本文推出了 INSPATIO-WORLD,一个支持实时交互的 4D 世界模拟器。该框架基于时空自回归(STAR)架构,能够从单目视频中恢复并生成高保真动态场景,在 WorldScore-Dynamic 榜单中位列实时模型第一,并在 H 系列 GPU 上达到 24 FPS 的运行速度。
TL;DR
构建具有空间一致性和实时交互能力的“世界模型”一直是计算机视觉的圣杯。INSPATIO-WORLD 通过创新的时空自回归(STAR)架构和联合分布匹配蒸馏(JDMD),首次在消费级显卡上实现了高保真的 4D 场景实时漫游。它不仅解决了长程生成中的“空间漂移”痛点,还通过双教师蒸馏机制消除了合成数据的“塑料感”,让单目视频生成的虚拟世界达到了电影级的真实感。
痛点深挖:为什么现有的世界模型会“崩坏”?
在处理超长序列或大范围相机移动时,目前的视频扩散模型常遇到三大瓶颈:
- 空间漂移 (Spatial Persistence Degradation):由于缺乏有效的长程记忆和显式几何约束,当相机转回曾经看过的位置时,场景往往已经面目全非。
- 真实度缺失 (Synthetic-to-Real Gap):高度依赖合成数据训练模型,导致由于光影、纹理不匹配带来的视觉真实感断层。
- 控制精度不足:无法精确执行用户定义的 6-DoF 轨迹,这反映了模型底层对空间几何推理的缺失。
方法论:STAR 架构与 JDMD 蒸馏
1. 时空自回归框架 (STAR)
