本文提出了 Large Reward Models (LRMs) 框架,通过将视觉语言模型(VLM)适配为密集、帧级的在线奖励生成器,解决了机器人强化学习中的奖励设计难题。该方法在 Qwen3-VL 基础上开发,涵盖了三种奖励模态,在 ManiSkill3 基准测试中实现了超越现有 SOTA(如 RoboReward)的性能。
TL;DR
强化学习(RL)是解决复杂机器人操作的利器,但其核心痛点在于“奖励函数(Reward Function)”难写、难调。本文提出的 Large Reward Models (LRMs) 框架,通过对视觉语言模型(VLM)进行专业化微调,使其能够像人类教练一样,实时对比机器人动作的细微差异,并给出 0 到 1 之间的精确进度反馈。该框架在无需任何人工干预的情况下,显著提升了机器人策略的成功率和样本效率。
核心动机:当模仿学习(IL)遇到瓶颈
目前的通用机器人策略多基于 Imitation Learning (IL),虽然通过大规模预训练表现不错,但在高精度或长程任务中常遭遇瓶颈(Performance Plateaus)。Reinforcement Learning (RL) 虽然能持续进化,但它极度依赖一个“好”的奖励函数。
以往的方法要么靠人工硬编码(Brittle and manual),要么靠 VLM 对整段视频进行事后打分(Episode-level)。后者的缺点是空间分辨率太低:就像考试结束后才发成绩单,学生在答题过程中无法及时纠错。LRM 的出现,就是为了提供一种**帧级(Frame-level)**的、具备语义理解能力的“实时监考”信号。
核心方法:三面相奖励矩阵
作者认为,单一的奖励信号不足以捕捉复杂的物理交互。因此,LRMs 提供了三种维度的反馈:
- Temporal Contrastive Reward (rcont):对比当前帧与上一帧,判断“是变好了还是变差了”。这种相对评估(Relative Ranking)有效解决了绝对评分时的校准偏置问题。
- Absolute Progress Reward (rprog):对任务完成度进行 0.0 到 1.0 的回归预测。它为复杂的步骤序列提供了“路标”。
