本文提出了 HopChain,一个用于合成多步(Multi-hop)视觉语言推理数据的自动化框架。该框架通过构建逻辑依赖的实例链,显著提升了视觉语言模型(VLM)在强化学习(RLVR)训练后的泛化推理能力,在 Qwen3.5 系列模型上实现了 20/24 个基准测试的性能突破。
TL;DR
视觉语言模型(VLM)虽然在简单问答上表现出色,但在需要多步观察的复杂任务中经常“掉链子”。阿里 Qwen 团队与清华大学联合推出的 HopChain 框架,通过合成具有强逻辑依赖的 Multi-hop(多步跳转) 数据,强制模型在长链思考(CoT)的每一步都必须回看图像寻证。实验证明,这一方法不仅提升了模型在静态图像上的推理,甚至跨领域增强了视频理解能力。
痛点深挖:为什么 CoT 在视觉领域会“断裂”?
在纯文本 LLM 中,CoT 已经证明了其逻辑推演的强大。但在 VLM 中,研究者发现了一个尴尬的现象:推理链越长,模型越容易产生视觉脱节。
作者通过对 Qwen3.5 的错误分析发现,长链推理中的 failure modes 非常多样:
- 感知错误(Perception Error):数错了点数或看错了颜色。
- 复合错误(Compounding Errors):第一步看错,后面五步基于错误的前提推导,看似逻辑通顺实则全是幻觉。
- 证据漂移(Evidential Drift):模型在推理中后期开始过度依赖语言先验,不再查阅图像。
核心矛盾:现有 RLVR(可验证奖励强化学习)数据往往是单步或浅层推理,无法逼迫模型在推理过程中反复进行视觉重锚定(Visual Re-grounding)。
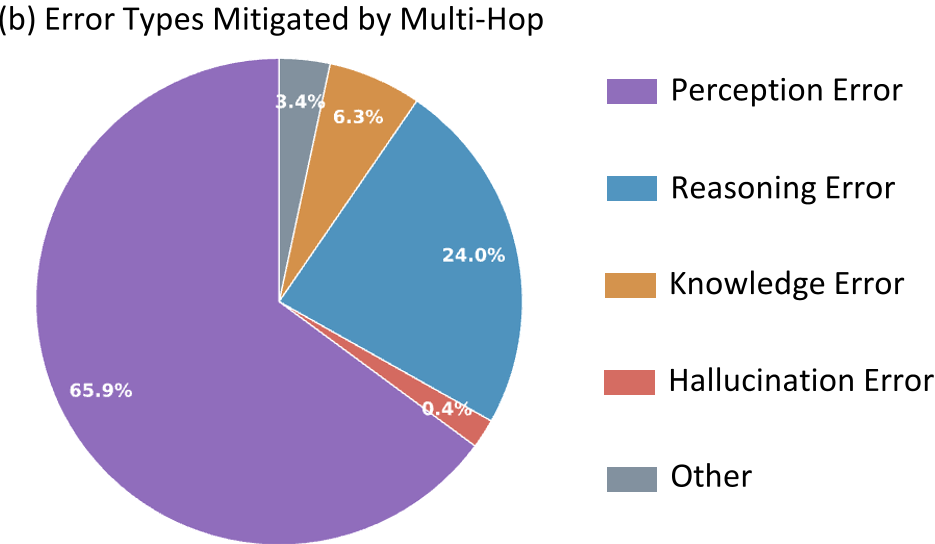 图注:感知和推理错误是导致模型失败的主要因素,且常常交织在一起。
