 Agent 的能力拆解为两个层级:
2.1 基础任务 (Foundation Tasks)
通过多模态 QA 形式,将原子能力解耦为五个维度,精确诊断模型在哪一步“掉链子”:
- Perception (感知):不仅仅是 OCR,还包括对图标功能、页面属性(广告、支付、授权)的理解。
- Planning (规划):测试全局任务分解能力。
- Reflection (反射):这是目前多数模型的死穴——当操作失误后,模型能否识别并回滚?
- Evaluation (评估):执行完后,模型是否真的知道任务成功了?
2.2 应用任务 (Application Tasks)
在真实物理设备(手机、平板、折叠屏)上运行,分为 GUI Grounding(定位)、Offline Agent(轨迹复现)和 Online Agent(在线实战)。
3. 实验发现:SOTA 模型距离“好用”还有多远?
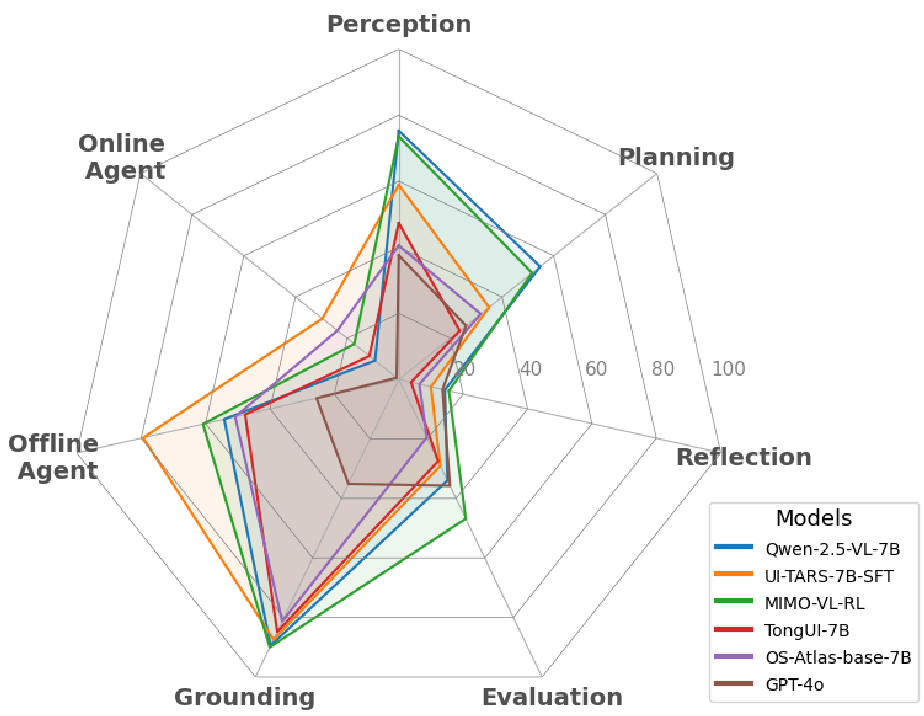
作者对 20 个代表性模型(包括 GPT-4o、Qwen2.5-VL、UI-TARS 等)进行了横向评测,核心发现令人深思:
3.1 Qwen 系列统治中文榜单,GPT 表现平平
数据显示,Qwen2.5-VL-72B 在综合评分上领跑(61.41%),紧随其后的是专门针对 UI 优化的 UI-TARS。令人意外的是,GPT-4o 家族在中文 GUI 任务上的表现远逊于国产开源模型,这证明了 Domain-specific Fine-tuning 和 中文语料积累 在移动 Agent 领域的决定性意义。
3.2 恐怖的“长链条崩溃”
实验揭示了一个冷酷的事实:执行步数是 Agent 的杀手。当任务在 3 步以内时,多数模型还能支撑;但当操作步骤超过 6 步,几乎所有模型的成功率都出现了“断崖式”跌落(接近 0%)。这意味着错误累积和状态漂移(State Drift)依然是目前未被攻克的难题。
4. 深度洞察:未来的突围方向
- 感知≠执行:模型的视觉感知已经相当成熟(Grounding 准确率可达 90% 以上),但如何将感知转化为稳定的长程决策才是关键。
- 反射能力的稀缺:实验证明,大部分 MLLM 在 Reflective Reasoning 上得分极低。模型缺乏在动态环境中“回头看”的直觉。
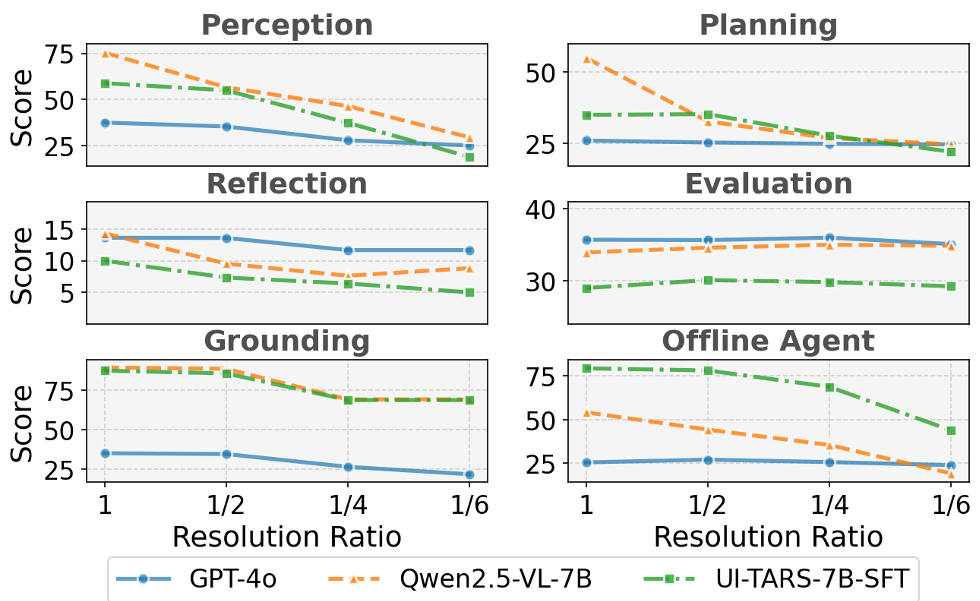
- 分辨率的微妙影响:研究发现,分辨率减半对感知影响可控,但一旦降至 1/6,模型表现会全面崩盘。这为端侧部署的图片压缩算法提供了边界参考。
总结
GUI-CEval 的发布,不仅为中文移动 Agent 提供了一把更精准的“尺子”,更揭示了目前学术界与工业界最难攻克的阵地:长时序任务的稳定性与错误自修复。对于开发者而言,单纯堆算力或扩大模型规模的边际效应正在递减,引入过程监督(Process Supervision)和强化学习(RL)来强化“反射”能力,或许是通往真正的“手机超级助手”的必经之路。