本文提出了将大语言模型(LLM)本身作为 Token 压缩器与解压缩器的创新框架。通过 LoRA 微调,LLM 学习将长文本转化为一种离散、变长的内部语言(Z-tokens),在 Wikipedia 等数据集上实现高达 18 倍的压缩比并保持极高的重构保真度。
TL;DR
传统的 Token 压缩要么简单粗暴地删词(Pruning),要么把信息压进一团没人看得懂的连续向量(Embedding)。本文提出了一个惊艳的观点:大语言模型(LLM)天生就是最好的压缩引擎。 作者通过微调,让 LLM 学习一套属于自己的“内部方言”——Z-tokens。模型可以把长篇大论压缩成极短的 Z-tokens 码流,并能精准重构或直接基于这些码流进行思考,实现高达 18 倍的压缩效率。
背景定位
在 LLM 迈向超长上下文(Long-context)的道路上,Attention 的计算成本是一座大山。目前的主流做法(如 ICAE 或 AutoCompressor)更像是在模型外面加个“外挂”压缩包。而本文的工作更像是一种“进化”:它挖掘了模型内部的语义抽象能力,在学术坐标系中属于**可学习的离散语义压缩(Learned Discrete Semantic Compression)**领域。
痛点深挖:为什么我们需要“变长”与“离散”?
- 语义密度不均:一篇文章中,某些术语(如“双刃剑”)本身就具有极高的信息密度。固定压缩比会造成:简单的句子浪费空间,复杂的句子信息丢失。
- 黑盒困境:连续的向量表示缺乏解释性,一旦推理出错,人类无法溯源。
- 重构缺失:很多压缩方法只能做摘要,没法原样还原原文,这在需要精确引用的任务(如法律、科研 QA)中是致命的。
核心方法论:Z-tokens 的诞生
作者利用预训练 LLM 已经掌握的丰富语义知识,设计了一个翻译式的架构:
- Compressor (压缩器):利用自回归方式生成变长的 Z-tokens。通过 Gumbel-Softmax 实现梯度的端到端传递,同时保证输出的离散性。