图注:感知和推理错误是导致模型失败的主要因素,且常常交织在一起。
核心机制:HopChain 的多步跳转设计
为了训练模型“每走一步都要看一眼地图”,HopChain 提出了两种维度的跳转:
- Perception-level Hop (感知层跳转):在单对象感知(如:读取文字)和多对象关系(如:比较大小)之间切换。
- Instance-chain Hop (实例链跳转):形成 A → B → C 的依赖链。例如:“先找到穿红衣服的人 -> 找到他手里提的包 -> 识别包上的 Logo 字符数量”。如果不看第一步的红衣人,你根本无法定位后面的包和 Logo。
自动化合成流水线
HopChain 并不依赖昂贵的人工标注,而是通过一个四阶段的 Pipeline 规模化生产:
- Stage 1 & 2:利用 Qwen3-VL 识别语义类别,并结合 SAM 3 进行精确的实例分割,获取物体的 Bounding Box 和遮罩。
- Stage 3:生成多步查询。强制要求查询必须包含 3-6 个实例,且答案必须是可验证的数字(Verifiable Rewards)。
- Stage 4:基于人类反馈的质量标定,剔除过于简单的样本。
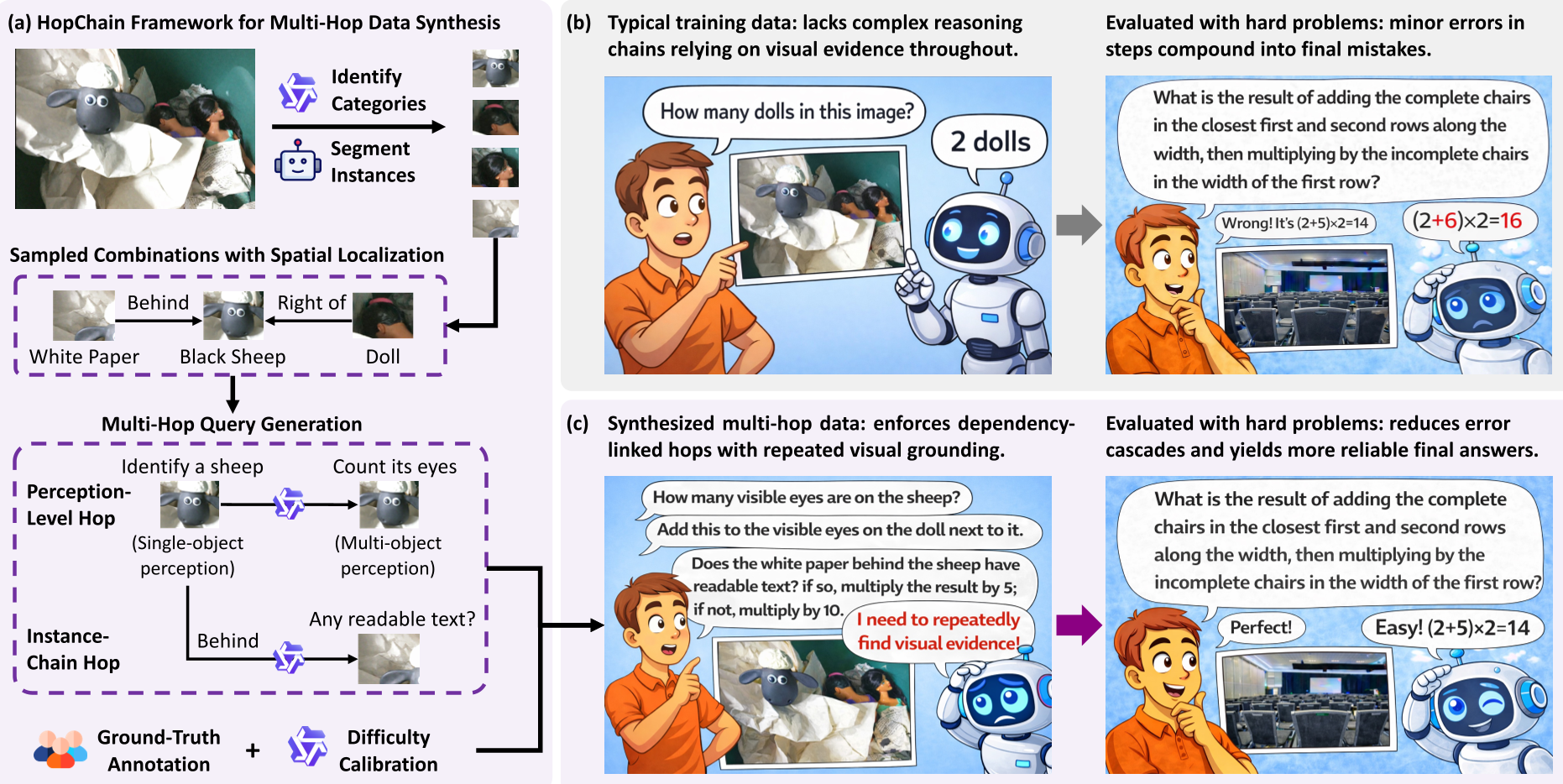 图注:HopChain 从图像识别、分割到最后的多步查询生成的全流程。
图注:HopChain 从图像识别、分割到最后的多步查询生成的全流程。
实验战绩:泛化能力的全面觉醒
研究团队在 Qwen3.5-35B 和 Qwen3.5-397B 两个规格上进行了验证。结果极其亮眼:
