本文提出了层次化因果 Dropout (HCD) 框架,旨在解决深度学习模型的分布外 (OOD) 泛化问题。核心方法通过通道级稀疏化和基于矩阵的互信息 (MMI) 约束,在医疗影像和野生动物监测等挑战性基准上实现了 SOTA 性能。
TL;DR
针对深度学习模型在面对未见过的数据分布(OOD)时容易依赖背景、光照等“捷径”特征的问题,北航研究团队提出了一种名为 Hierarchical Causal Dropout (HCD) 的新框架。该框架通过通道级门控(Gating)物理阻断非因果信息流,并利用**矩阵互信息(MMI)**从理论上解耦域信息。在医疗影像 Camelyon17 和野生动物监测 iWildCam 两个大规模基准上,HCD 均显著超越了传统的 ERM 和现有 SOTA 方法。
背景定位:从像素空间到表征空间的因果跃迁
目前的分布外泛化(Domain Generalization, DG)研究正处于从“数据增强”向“表征干预”转型的阶段。传统方法如 MixStyle 试图通过改变统计量来模拟环境变化,但如果特征本身是纠缠的,模型依然会通过复杂的路径学习到伪相关性。HCD 的核心 Insight 是:域偏置(如设备签名、环境噪声)通常编码在特征通道中,而非局限于特定像素。 因此,直接在隐层的通道维度进行“手术式”干预,比在像素层面打补丁更有效。
核心机制:三位一体的解耦策略
1. 通道级稀疏化 (Channel-Level Sparsification)
HCD 引入了一个自适应特征门控模块(Advanced Feature Gater)。它不仅是简单的 Dropout,而是一个信息瓶颈。
- 原理:通过降低通道容量,强迫模型在有限的资源下进行“选择竞争”。
- 直觉:由于偏置信号通常不如核心语义信号稳健,在稀疏化压力下,模型会被迫优先保留那些跨域一致的因果通道。
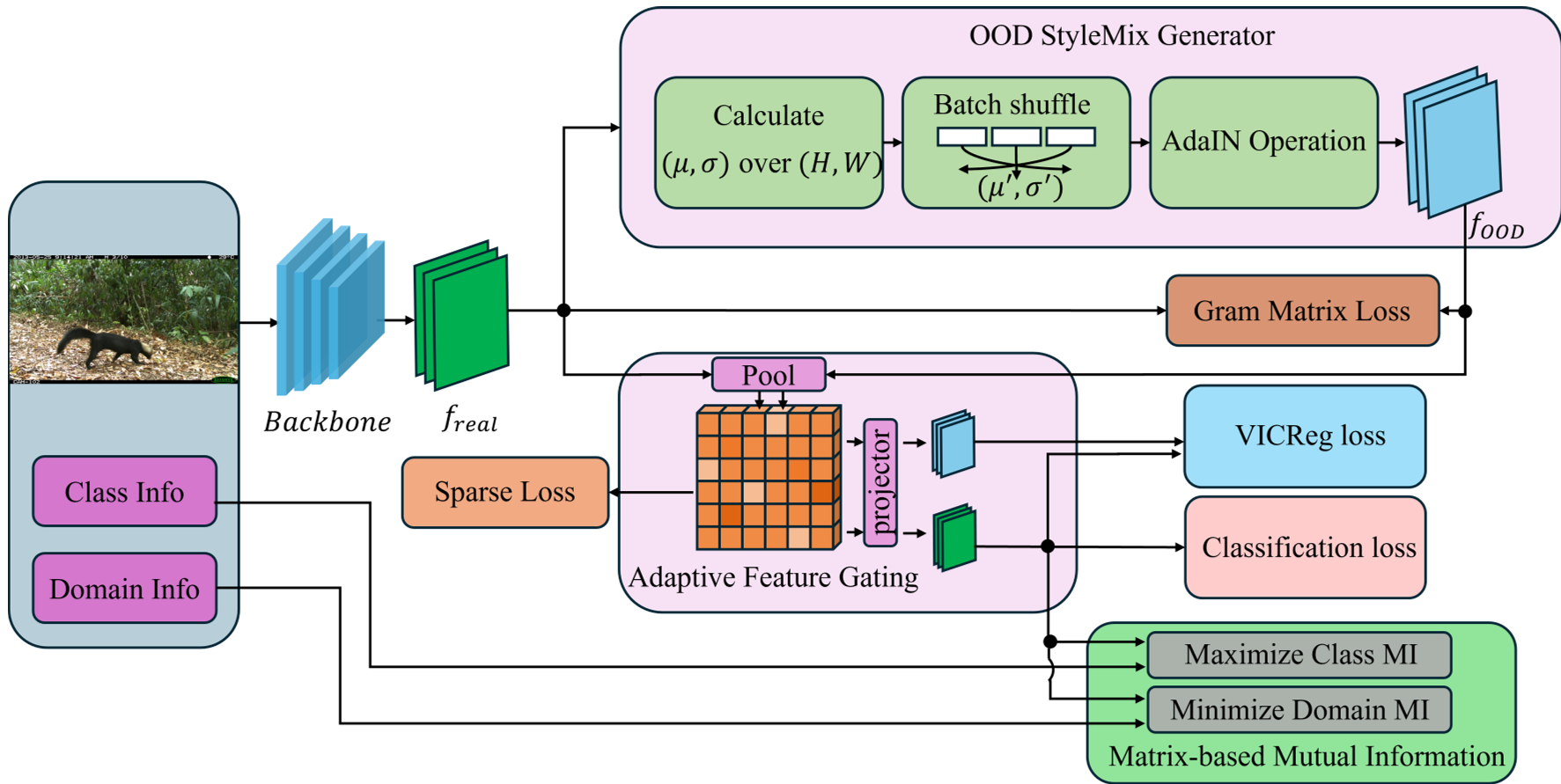 图 1: HCD 框架总览。展示了特征提取、通道门控、StyleMix 扰动以及多重损失优化流程。
图 1: HCD 框架总览。展示了特征提取、通道门控、StyleMix 扰动以及多重损失优化流程。
2. 信息论解耦 (Information-Theoretic Decoupling)
为了量化并消除偏置,作者采用了基于矩阵的 Rényi 熵来计算互信息(MMI)。
- LM-ID (Domain MI):最小化特征与域标签的互信息,相当于对特征进行“漂白”,滤掉环境签名。
- LM-IC (Class MI):最大化特征与类别标签的互信息,确保在“漂白”过程中不丢失关键诊断信息。
