本文提出了 Kinema4D,这是一种创新的动作条件驱动 4D 生成式机器人模拟器。该方法通过将机器人控制解析为精确的 4D 运动学轨迹,并结合 Diffusion Transformer 生成环境的 4D 反应(RGB 和 Pointmap),实现了在时空一致性上的 SOTA 性能。
TL;DR
传统的具身智能模拟器要么缺乏视觉真实感(物理引擎),要么缺乏物理精确度(2D 视频生成)。Kinema4D 通过将机器人动作转化为精确的 4D Pointmap(点云图)控制信号,并利用 4D Diffusion Transformer 生成环境反应,首次实现了既具有视觉冲击力又符合几何逻辑的 4D 全世界模拟。
1. 痛点:为什么“蒙”出来的视频不能当模拟器?
当前的 Embodied AI 训练极度依赖高质量数据。虽然像 Sora 这样的视频生成模型能画出精美的动态,但在机器人任务中,它们常犯致命错误:
- 幻觉与扭曲:机器人手臂在移动中会莫名变长或穿透桌子。
- 深度缺失:2D 像素无法表达“夹爪与物体之间微妙的几毫米距离”,导致模拟器无法用于精确评估抓取策略。
- 动作表征模糊:使用文本("Pick up the cup")生成的动作太粗糙,而使用 Latent Embedding 这种黑盒数据则让模型在“猜”动作,缺乏物理确定性。
2. 核心直觉:物理确定性归 4D,环境灵活性归生成
Kinema4D 的核心贡献在于其解耦哲学 (Disentanglement):
- 确定性的机器人控制 (Kinematic Control):机器人怎么动是不需要“猜”的。通过 URDF 模型和正/逆运动学,作者将动作指令直接转化为 4D 轨迹,投影为像素对齐的 Pointmap。这保证了机器人的几何结构和运动学始终 100% 正确。
- 生成式的环境反应 (4D Modeling):环境对机器人动作的反馈(如杯子被推倒、布料变形)具有随机性和复杂性,这部分交给强大的 Diffusion 模型处理。
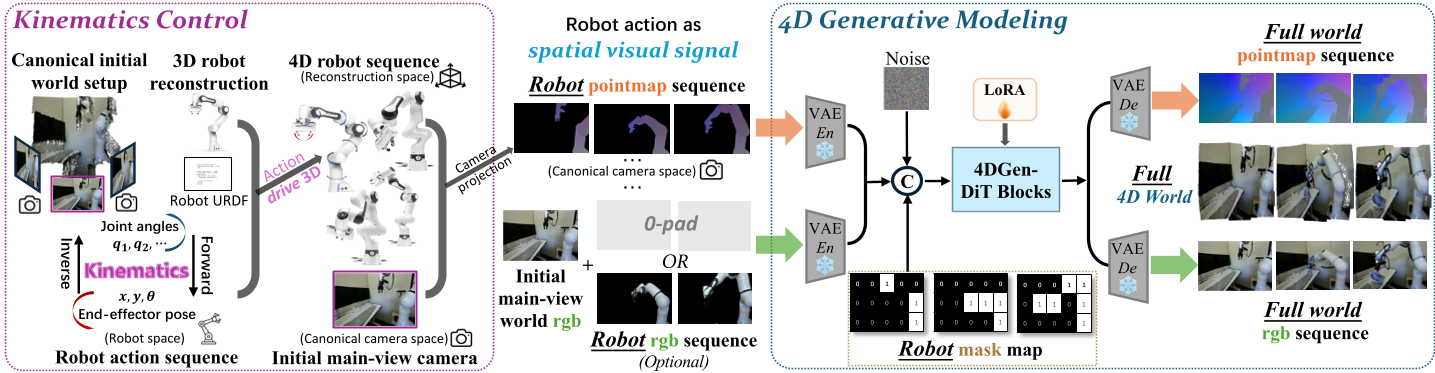 图 1:Kinema4D 整体架构。左侧为运动学控制分支,右侧为联合 RGB-Pointmap 生成的 4D 扩散模型。
图 1:Kinema4D 整体架构。左侧为运动学控制分支,右侧为联合 RGB-Pointmap 生成的 4D 扩散模型。
3. 技术详解:如何炼就 4D 火眼金睛?
3.1 从像素到 4D 空间
为了训练这个模型,作者构建了 Robo4D-200k。这是一个史无前例的规模化 4D 数据集。他们利用 ST-V2 等 3D 追踪技术将 2D 机器人视频“升维”到 4D 空间。
3.2 联合表示层 (Multi-modal Latent Construction)
模型不仅仅输出 RGB 视频,还同步输出对应的 Pointmap 序列。这意味着生成的每一帧视频,模型都必须构建出其背后的 3D 几何结构。这种 Spatiotemporal Reasoning(时空推理) 强制模型遵守几何一致性。
4. 实验报告:它究竟有多强?
在对比实验中,Kinema4D 展示了令人惊叹的细节表现:
- 高精度抓取:即便在 2D 视角下看起来夹爪已经碰到了物体,Kinema4D 如果检测到 3D 空间中存在微小间隙,依然会准确生成“Near-miss(擦肩而过)”的失败场景。
- 零样本迁移 (Zero-shot):即使在从未见过的实验室环境下,也能根据实时生成的机器人 Pointmap 成功仿真出物理可信的结果。
 图 2:与 Ctrl-World 的定性对比。注意 Kinema4D 在处理复杂交互时表现出的极高几何保真度。
图 2:与 Ctrl-World 的定性对比。注意 Kinema4D 在处理复杂交互时表现出的极高几何保真度。
下表展示了 Kinema4D 在几何误差(CD-L1)和图像质量(PSNR)上的全面领先:
| Method | PSNR↑ | FID↓ | CD-L1 (几何误差)↓ | | :--- | :--- | :--- | :--- | | UniSim | 19.32 | 32.3 | - | | Ctrl-World | 21.03 | 24.9 | - | | TesserAct (4D) | 19.35 | 29.5 | 0.0836 | | Ours (Kinema4D) | 22.50 | 25.2 | 0.0479 |
5. 局限与未来:物理规律的“最终边界”
尽管 Kinema4D 在几何表现上已经非常卓越,但作者坦诚指出:目前的模型仍然是统计合成而非解析求解。这意味着在处理极端的摩擦力或碰撞能量守恒时,偶尔仍会出现违背物理定律的“小瑕疵”。未来的研究方向将是如何将物理偏置 (Inductive Bias) 直接嵌入 Diffusion 的 Loss 函数中。
6. 总结
Kinema4D 为具身智能的世界模型提供了一个清晰的范式:用运动学约束生成,用生成模拟世界。 它不仅是一个视觉模拟器,更是一个带有深度信息的 4D 物理实验室,为机器人自动标注数据、闭环验证策略提供了无限可能。