本文系统研究了基于大语言模型(LLM)的迭代生成优化在构建自我改进智能体时的局限性,提出了由 Trace 框架驱动的“学习环”(Learning Loop)概念。通过在 MLAgentBench、Atari 游戏和 BBEH 上的实验,揭示了初始化、信用分配界限和经验批处理对优化结果的决定性影响。
TL;DR
构建一个能自我进化的 AI 智能体(Agent)是行业的高级目标,但现实很骨感:只有 9% 的生产系统真正实现了自动优化。本文作者指出,这并非技术工具不足,而是我们对**学习环(Learning Loop)**的设计缺乏系统性理解。通过对模块化、反馈时界和批处理大小的深度实验,本文为如何打造健壮的“自我进化者”提供了第一份实战指南。
背景定位:生成优化的“炼金术”时代
当前,利用 LLM 进行代码修复、Prompt 调优甚至算法设计(如 AlphaEvolve)已成为常态。然而,这些工作大多是“个案成功”,缺乏普适性规律。本文将这一过程类比为传统机器学习的底层架构:初始代码等于权重初始化,反馈证据等于损失函数采样。如果这些“隐藏”的超参数设置不对,LLM 优化器只会原地踏步,甚至完全崩盘。
核心洞察:构建学习环的三个关键决策
作者通过三个极具代表性的 Case Study,拆解了决定优化成败的“三要素”。
1. 初始人工制品 (Starting Artifact) —— 模块化的双刃剑
在 MLAgentBench 任务(自动构建 ML 训练管道)中,作者对比了“单函数”和“多函数模块化”两种初始化方式。
- 发现:模块化并不总是好的。在某些任务中,模块化让 LLM 能精准定位错误;但在另一些任务中,多余的接口定义反而成了优化空间的阻碍。
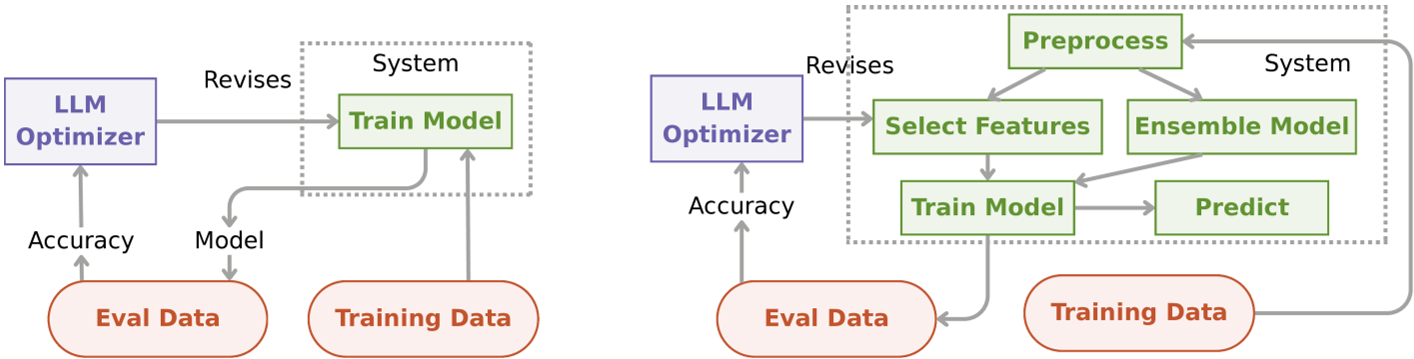 上图展示了单函数 vs 模块化初始化的结构差异。
上图展示了单函数 vs 模块化初始化的结构差异。
2. 信用界限 (Credit Horizon) —— 即时反馈 vs 长线视野
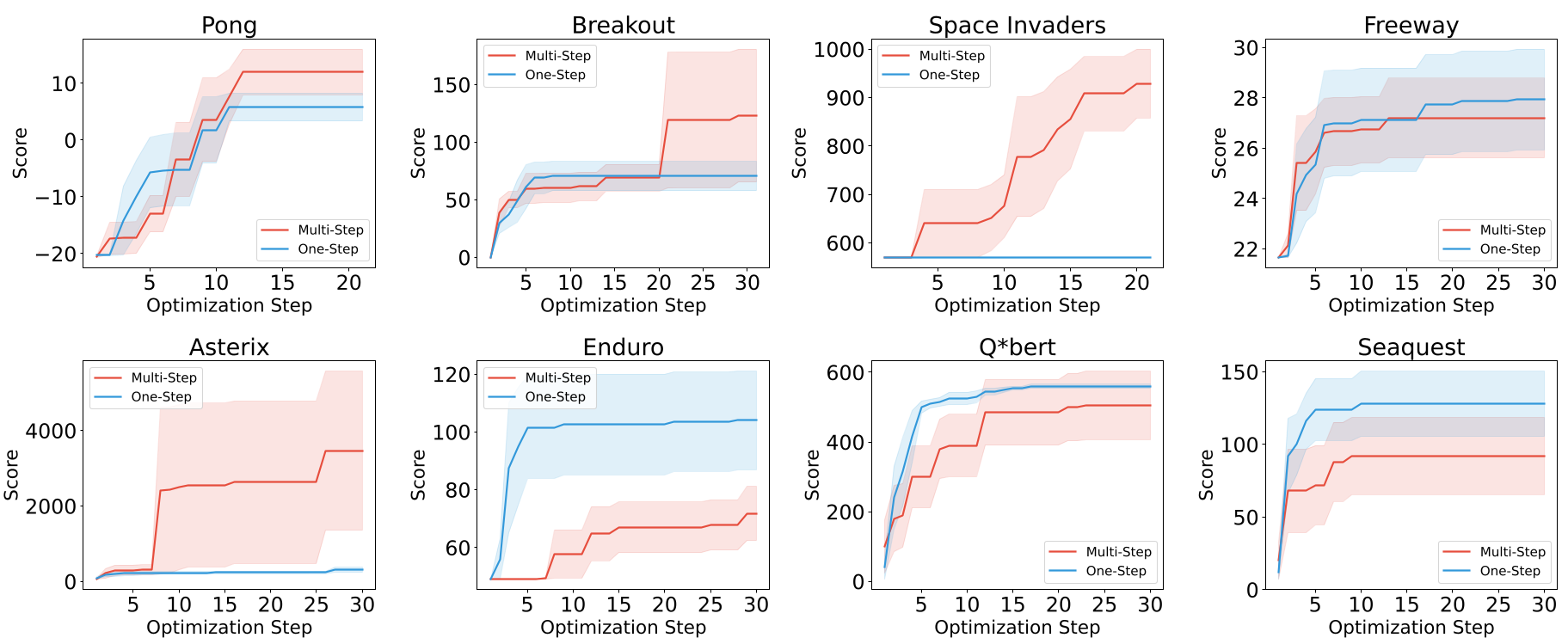