- 普遍性提升:在 24 个测试基准中,20 个都取得了 SOTA 级别的突破。
- 长 CoT 之王:在超长响应(Ultra-long regime)中,HopChain 带来的准确率提升超过了 50 个点。这说明模型真正学会了在长时间思考中保持对视觉证据的忠诚。
- 跨模态泛化:最神奇的是,虽然 HopChain 只用静态图片合成数据,但在 VideoMME 等视频理解榜单上同样表现出色。这意味着模型习得了某种通用的、具备逻辑深度的视觉观察策略。
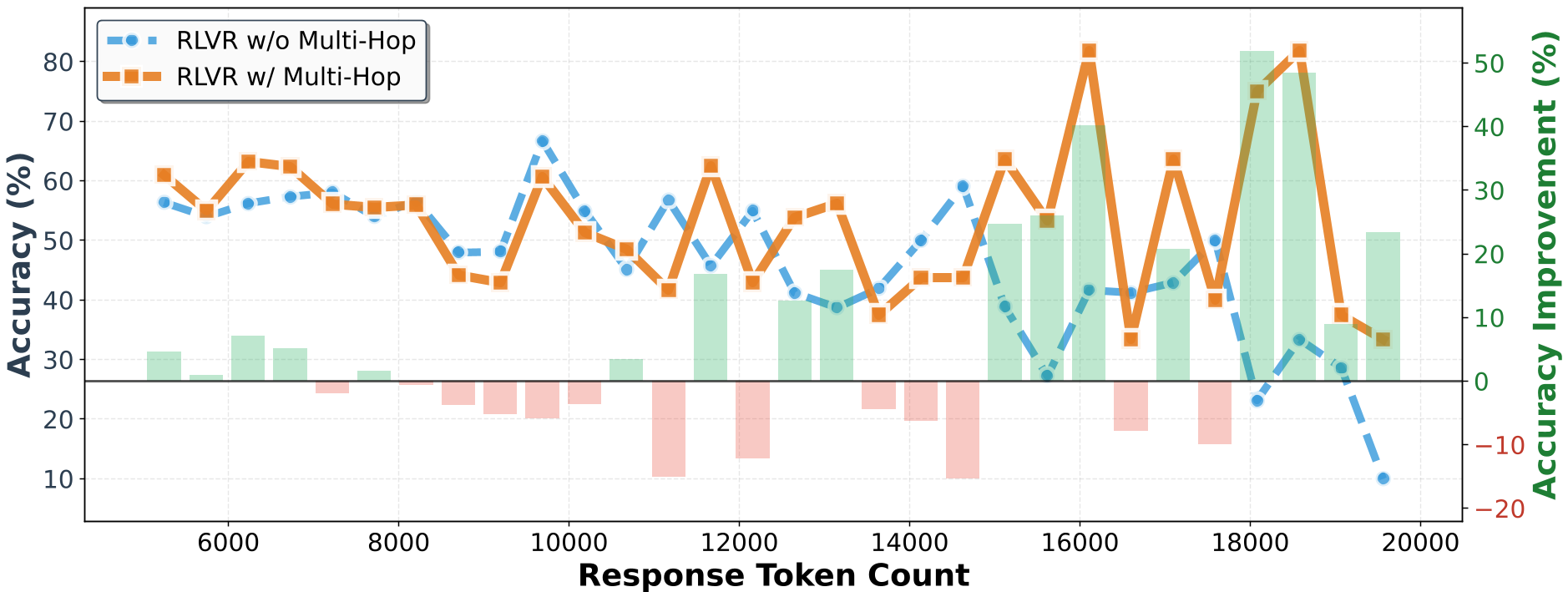 图注:随着推理步数增长,HopChain 的优势愈发显著(橙色实线 vs 蓝色虚线)。
图注:随着推理步数增长,HopChain 的优势愈发显著(橙色实线 vs 蓝色虚线)。
深度洞察:为什么这种合成数据有效?
HopChain 的成功向我们揭示了 VLM 训练的一个重要范式转变:数据质量不等于图像质量,而在于任务的逻辑拓扑。
传统的 VLM 训练集往往是“所见即所得”,而 HopChain 构建的是一种“逻辑迷宫”,它封死了语言模型的“捷径”。当模型意识到不看图就得不到中间变量 A,进而无法推导 B 时,它才真正被迫开启“深度思考”模式。
局限性与展望
目前 HopChain 仍依赖于实例分割(SAM 3)的成功率。对于那些没有清晰物体边界的抽象图像(如纹理、自然风景),HopChain 尚显乏力。作者指出,未来的方向是如何在无实例物体的情况下,依然构建起逻辑依赖的视觉推理链。
总结:HopChain 证明了,通过结构化的数据工程,我们可以有效地将 VLM 从“视觉浅尝辄止”引向“深度视觉推理”。这是迈向通用多模态智能(AGI)的关键一步。