本文提出了 HiMu,一种用于长视频问答(VideoQA)的无须训练的分层多模态帧选择框架。它通过将复杂查询分解为逻辑树并调用轻量级专家模型(CLIP, YOLO, Whisper等)提取信号,在保持极高推理效率的同时,显著提升了长视频理解的准确性。
1. 核心速览(Executive Summary)
TL;DR:以色列本·古里安大学的研究团队提出了一款名为 HiMu (Hierarchical Multimodal) 的视频帧选择框架。它通过将用户的自然语言问题分解为严密的“层次逻辑树”,调动音频、视觉、文字等多模态专家进行协同检索,仅凭 16 帧 采样就在长视频问答任务上击败了许多处理数百帧的重量级 Agent 模型。
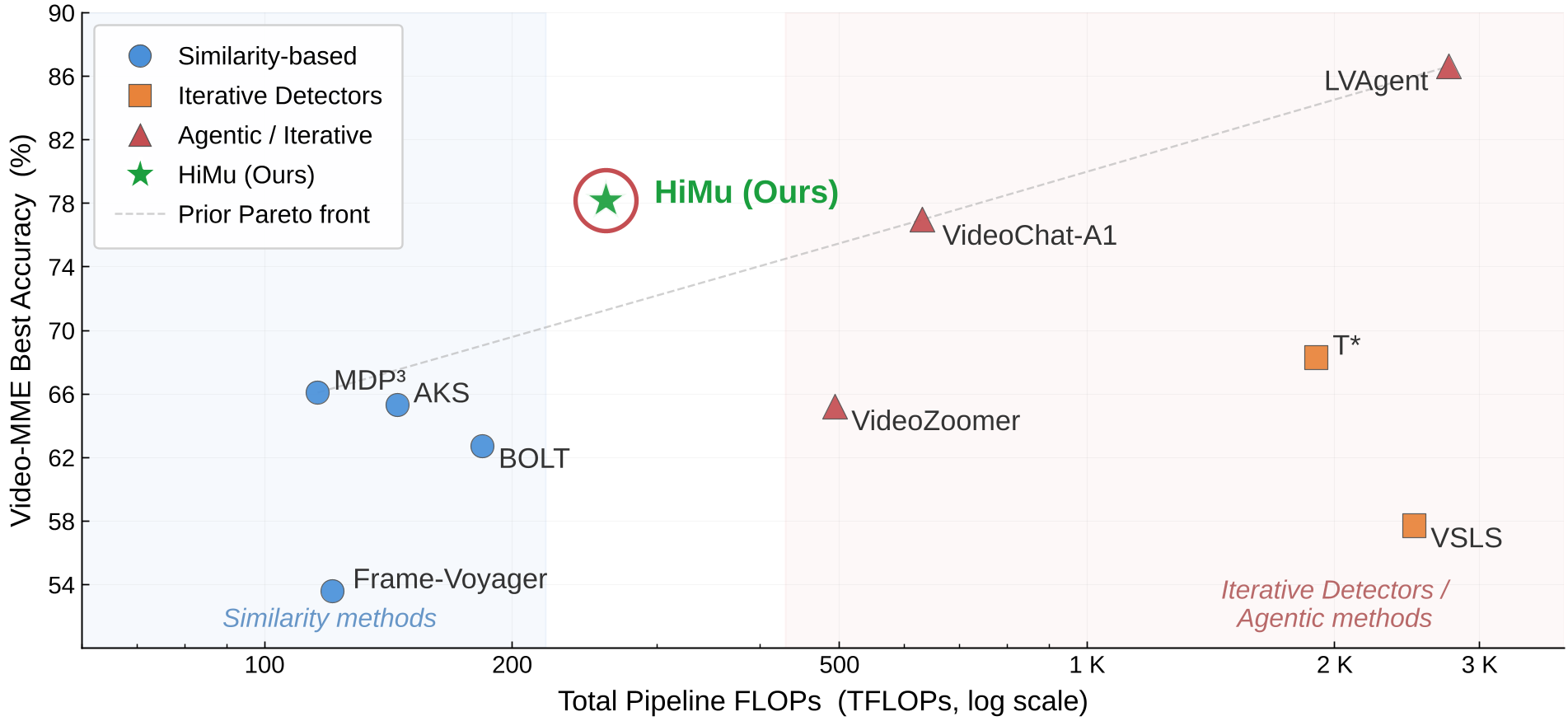
背景定位:在 Video-MME 等长视频基准测试中,HiMu 成功打破了原有“要么快但笨(相似度采样),要么准但极慢(Agent 迭代)”的僵局,成为了当前**效率-准确率帕累托前沿(Pareto Front)**的新标杆。
2. 痛点深挖:为什么 LLM 看不明白长视频?