3. StyleMix + VICReg:锚定因果信号
单纯的稀疏化可能导致模型丢失细微的有用信号。HCD 引入了 VICReg (Variance-Invariance-Covariance Regularization):
- StyleMix:在隐层交换特征统计量,生成虚构的 OOD 域。
- VICReg:强制模型即使在风格剧烈变化时,表征也要保持一致(Invariance),同时防止特征坍缩(Variance)并减少通道冗余(Covariance)。
实验战绩:硬核泛化能力的体现
1. SOTA 性能对比
在数字病理学数据集 Camelyon17 上,面对来自不同医疗中心的设备差,HCD 将准确率推向了 86.62%。与基准方法相比,其提升不仅体现在均值上,还体现在更小的标准差(±2.65%),证明了其极高的训练稳定性。
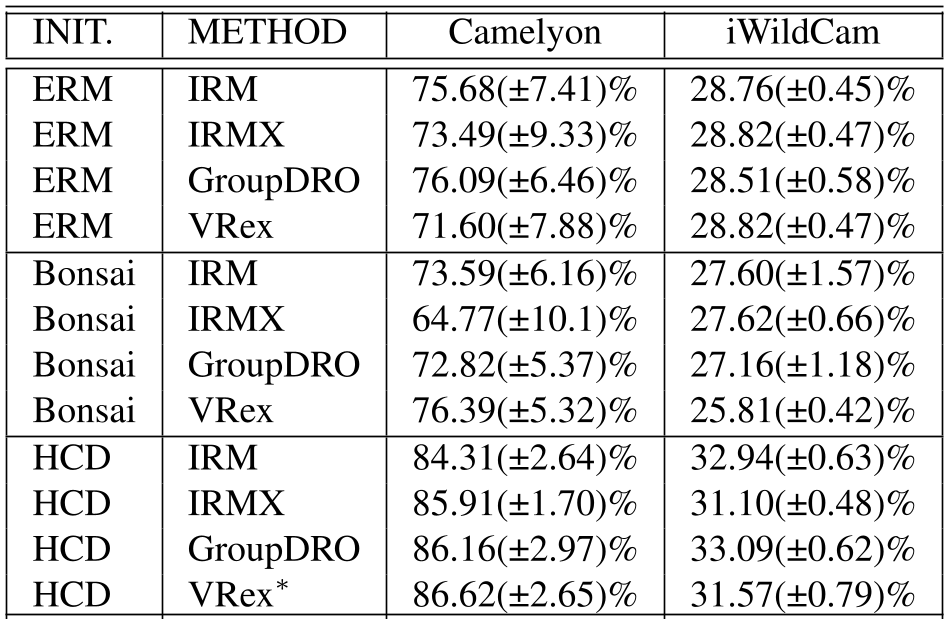 表 1: 在 WILDS 基准上的对比。HCD 无论在 DenseNet 还是 ResNet 骨干网络下均表现优异。
表 1: 在 WILDS 基准上的对比。HCD 无论在 DenseNet 还是 ResNet 骨干网络下均表现优异。
2. Grad-CAM 可视化:看清模型在看什么
通过 Grad-CAM 可视化(图 2),我们可以清晰地看到:
- ERM/Bonsai:注意力经常涣散到背景、植被或红外相机的边缘噪声上。
- HCD:精准地锁定在动物的轮廓或病灶的核心区域,验证了通道门控确实物理屏蔽了背景相关的噪声通道。

3. Loss Landscape:更平坦的极小点
HCD 生成的损失平面(Loss Landscape)比传统方法更宽、更平滑(图 3)。根据优化理论,越平坦的局部极小值通常意味着越强的泛化性。这意味着当测试数据分布发生漂移时,模型的性能不会剧烈下跌。

深度洞察与总结
HCD 的成功在于它不仅提出了一个新的 Loss,更是在架构和信息流层面重新思考了“如何让模型变诚实”。
- 价值总结:它证明了在隐层通道上进行干预,比单纯在数据层面做扩增能更本质地通过信息瓶颈滤掉伪相关性。
- 局限性:矩阵互信息的计算复杂度与 Batch Size 成平方关系($O(N^2)$),这在超大规模数据集上训练时可能会面临计算压力。
- 未来启示:这一思路可以进一步扩展到多模态任务中,通过通道门控来解耦视觉描述与文本偏置之间的不一致性。
关键词:OOD Generalization, Causal Learning, Channel Sparsification, Matrix Mutual Information, VICReg