INSPATIO-WORLD 的核心是一个耦合了长短期记忆的自回归系统:
- 隐式时空缓存 (ST-Cache):它将参考帧作为“全局锚点”,并将历史生成的 Block 维护在一个滑动窗口内,确保了在无限漫游过程中,纹理和语义不会随时间推移而丢失。
- 显式空间约束 (Explicit Spatial Constraint):利用深度估计和重投影技术,将用户交互指令转化为几何引导特征。
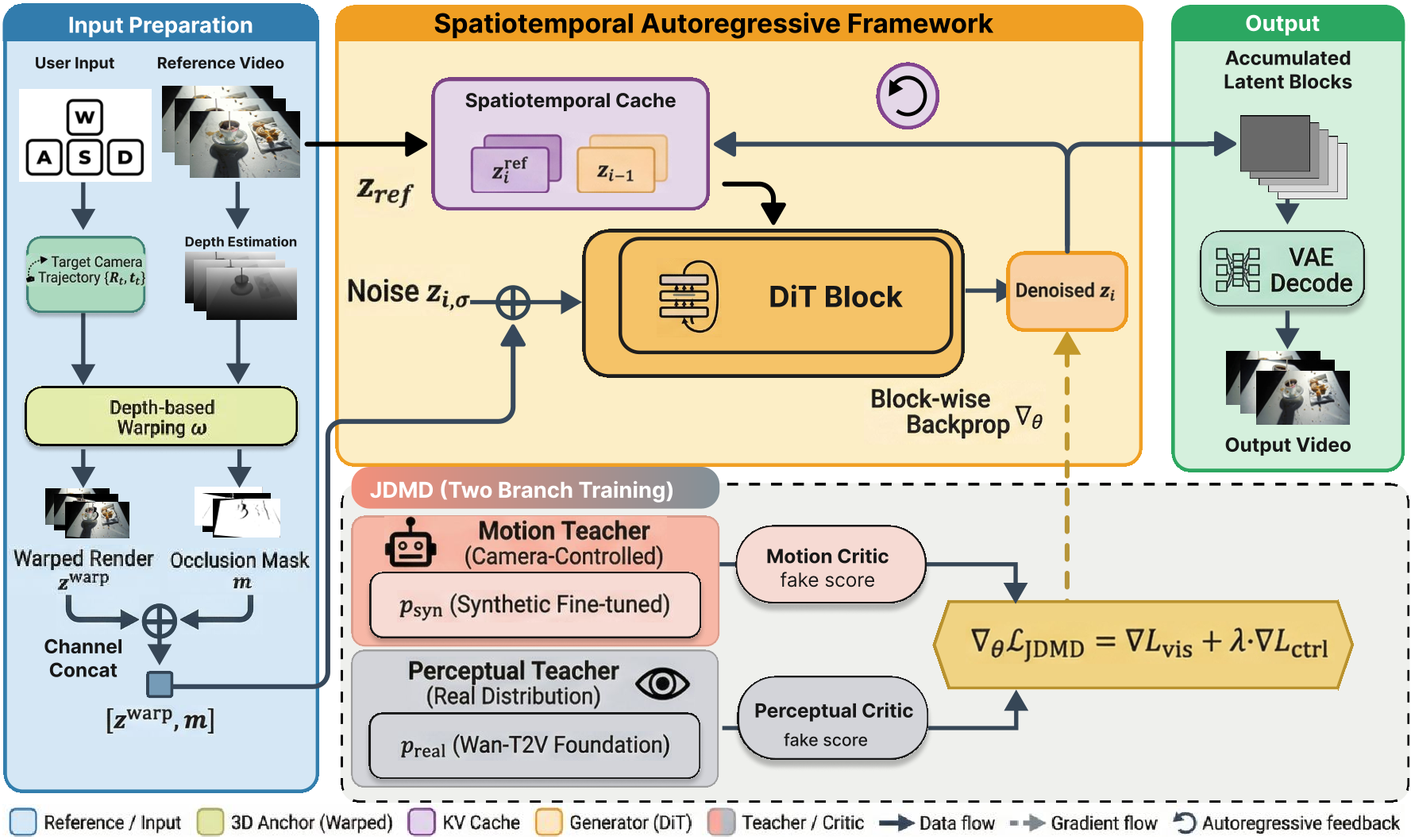 图 2:STAR 架构展示了如何通过时空缓存和深度图引导,将用户输入转换为高一致性的视频输出。
图 2:STAR 架构展示了如何通过时空缓存和深度图引导,将用户输入转换为高一致性的视频输出。
2. 联合分布匹配蒸馏 (JDMD)
为了解决合成数据训练带来的图像质量衰减,作者提出了 JDMD:
- 双教师模型:一个是在合成数据上微调的“运动教师”(负责教模型怎么动),另一个是真实世界的 T2V 基础模型“感知教师”(负责教模型怎么长得真)。
- 权重共享:通过在两个任务间共享权重,利用真实数据的梯度来校准生成分布,让模型在保持高精度相机控制的同时,拥有真实世界的细腻纹理。
实验战绩:遥遥领先的性能
在 WorldScore-Dynamic 榜单中,INSPATIO-WORLD 在动态得分和相机控制精度上均刷新了记录。