处理 10 分钟甚至 1 小时的视频,由于显存和计算复杂度的限制,我们不能把所有帧都塞给大模型(LVLMs)。目前的解决思路主要分两派,但各有硬伤:
- 相似度派 (Similarity-based):比如用 CLIP 算算哪一帧和问题最像。缺点是它太“平”了,无法理解因果和时序。如果你问:“厨师说完秘密配方以后加了什么?”,模型分不清“以后”这个逻辑。
- 智能体派 (Agentic methods):让模型反复看视频、搜索、再看。缺点是贵得离谱,处理一个视频可能要消耗 100 倍以上的计算资源(FLOPs)。
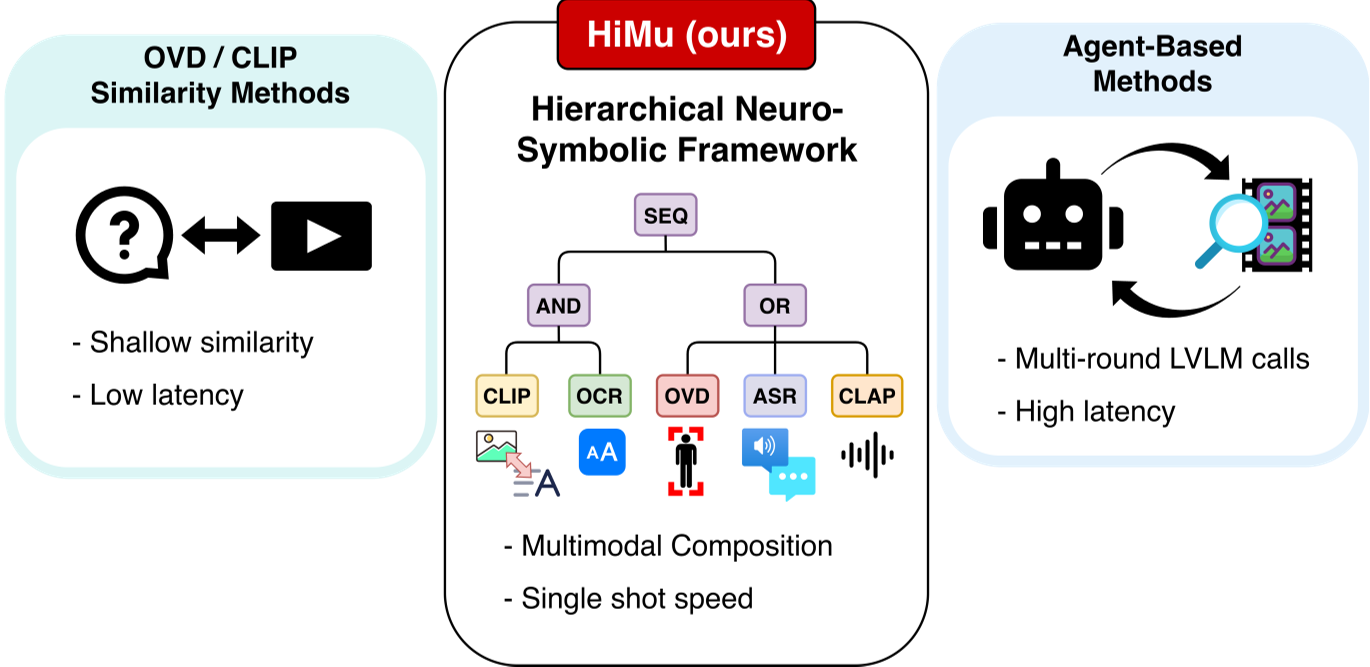
3. 方法论详解:神经符号逻辑赋能多模态
HiMu 的核心直觉在于:复杂的查询本身就隐藏着结构化的逻辑。 其流程分为以下四步:
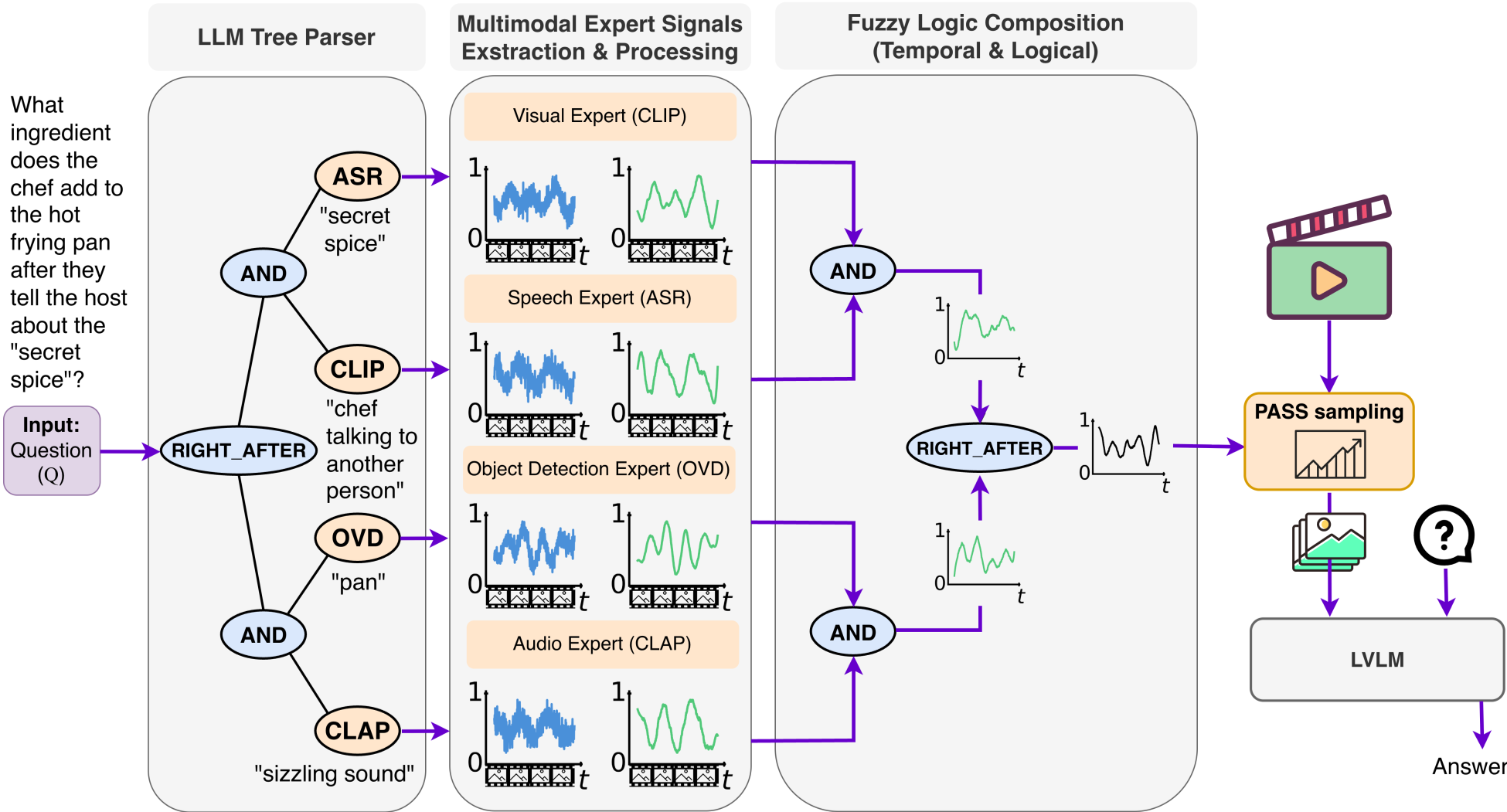
A. 逻辑树分解 (Logic Tree Decomposition)
系统首先调用一个纯文本 LLM(如 Qwen 或 GPT),将问题化解为一个逻辑图。
- 叶子节点:具体的检测任务。比如
OVD("红色的车"),ASR("化学反应")。 - 内部节点:逻辑算子。包括
AND(同时出现)、OR(选其一)、SEQ(按顺序发生)、RightAfter(紧随其后)。
B. 专家联合作战 (Multimodal Experts)
HiMu 首次将音频作为帧选择的一等公民。
- 视觉专家:CLIP(场景)、YOLO-World(物体检测)、OCR(屏幕文字)。
