本文推出了 Kimodo,一个由 NVIDIA 开发的大规模可控人体运动生成模型。通过在 700 小时高质量光学运动捕捉数据上训练,Kimodo 实现了基于文本、2D 路径、2D 航点及全框架全身/末端执行器约束的 SOTA 级别精准运动合成。
TL;DR
NVIDIA 近期发布的 Kimodo 展示了人体运动生成领域的一次“暴力美学”与“精巧架构”的结合。它基于 700 小时 的高质量光学运动捕捉(Mocap)数据进行训练,不仅能听懂复杂的文本指令,还能像专业动画软件一样,通过 2D 路径、关键帧等硬性约束进行精准控制。其核心贡献在于提出了一个两阶段去噪架构,彻底解决了长距离位移与局部动作不匹配的顽疾。

1. 痛点:为什么之前的模型“画不好”长距离运动?
在人体运动建模中,一直存在一个矛盾:
- 全局不准:如果你给模型一个 2D 路径,它往往会出现“漂移”或“滑步(Foot Skating)”现象。
- 局部僵硬:为了跟随路径,模型往往会牺牲动作的自然度。
现有模型(如 MDM, MotionDiffuse)大多在小规模数据集(如 HumanML3D)上训练,这导致它们在处理“变走边挥手”这种复合动作或长距离轨迹时,泛化能力极差。
2. Methodology:两阶段解耦去噪
Kimodo 的核心直觉在于:将“根节点轨迹”与“身体姿态”解耦。
2.1 架构解析
Kimodo 并没有使用一个 Transformer 强行搞定所有特征,而是设计了一个互联的两阶段流程:
- Stage 1 - Root Denoiser:利用全局信息预测根节点的平滑轨迹(Smoothed Root)。
- Stage 2 - Body Denoiser:在第一阶段生成的根节点基础上,将身体动作转化为局部坐标系进行预测。
通过这种设计,模型可以先确立“人在哪走”,再细化“人怎么动”,极大地减少了运动伪影。
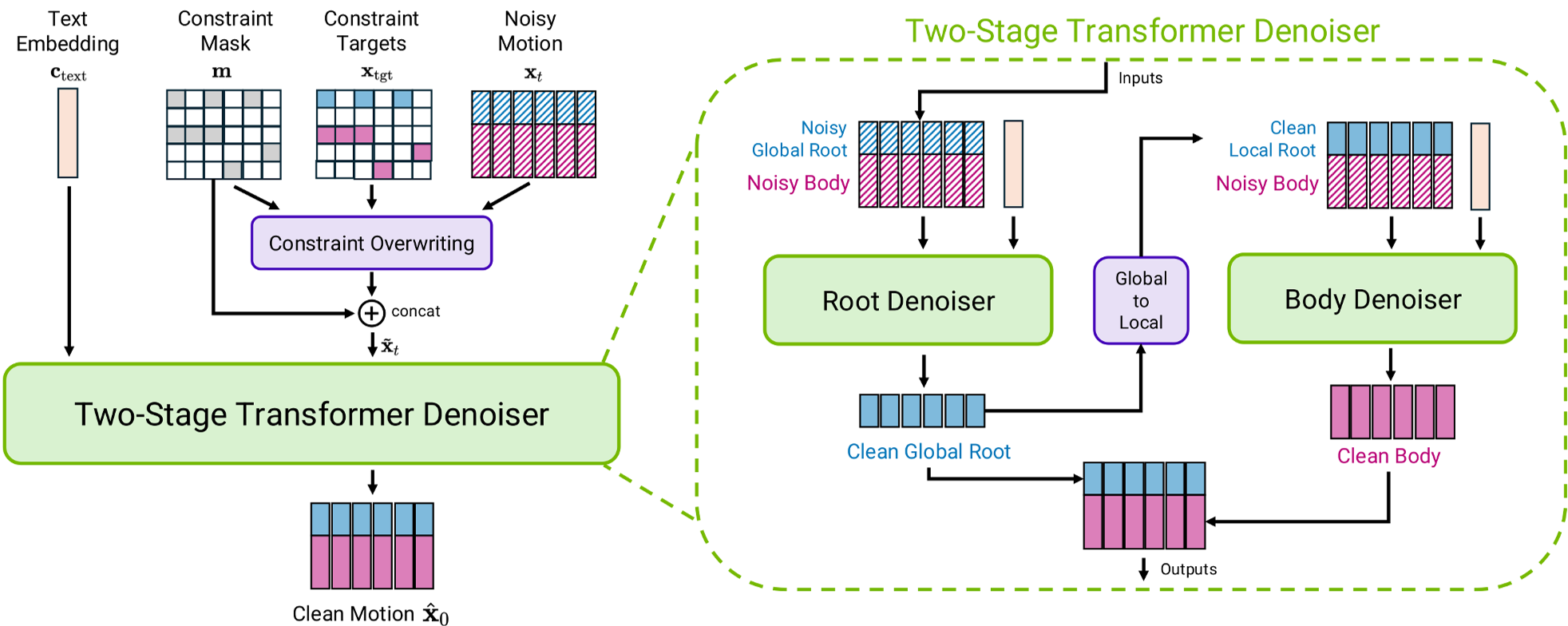
2.2 特色:平滑根节点表示 (Smoothed Root)
不同于传统的盆骨投影,Kimodo 使用了高度平滑的根节点。这符合人类交互的直觉——我们在动画软件中画路径时,画的是一条顺滑曲线,而不是随胯部摆动的带状线。
3. 实验结果:Scaling 的威力
论文深入探讨了 数据量、模型参数量、Batch Size 对性能的影响。
- 数据缩放:随着 Mocap 数据的增加,约束遵循误差(Constraint Error)呈线性下降。10% 的数据量完全无法达到高质量的控制精度。
- 模型缩放:2.82 亿参数的大模型在 R-precision(文本匹配度)上远超小模型。
- 控制精度:在全框架约束下,关节位置误差仅为 3.21 厘米,这已经达到了可以直接用于影视和游戏管线的工业级水平。

4. 深度洞察:从“人”到“机器人”
Kimodo 不仅仅是为了做动画。NVIDIA 成功将该模型迁移到了 Unitree G1 机器人上。这意味着,我们现在可以通过一句话(如“机器人摔倒后爬起来”)直接生成高质量的机器人运动训练数据(Demonstration Data),这对于解决具身智能(Physical AI)中的数据孤岛问题具有巨大潜力。
5. 局限性与未来展望
尽管 Kimodo 表现惊人,但它仍属于“离线绘制”模型。生成一段 10 秒的运动需要 2-5 秒的计算时间,无法满足机器人实时避障或角色实时交互的需求。作者提到,未来将探索将扩散模型转化为自回归潜空间模型,以兼顾高质量与实时性。
总结
Kimodo 证明了在高质量标注数据足够充沛的条件下,人体运动生成可以摆脱“玩具模型”的范畴,真正走向高精度的工业应用和机器人模拟。