- Task Completion Reward (rcomp):二元分类器,判定语义目标是否达成。
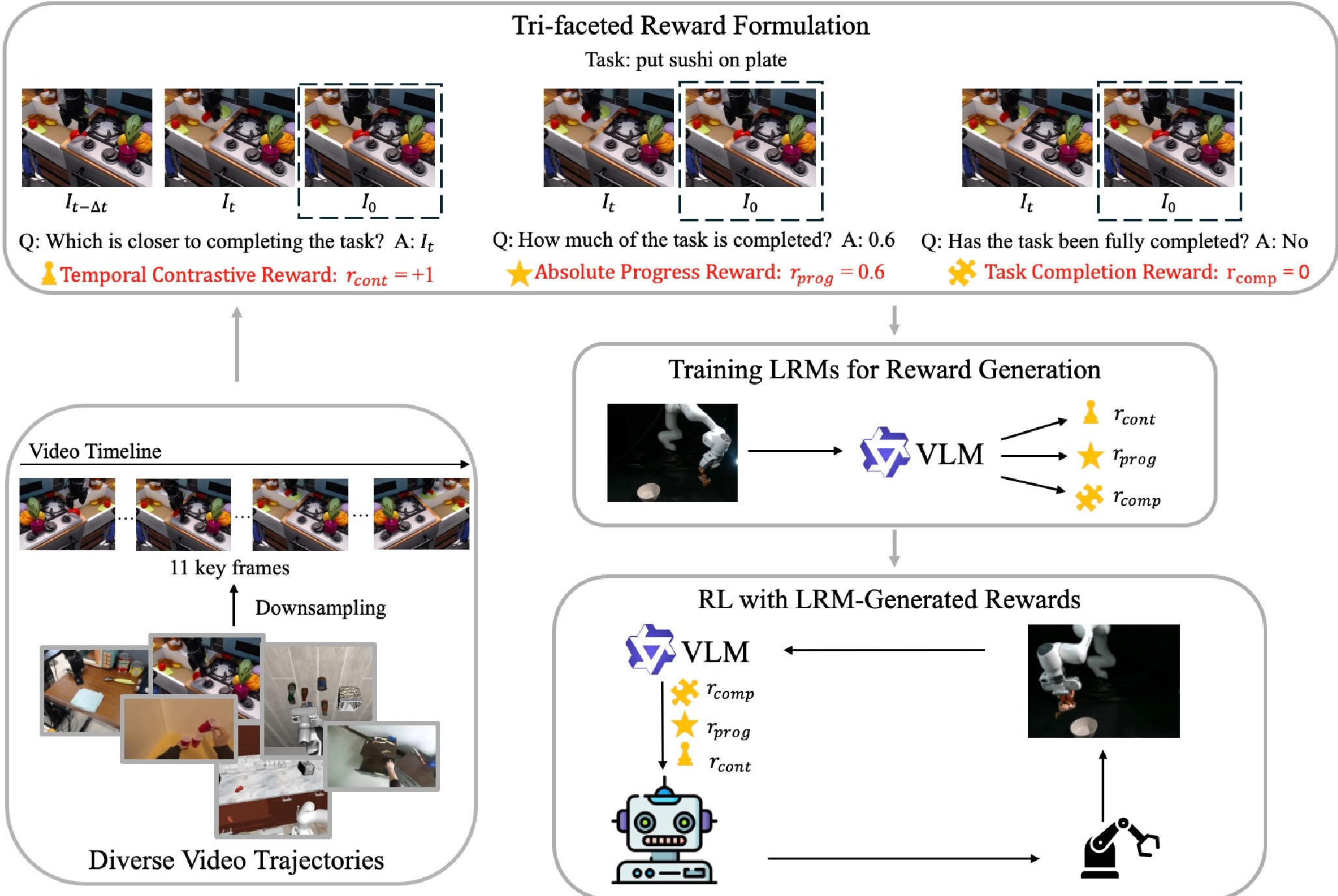
为何有效?多模态数据的物理常识补全
为了让 LRMs 具备 Zero-shot 的泛化能力,作者将其在 24 个数据源上进行微调,其中包括了 Open X-Embodiment(机器人数据)、HOI4D(人类操作数据)以及各种模拟环境。这种“博采众长”的做法,让模型学会了从人类的灵巧操作中提取“成功”的标准,并迁移到机器人的视觉观测中。
实验战绩:超越 SOTA 的零样本表现
在 ManiSkill3 这一极具挑战性的长程操作基准测试中,LRM 展现了惊人的效率:
- 超越最强基线:在 320 个并行环境下,基于 LRM 的 RL 优化策略在成功率上全面超越了 RoboReward 和 Robometer。
- 效率极高:仅需 30 次 RL 迭代,策略性能就实现了显著飞跃。
- 现实世界闭环:在真实的“抓取玩具长颈鹿放入碗中”的任务中,LRM 充当了全自动裁决官,通过识别成功视频并过滤失败尝试,将机器人成功率从 38.3% 提升至 51.7%。

深度洞察:奖励信号的“语义一致性”
文章中一个深刻的发现是:随着 RL 的进行,LRM 给出的奖励信号质量也在提升(ROC-AUC 从 0.66 升至 0.79)。这意味着,当机器人学会了更正确的动作,VLM 也更容易看懂机器人在干什么。这种策略行为与奖励感知之间的“同步优化(Synchronization)”,可能是迈向自主具身智能的关键一步。
总结与期望
LRMs 的成功标志着 VLM 已具备从“静态观察者”向“动态导师”转化的能力。
- 局限性:目前的推理延迟仍需要通过间隔采样(Interval-Hold)来缓解。
- 未来方向:如何将这一机制与世界模型(World Models)结合,实现在虚拟空间中的“想象式自进化”,将是下一个研究高地。
关键图表回顾:
 如图所示,RL 进化后的模型精确纠正了 IL 阶段将长颈鹿放在碗外的执行误差。
如图所示,RL 进化后的模型精确纠正了 IL 阶段将长颈鹿放在碗外的执行误差。