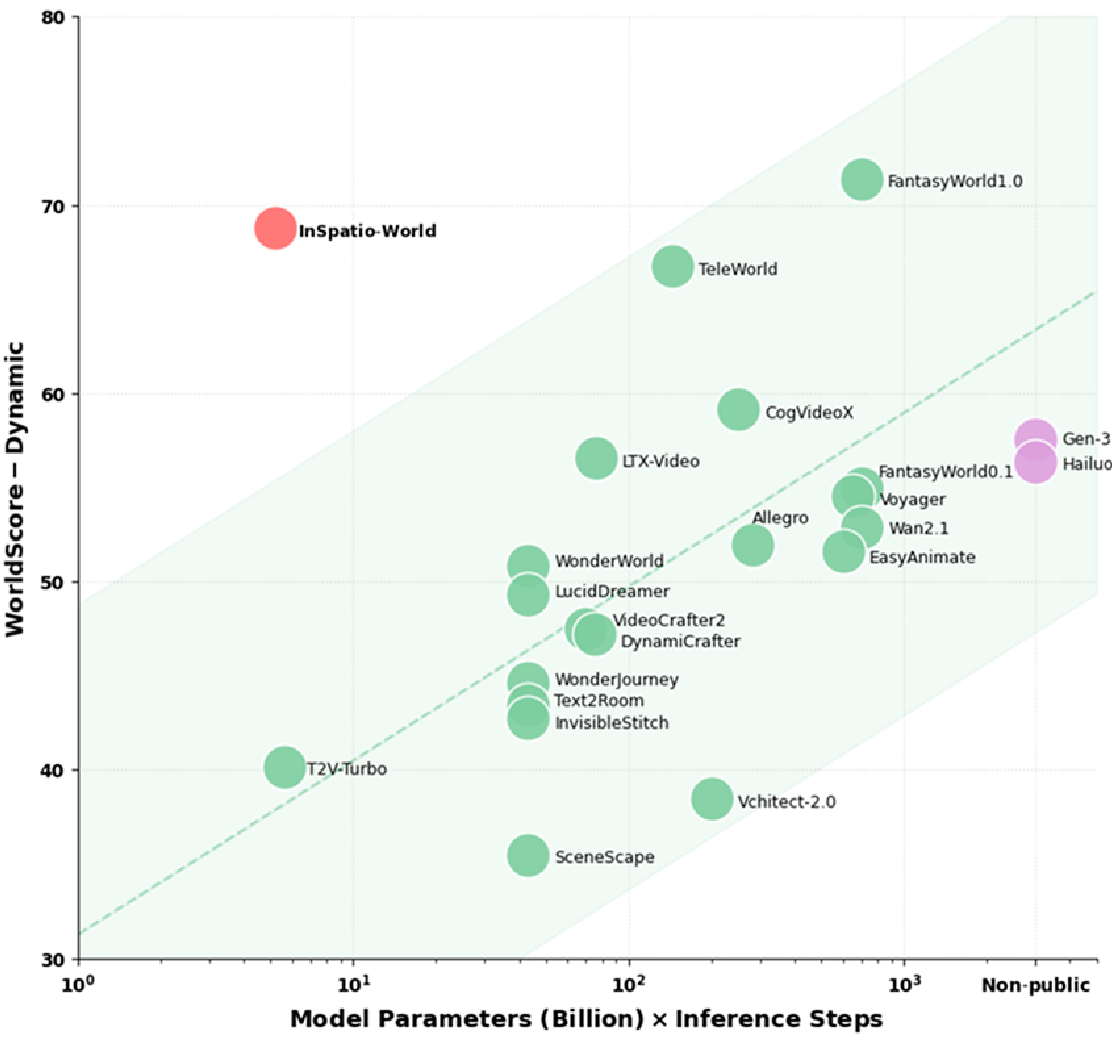 图 3:性能与显存/算力开销的权衡图。INSPATIO-WORLD 在极低开销下实现了极高的控制精度。
图 3:性能与显存/算力开销的权衡图。INSPATIO-WORLD 在极低开销下实现了极高的控制精度。
长程生成的鲁棒性对比: 在 RE10K 数据集的 150 帧以上长序列测试中,对比 HY-WorldPlay 和 Infinite-World,本模型在旋转误差 (Rot) 上实现了量级上的优化(由两位数降至 2.87),彻底解决了“镜头一动,房子就塌”的尴尬局面。
 图 4:在长程轨迹下,其他方法(如 LingBot)出现了明显的相机漂移或结构扭曲,而本方法保持了极高的 Persistance。
图 4:在长程轨迹下,其他方法(如 LingBot)出现了明显的相机漂移或结构扭曲,而本方法保持了极高的 Persistance。
深度洞察与总结
INSPATIO-WORLD 的成功在于它不只是在“生成视频”,而是在“渲染自回归的、受物理约束的世界”。
- 它的启示:未来的世界模型必须走向“神经渲染”与“生成扩散”的深度融合。显性的几何结构保证了“骨架”不散,而隐性的分布校准注入了“灵魂”。
- 局限性:目前在处理 360 度极端视角翻转及动态物体的超长程一致性上仍有挑战。
- 应用前景:这种实时 24 FPS 的能力将为自动驾驶模拟、机器人强化训练(Sim-to-Real)提供极低成本且高真实的虚幻环境。