[Alibaba DAMO] Lingshu-Cell: Bridging the Gap Toward Virtual Cells with Discrete Diffusion World Models
Lingshu-Cell is a generative cellular world model based on a Masked Discrete Diffusion Model (MDDM) designed to simulate single-cell transcriptomic states and their responses to perturbations. It scales to approximately 18,000 genes without prior filtering and achieves leading performance on the Virtual Cell Challenge (VCC) H1 genetic perturbation benchmark and cytokine response prediction in PBMCs.
TL;DR
Lingshu-Cell is a novel masked discrete diffusion model (MDDM) that acts as a "cellular world model." Unlike previous foundational models that only learn representations, Lingshu-Cell explicitly models the distribution of cellular states. By treating gene expression as discrete, orderless tokens, it can simulate how a cell responds to genetic or cytokine perturbations with unprecedented accuracy, achieving first place in the Virtual Cell Challenge H1 benchmark.
Background Location: This work represents a shift from "Static Representation Learning" (scGPT era) to "Generative World Modeling," positioning itself as a robust engine for in silico biological experimentation.
Problem & Motivation: Why Current Models Fail at "Virtual Cells"
The holy grail of computational biology is the virtual cell: a system where you can "perturb" a gene on a computer and see the transcriptomic consequences before ever touching a wet-lab pipette.
However, two major technical hurdles remained:
- The Representation Gap: Most models use continuous noise (like traditional Diffusion) or sequential processing (like Transformers for NLP). Transcriptomic data is neither—it is discrete (count-based), sparse (mostly zeros), and orderless (genes have no natural sequence).
- The Scalability Bottleneck: Modeling the whole transcriptome (~20,000 genes) is computationally explosive for standard attention mechanisms, forcing researchers to filter only for "highly variable genes," thus losing critical biological context.