在 Atari 游戏控制中,优化器面临选择:是根据每一步的得分立即改代码(One-step),还是等打完一局再总结经验(Multi-step)?
- 物理直觉:这对应于强化学习中的有效时界问题。实验显示,在《Pong》这类因果关系直接的游戏中,单步优化极快;而在《Space Invaders》这类需要长线防守的任务中,过短的 Horizon 会导致智能体“鼠目寸光”。
3. 经验批处理 (Experience Batching) —— 别让 LLM “元过拟合”
在 BBEH(逻辑推理瓶颈)测试中,作者研究了每次给 LLM 优化器看多少个失败案例最合适。
- 深刻警示:Batch Size 不是越大越好。大的 Batch 虽然提供了稳定信号,但常导致 LLM 陷入“元过拟合”(Meta-overfitting)——即代码在训练集上得分完美,但换一套题就失效。
实验与战绩:LLM vs 传统 RL
本文最令人兴奋的发现之一是:基于代码生成的 LLM 优化器在效率上碾压了传统深度强化学习(Deep RL)。 在多个 Atari 游戏中,LLM 优化器(如 Claude-3.5-Sonnet)仅需 8 分钟生成的 Python 策略逻辑,就能在多项性能指标上比肩训练了数小时的 PPO 算法。这证明了 LLM 拥有的强大 Inductive Bias(归纳偏置) 在经过正确引导后,具有惊人的搜索效率。
深度洞察:我们离“通用优化器”还有多远?
作者在结论中提出了一个宏伟的愿景:
- 权重的初始化 -> 代码的初始化:我们需要一套标准化的 Agent 起始模版。
- Adam 优化器 -> 通用上下文结构:我们需要发现一种能自动调节 Batch Size 和 Horizon 的元策略。
局限性分析: 目前该方法高度依赖高端 LLM(如 Claude 3.5)的推理能力。在较低模型上,优化过程会变得极其不稳定,甚至无法理解逻辑反馈。
总结
本文不是在推销某种具体的库,而是在建立**生成工程学(Generative Engineering)**的科学基石。对于正在构建自提升智能体的工程师而言,本文最大的启示是:不要迷信 LLM 的万能,要像调优神经网络一样,精细地设计你的学习证据流。