- Decompressor (解压器):将 Z-tokens 映射回原始 Vocabulary。
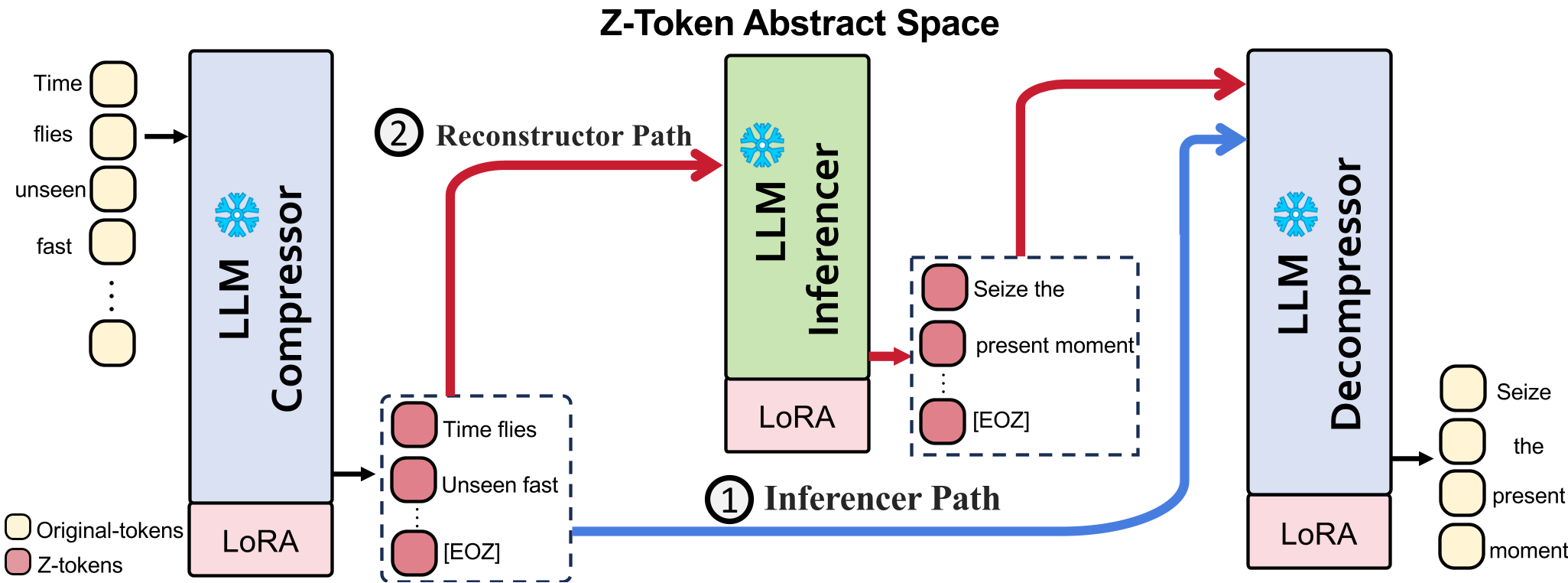
两种强大的使用范式:
- 作为辅助推断(Inferencer):压缩后直接输出任务答案,类似高效的 Prompt 压缩。
- 作为符号思考者(Reconstructor):这是本文最迷人的部分。模型可以直接在 Z-token 空间进行“思考”(Reasoning),思考完后再由解压器转译回人类语言。
实验战绩
该方法在 Wikipedia, CNN/DailyMail 及多个 QA 数据集(HotpotQA, QASPER 等)上进行了验证:
- 无损压缩:在 Wikipedia 重构任务中,BLEU-4 得分高达 99.31,几乎实现了无损重构。
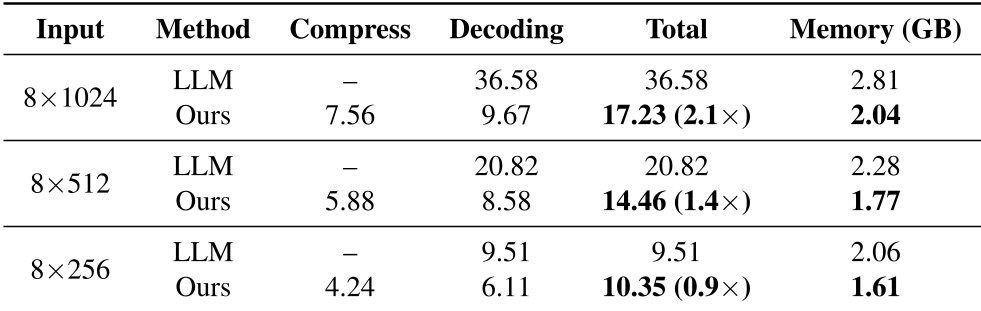
- 效率飞跃:在 8x1024 的输入规模下,推理速度提升了 2.1 倍到 4.6 倍,显存显著下降。
- SOTA 对比:在相同压缩预算下,表现全面优于 ICAE 和 Gist Token。
深度洞察:模型“说话”有逻辑吗?
作者对 Z-tokens 进行了多义性(Polysemy)分析。有趣的是,同一个 Z-token 在不同上下文中可能代表不同的细微语义,这证明了它不是简单的 1-to-1 映射,而是一种上下文相关的符号抽象。通过计算语义一致性(Semantic Consistency),作者证明这种多义性是受控且规律的,平均一致性达 0.75。
总结与启示
这项工作的核心贡献在于证明了 “LLM speaks its own language” 的可行性。
- 价值:对于超长文档处理,我们不再需要处理每一个原始 Token,而是处理模型提炼后的“语义结晶”。
- 局限性:目前在处理跨窗口的全局长程依赖上,仍需要更精细的协调机制。
- 展望:如果未来的 LLM 能够原生支持这种“自压缩”机制,或许我们能以极小的代价训练出处理百万级上下文的模型。