Methodology: The Architecture of Lingshu-Cell
Lingshu-Cell addresses these via a bidirectional Transformer backbone powered by a Masked Discrete Diffusion process.
1. Mask-and-Predict Paradigm
Instead of adding Gaussian noise, the model randomly "masks" gene expression tokens. In the reverse process, the model predicts the original quantized expression levels. This naturally fits the permutation invariance of genes—the model learns the regulatory "context" of a gene regardless of its position in a list.
2. Embedding-Space Compression
To handle 18,000+ genes, the authors introduced a sequence compression module. It groups gene embeddings and projects them into a lower-dimensional latent space for Transformer processing, then "decompresses" them for final prediction. This allows for whole-transcriptome modeling without the quadratic memory cost.
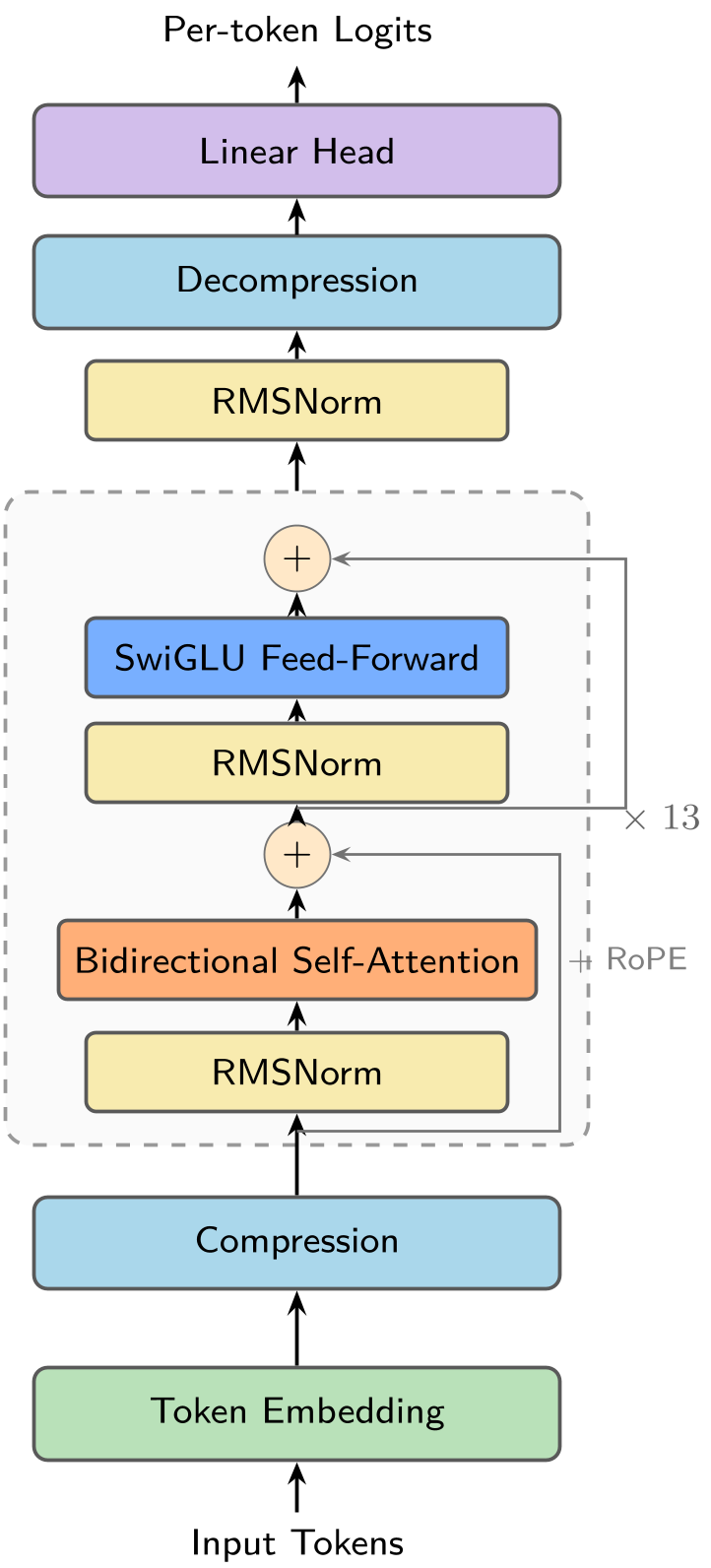 Figure 1: The Lingshu-Cell framework featuring the compression/decompression pipeline and the bidirectional Transformer backbone.
Figure 1: The Lingshu-Cell framework featuring the compression/decompression pipeline and the bidirectional Transformer backbone.
3. Steered Conditional Generation
For perturbations (e.g., "What if we knock out gene X?"), the model uses Classifier-Free Guidance (CFG). It computes the difference between a "control" state and a "perturbed" state, pushing the generated distribution toward the unique signature of that perturbation.
Experiments: Leading the Virtual Cell Challenge
Lingshu-Cell was benchmarked on the Virtual Cell Challenge (VCC) H1 dataset, a "Turing test" for cellular modeling.
- SOTA Performance: It achieved the best average rank across seven metrics, specifically excelling in Pearson-Δ correlation (capturing the direction/magnitude of change) and Mean Absolute Error (MAE).
- Generalization: Remarkably, the model generalized from genetic knockouts to cytokine perturbations in PBMCs, proving it can model different biological "languages" (signaling vs. direct genetic manipulation).