- 音频专家:Whisper (ASR 语音转文字)、CLAP (环境音,如“玻璃破碎声”)。
C. 模糊逻辑合成与采样
不同专家的信号量纲不同,HiMu 通过 Median/MAD 归一化和带宽匹配平滑,将这些破碎的信号映射到 0-1 之间的满意度曲线上。通过自底向上的计算,最终得出一张全视频的“逻辑匹配热力图”。
4. 实验与结果:降维打击
实验结果令人震惊。在 Video-MME 等三个主流榜单上:
- 以少胜多:HiMu 在 16 帧下的表现,不仅吊打所有相似度基线,甚至在某些长视频任务中超过了输入 128~512 帧的传统模型。
- 即插即用:无论是开源的 Qwen、InternVL 还是闭源的 GPT-4o,换上 HiMu 的帧选择器后,性能均有显著跃升。
- 消融实验:结果证明“逻辑结构”比单个专家的性能更重要。去掉逻辑树、改用简单的信号叠加,性能会骤降 5.49%。
5. 深度洞察:为什么这种方式更优?
HiMu 的成功揭示了当前长视频理解的一个误区:性能瓶颈不在于模型能看多少帧,而是在于模型看的是不是精准。 此外,HiMu 提供了极佳的可解释性。每一帧被选中的理由都可以追溯到逻辑树中的某一个分支(见下方热力图),这对于工业界调试和优化 VideoQA 系统具有巨大的实战价值。

6. 局限性与展望
尽管 HiMu 在效率上实现了飞跃,但它仍依赖于初始 LLM 对逻辑树分解的准确性。如果问题本身极其模糊,逻辑树可能会误导专家。未来的研究方向可能在于如何让逻辑树具备自我纠错或动态调整的能力。
总结:HiMu 是神经符号推理在多模态领域的重磅回归,它告诉我们,在 AI 暴力计算的时代,精巧的逻辑结构依然能产生意想不到的巨大价值。