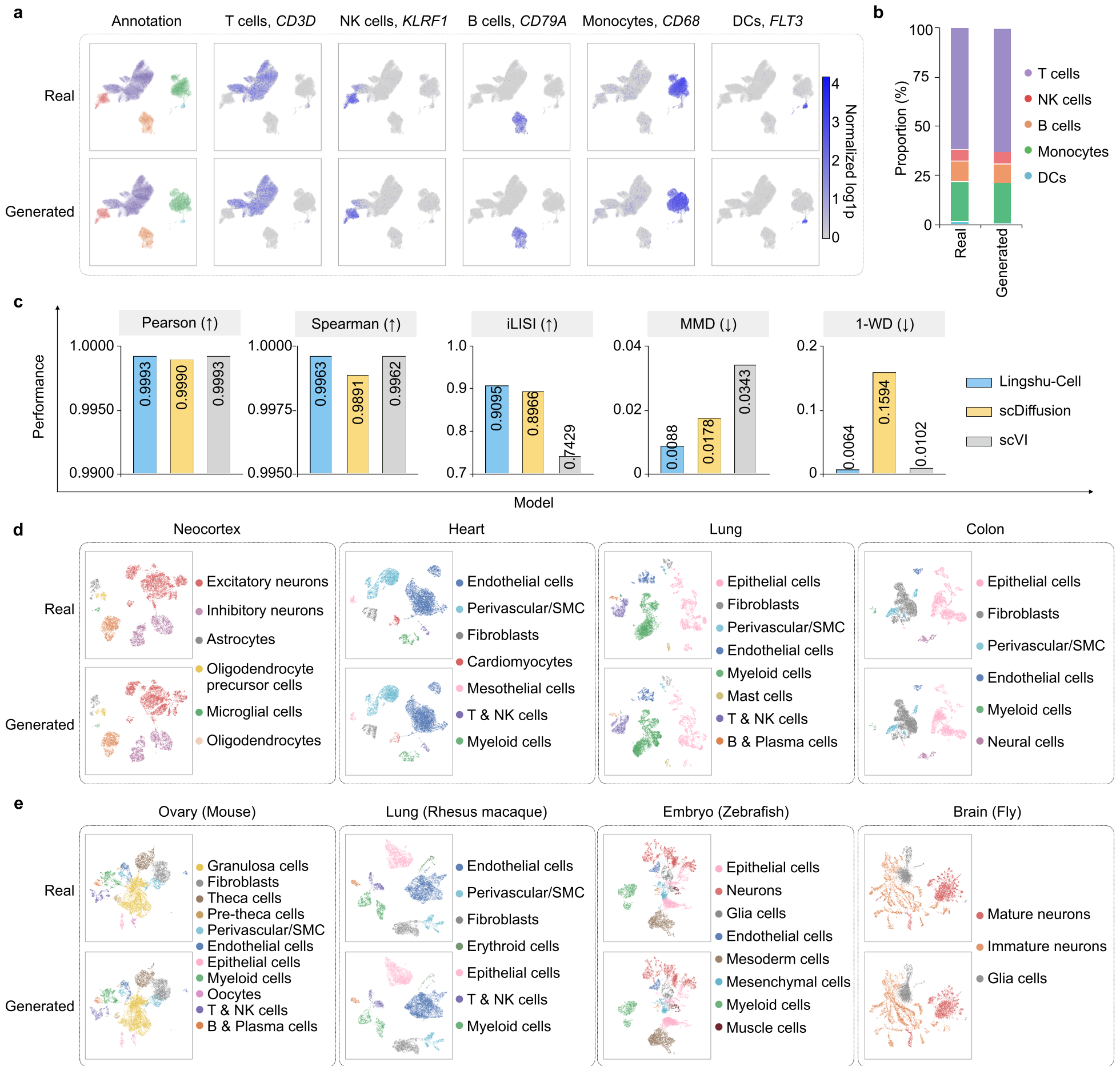 Figure 2: Qualitative and quantitative results showing Lingshu-Cell's ability to replicate real cell-type distributions and marker gene patterns.
Figure 2: Qualitative and quantitative results showing Lingshu-Cell's ability to replicate real cell-type distributions and marker gene patterns.
Critical Analysis & Conclusion
The core "Insight" of Lingshu-Cell is its Inductive Bias alignment. By choosing a discrete, masked approach, the authors respected the "physicality" of RNA sequencing.
Limitations:
- Causality vs. Correlation: While it hallucinates realistic distributions, does it truly understand the underlying gene regulatory networks (GRNs)? High-fidelity simulation is not always a proxy for causal understanding.
- Modality: It currently only "speaks" Transcriptomics. A true world model would need Epigenomic (ATAC) and Proteomic data to be complete.
Takeaway: Lingshu-Cell effectively transitions single-cell AI from "descriptive" to "predictive." It provides a platform where we can screen thousands of drug or genetic combinations in silico, potentially saving years of laboratory work in drug discovery and therapeutic mapping.